애플이 발매한 "iPhone 8/8 Plus/X"는 반도체 칩의 측면에서 보면 중요한 이정표가 된다. 프로세스 기술과 프로세서 코어 아키텍처가 모두 쇄신됐기 때문이다.
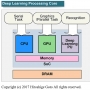
iPhone 8/8 Plus/X의 심장부로 애플이 개발한 새로운 모바일 SoC(System on a Chip) "A11 Bionic"의 프로세스 기술은 미세화 된 10nm 노드다. SoC 내의 프로세서 코어는 GPU 코어에 애플이 자체 개발한 마이크로 아키텍처가 탑재 되었으며 또한 독자 개발로 보이는 뉴럴 네트워크 처리 코어 "Neural Engine"이 추가됐다.
10nm에서 뉴럴 네트워크 프로세서를 탑재한 A11
3가지 포인트를 정리하면 우선 iPhone 6s/7세대의 16/14nm프로세스에서 2년만에 프로세스 세대가 바뀌었다.
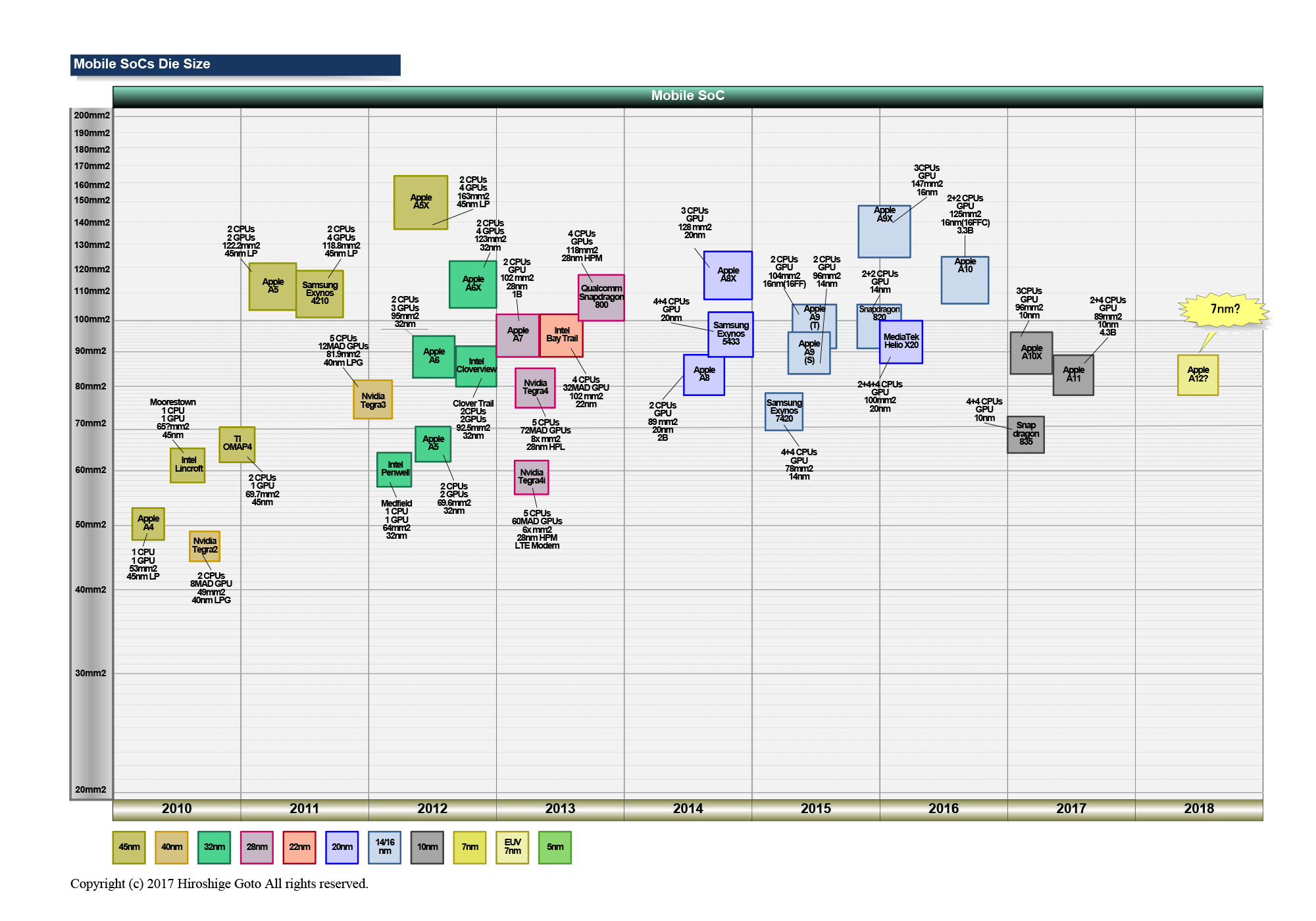
탑재 트랜지스터 수는 4.3B(43억)로 다이 사이즈는 90mm2 이하로 축소됐다. 외관상은 과거 무어의 법칙대로 2년만에 노드의 숫자가 1세대 앞선 70%.
실제로는 트랜지스터의 스케일링으로 보면 면적으로 50%(리니어 70%) 축소에 3년이 걸렸다. 어쨌든 프로세스의 미세화에 의해 칩에 들어가는 트랜지스터 수가 늘고 아키텍처의 확장의 여지가 증가했다.
