안녕하세요. SQLER의 코난 김대우입니다.
이번 강좌에서는, Python 머신러닝 강좌 - 3. Pandas 소개를 진행토록 하겠습니다.
예제 노트북 파일 : pandas와 Series와 DataFrame 예제 노트북 파일
SQLER에서 진행되는 전체 Python / 머신러닝 강좌 목록
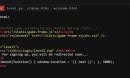
코드를 실행하기 위해서는, vscode에서 새로운 파일을 만들고 강좌 내용을 단계별로 copy&paste해서 실행하시면 됩니다. 또는, Jupyter notebook을 실행하고 단계별로 실행하셔도 됩니다.
예를 들어, 3_pandas.ipynb를 생성하고 vscode에서 실행하면, Jupyter notebook이 실행됩니다.(vscode에서 실행도 가능하며, 웹브라우저에서도 실행 가능합니다.)
또는, github 리포지토리를 clone 하신 후, vscode나 Jupyter notebook에서, 위의 노트북 파일을 열면 됩니다.
상세한 환경 구성이 필요 하시다면, 개발자 커뮤니티 SQLER.com - Python 초급 강좌 목차 - 1. Python 개발 환경 구성 문서를 참조해 WSL, vscode, conda, jupyter notebook 설정을 모두 먼저 완료 하시길 권장해 드립니다.
환경구성 참고링크
개발자 커뮤니티 SQLER.com - Python 초급 강좌 목차 - 1. Python 개발 환경 구성
개발자 커뮤니티 SQLER.com - Python 머신러닝 강좌 - 1. 주피터 노트북(Jupyter Notebook) 구성
개발자 커뮤니티 SQLER.com - Python 머신러닝 강좌 - 2. Anaconda와 Conda 구성
Python 머신러닝 강좌 - 3. Pandas 소개
pandas
pandas 데이터 분석을 수행할 수 있는 여러 데이터 구조(data structure)와 도구가 포함 된 오픈 소스 Python 라이브러리입니다. 머신러닝 작업을 할때 필요한 여러 데이터 전처리 작업을 수행하기에 적절한 거의 모든 기능들을 pandas에서 제공하고 있습니다. 특히, SQLER 분들처럼, DB에 대한 경험이 있고, 쿼리 작성 경험이 있다면, 빠르게 pandas를 익힐 수 있습니다. SQLER의 강좌에서 많은 예제를 차근차근 다룰 예정이고, 기본 머신러닝 시리즈 강좌 외에 pandas와 numpy 상세 시리즈 강좌도 진행 예정이니, 많은 도움 되시길 바랍니다.
pands는 두가지의 데이터 개체로 나뉩니다. "Series"와 "DataFrame" 입니다.
pandas Series와 DataFrame
bash 쉘에서 아래 pip 명령을 이용해 pandas를 설치 가능합니다.
1 | pip install pandas |
(conda 환경을 activate 했는지 다시 체크하세요. 현재 pands를 설치하는 conda 환경에서만, padnas를 사용 가능합니다.)
pandas Series
pandas Series는 1차원 배열을 저장 가능하고 Python list와 유사합니다.
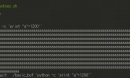
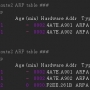
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import pandas as pdairports = pd.Series([ 'Seattle-Tacoma', 'Dulles', 'London Heathrow', 'Schiphol', 'Changi', 'Pearson', 'Narita' ])# 노트북을 사용할 때 print 문을 사용할 수 있습니다.# print(airports) 으로 변수 내용을 출력, 검사 할 수 있습니다.# 또는 개체 이름을 셀에 입력하여 화면에 값을 출력 할 수 있습니다.airports |
실행하면, series 데이터가 출력된 것을 보실 수 있습니다.
(혹시, module을 찾을 수 없음 오류가 발생할 경우, conda 환경을 activate 하셨는지 체크하시고, jupyter나 vscode의 실행환경이 위의 pip를 설치한 conda 환경과 일치하는지 다시 한번 체크하세요. - conda 환경 구성 문서 참조)
index를 사용하여 Series의 개별 값을 참조 가능합니다.
1 | airports[2] |
Loop를 사용해 Series 의 모든 값을 iterate 할 수 있습니다.
1 2 | for value in airports: print(value) |
Series는 이렇게 list와 유사합니다. 일반적으로 list나 dict 처리 후 이렇게 Series로 데이터를 처리한 다음, DataFrame에 merge할때 자주 사용합니다. 이렇게 여러개의 1차완 배열 형태인 Series가 모여서 2차원 배열 형태인 DataFrame이 됩니다.
DataFrame
pandas로 작업 할 때, 대부분의 경우 2 차원 배열을 다루게 됩니다. Pandas ** DataFrame **은 2 차원 array를 저장할 수 있습니다.
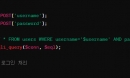
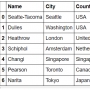
1 2 3 4 5 6 7 8 9 10 11 | airports = pd.DataFrame([ ['Seatte-Tacoma', 'Seattle', 'USA'], ['Dulles', 'Washington', 'USA'], ['London Heathrow', 'London', 'United Kingdom'], ['Schiphol', 'Amsterdam', 'Netherlands'], ['Changi', 'Singapore', 'Singapore'], ['Pearson', 'Toronto', 'Canada'], ['Narita', 'Tokyo', 'Japan'] ])airports |
columns 파라미터를 사용하여 DataFrame을 만들 때 column의 이름을 지정 가능합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 | airports = pd.DataFrame([ ['Seatte-Tacoma', 'Seattle', 'USA'], ['Dulles', 'Washington', 'USA'], ['London Heathrow', 'London', 'United Kingdom'], ['Schiphol', 'Amsterdam', 'Netherlands'], ['Changi', 'Singapore', 'Singapore'], ['Pearson', 'Toronto', 'Canada'], ['Narita', 'Tokyo', 'Japan'] ], columns = ['Name', 'City', 'Country'] )airports |
실행결과

이렇게 처음으로, pandas로 Series와 DataFrame을 만들고 조회하는 방법에 대해서 살펴 보았습니다.
실제 이렇게 DataFrame을 직접 만들기 보다는 외부 데이터 소스(CSV 파일이나 SQL과 같은 DBMS)로부터 가져오는 경우가 더 많죠. 아울러, 단순 처리가 아니라, SQL쿼리만큼 다양하고 유연한 기능을 pandas가 제공합니다.
이후 강좌에서 더 많은 내용을 다룰 예정이니, 많은 도움 되시길 바랍니다.
참고자료
pandas - Python Data Analysis Library (pydata.org)
개발자 커뮤니티 SQLER.com - Python 무료 강좌 - 기초, 중급, 머신러닝
개발자 커뮤니티 SQLER.com - Python 초급 강좌 목차 - 1. Python 개발 환경 구성
개발자 커뮤니티 SQLER.com - Python 머신러닝 강좌 - 1. 주피터 노트북(Jupyter Notebook) 구성
개발자 커뮤니티 SQLER.com - Python 머신러닝 강좌 - 2. Anaconda와 Conda 구성
출처 - https://www.sqler.com/board_MachineLearning_AI_tip_lecture/1096225
 Python 머신러닝 강좌 - 4. Panda...
Python 머신러닝 강좌 - 4. Panda...