A11은 증가된 트랜지스터를 사용하고, 아키텍처의 확장이 진행됐다. 아키텍처의 핵심은 애플이 자체 설계화를 진행한 것. GPU 코어는 기존의 Imagination Technologies의 PowerVR 계열 GPU 코어에서 자체 개발한 GPU 코어로 교체됐다. 자사의 정책에 따른 코어를 자사가 개발하지 못하면 안된다고 생각하고 있는 것으로 보인다. 참고로 CPU 코어는 ARM의 IP에서 완전히 재설계한 싱글 스레드 성능이 높은 자사 아키텍처로 바뀌고 있다.
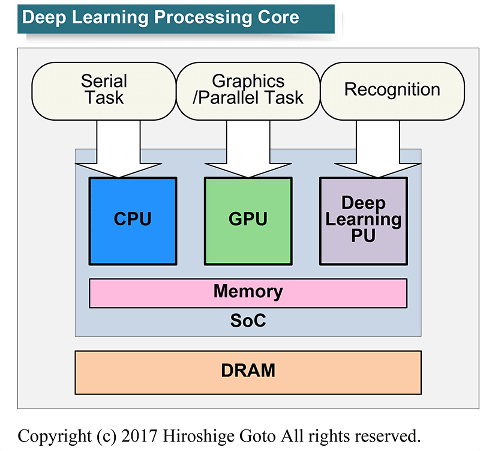
A11의 3번째 중요한 점은 CPU/GPU와 함께 "딥 러닝 프로세싱 유닛(Deep Learning Processing Unit:DLPU)"을 탑재한 것. 모바일 SoC는 딥 러닝용 뉴럴 네트워크(NNA) 실장으로 향하고 있다. 아마 몇년 안에는 많은 클라이언트 컴퓨팅 칩에 3번째 프로세서 코어로 DLPU가 탑재될 것이며 애플은 여기서도 선두 그룹에 있다. 추론을 위한 뉴럴 네트워크 프로세서는 데이터 밀도를 낮출 수 있기 때문에 연산 배열을 상대적으로 줄일 수 있다.
그러나 추측이 맞다면 이 NNA는 온 다이 웨이트(무게) 데이터 버퍼를 상당량 싣고 있어 어느 정도의 다이(반도체 본체) 지역을 필요로 한다. 10nm화에 의한 트랜지스터의 증가는 이 프로세서의 탑재를 용이하게 하고 있다고 보인다. 프로세스의 쇄신에 맞추어 아키텍처 면에서도 비약한 것이 A11이다.
A11 Bionic의 제조 프로세스는 TSMC의 10nm "10FF"
애플은 올해(2017년) 6월 새로운 iPad Pro의 SoC "A10X"를 TSMC의 10nm공정으로 제조하고 있다. 10nm제조 라인은 상당한 볼륨을 확보하고 있다고 보이며 이번에도 애플 이외의 고객에게 제공되는 10nm 초기 라인은 한정되고 있다고 한다.
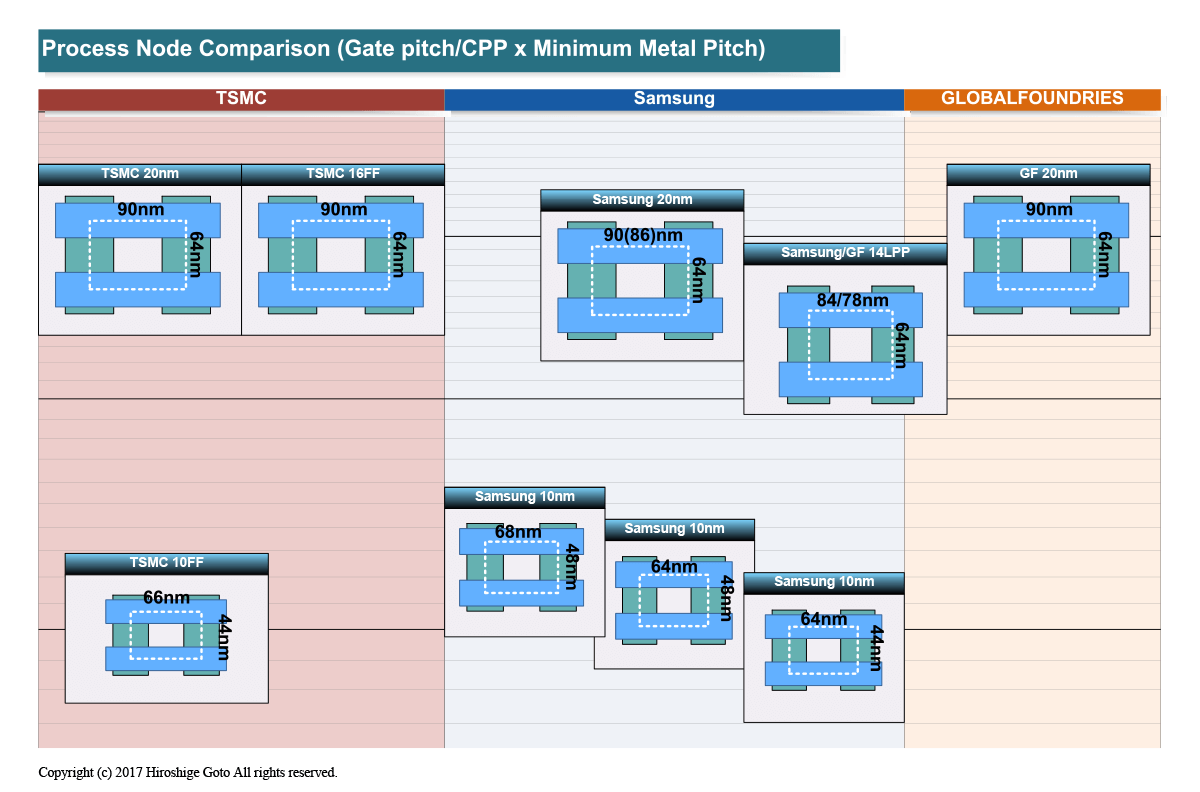
TSMC의 10FF는 꾀 "채운" 프로세스가 되고 있어 삼성전자의 16nm공정과 비교하여 사이즈(게이트 피치×미니멈 메탈 피치)는 50% 정도 미세화되고 있다. 무엇보다 애플의 발표에 따르면 A11의 트랜지스터 수는 4.3B(43억)로 전 세대 A10의 3.3B(33억)에 비해 30% 정도밖에 늘어나지 않았다. 트랜지스터 증가의 이점은 희박해 보인다.
그러나 A10은 다이 사이즈(반도체 본체의 면적)을 125mm2 정도로 늘리고 트랜지스터 수를 늘렸고 그 만큼 제조 비용이 높은 칩이었다. 반면 이번 A11은 Techinsights의 보고서에 따르면 다이 지역은 87.66mm2로 A10과 비교해 40% 정도 소형화되고 있다. 퍼포먼스 레인지의 모바일 SoC 다이(반도체 본체)의 기준이며 100mm2 이하의 사이즈가 되고 있다.
파운드리 프로세스 기술과 애플 SoC
애플의 A 시리즈 SoC는 20nm의 A8(2014년)에서 20억 트랜지스터가 된 뒤 A10에서 33억까지 완만하게 트랜지스터 수가 증가했다. 20LPM으로 89mm2 A8의 20억과 16FFC에서 125mm2 A10의 33억을 보면 트랜지스터의 평균 밀도는 17% 밖에 높아지지 않았다.
이는 파운드리의 트랜지스터 사이즈가 20nm에서 16/14nm으로 거의 수축하지 않았기 때문이다. 프로세스 노드 숫자는 20에서 16/14로 줄고 있지만 트랜지스터의 크기 기준이며, 게이트의 간격인 게이트 피치(Gate Pitch)와 배선의 간격인 메탈 피치(Metal Pitch)는 대부분 작지 않다.
그래서 Apple은 A8→ A9→ A10에서 다이 사이즈를 늘림으로써 트랜지스터 수를 늘리고 기능을 높여 왔다. A8의 89mm2에서 A9에서는 96/104mm2로, A10은 125mm2로 기존의 태블릿 전용 다이 사이즈에 가까운 사이즈까지 확대했다.
비용적으로 무리를 해도 칩을 대형화함으로써 매년 기능 향상을 실현한 것이 과거 2년간의 애플이였다. 참고로 애플은 그 이전의 A6→ A7→ A8 이행에서는 다이 사이즈를 89mm2부터 102mm2로 퍼포먼스 모바일 SoC의 표준적인 사이즈로 유지하면서 트랜지스터 수를 늘리고 있다. 이는 프로세스가 32nm→ 28nm→ 20nm으로 미세화되고 트랜지스터도 작아졌기 때문이다.
즉 트랜지스터가 매년 작아지고 있던 2012~2014년 다이 사이즈를 작게 담아 트랜지스터 사이즈가 크게 달라지지 않았고, 2014~2016년은 다이 사이즈가 대형화했다. 파운드리의 프로세스 이행에 의해 큰 영향을 받고 있는 것이다.
다이 사이즈가 소형화되도 비용이 떨어지지 않는 A11
이번 A11에서 애플은 10nm로 전환함으로써 다이를 대폭 소형화했다. 과거 2년과 달리 다이는 축소됐다.
그러나 칩 제조 원가는 이번에 다이 사이즈에 비례해 떨어지지 않는다. 이는 16/14nm프로세스보다 10nm프로세스가 제조 프로세스가 크게 복잡해져 과정이 끝난 웨이퍼의 비용이 올라가기 때문이다.
실제로 IHS Markit이 발표한 iPhone 8의 비용 분석 보도 자료를 보더라도 A11의 비용은 27.5달러로 추정되어 iPhone 7세대 A10의 추정 비용으로 26.9달러에서 거의 바뀌지 않았다.
10nm는 노광 공정에서 멀티 패터닝의 레이어가 늘면서 멀티 패터닝 기술 자체도 복잡해진다. 마스크들이 늘어나는 스루풋은 떨어지고 같은 다이 사이즈라도 종전보다 코스트가 올라간다. 반대로 말하면 애플은 10nm의 A11에서 다이를 줄이지 않으면 비용적으로 맞지 않았다. 이 사정은 타사도 마찬가지로 10nm프로세스 세대의 모바일 SoC는 당분간 다이 크기가 줄어들 것으로 예상된다.
이번 10nm프로세스로의 이행에서는 수율, 스피드, 수량의 문제가 반도체 업계 내에서 소문이 퍼졌다. 삼성의 양산 단계 10nm프로세스와 비교하면 TSMC 쪽이 세운 프로세스로써 그만큼 난이도 훨씬 높기 때문이다.
참고로 TSMC 등 파운드리들의 프로세스 로드맵에는 내년(2018년)은 액침 7nm프로세서(삼성은 8nm이라 부른다)의 양산이 시작된다. 그러나 액침노광 기술판 7nm는 프로세스가 더 복잡해지기 때문에 웨이퍼의 처리 비용이 치솟는다. 애플이 다음 A12에 액침 7nm을 사용할지는 비용면을 고려할때 불 분명하지만 업계의 소문은 7nm으로 알려졌다.
또한 그 다음 큰 브레이크 스루가 되는 EUV 노광 기술판 7nm프로세스의 양산은 EUV 노광 장치의 가용성 문제부터 2019년의 타이밍이다. 즉 A13세대.
TSMC의 강점 중 하나는 패키지 기술
애플의 A11은 전 세대의 A10과 같이 칩 패키지에 "Fan-Out Wafer Level Package(FO-WLP)"기술을 채택하고 있는 것으로 보인다.
TSMC의 FOWLP 기술은 "InFO WLP(Integrated Fan-Out Wafer-Level Package)"로 불린다. 애플의 FO-WLP 채용은 반도체 기술적으로는 큰 혁신으로 A10이라고 하는 칩의 큰 특징이었다.
기존 SoC와 프로세서의 패키지와 달리 FO-WLP는 유기 기판을 사용하지 않는다. 그 대신 얇은 "Redistribution Layer(RDL)"로 패드를 전개한다. 패키지의 두께(Z)가 얇아지고 배선 저항이 줄어 I/O 성능이 높아지고 소비 전력도 절감된다. TSMC는 InFO-WLP 기술로 패키지의 두께를 20% 줄이고 I/O 속도를 20% 향상, 10%의 열 저감을 실현한다고 설명했다.
InFO 같은 새로운 패키지 기술은 성능과 전력에서 좋은 부문이 많지만 패키지에 특수한 기술이 필요하다. 또 웨이퍼 수준에서 패키지를 하기 때문에 실리콘 파운드리의 기술이며 제조를 위한 툴(기기)등도 새로 개발해야 한다. 즉, 기술의 시작에 막대한 비용이 필요하다.
그러나 TSMC는 애플이 처음 InFO를 채용했기 때문에 InFO 기술을 안전하게 확장시킬 수 있었다. 결과적으로 애플은 칩을 패키지 기술 수준에서 성능과 전력 효율을 높일 수 있었다. TSMC 측은 처음부터 큰 볼륨으로 InFO가 출범되어 InFO 팹에 대한 투자의 감가상각을 추진할 수 있었다.
그리고 TSMC는 패키지의 특수성에 의해 애플을 자사의 고객으로 고정시키는 것이 쉽게 됐다. 16/14nm로 이행한 A9에서 애플은 양산 볼륨의 불안으로 TSMC와 삼성으로 제조를 분산하고 위탁했지만 InFO를 사용하면서부터 10nm 양산에 불안이 있더라도 TSMC에만 의존하는 것으로 예상된다.
출처 - http://pc.watch.impress.co.jp/docs/column/kaigai/1083247.html
 도시바 메모리 사업, 마침내 베인...
도시바 메모리 사업, 마침내 베인...
 서버/하이엔드PC의 주기억을 변혁...
서버/하이엔드PC의 주기억을 변혁...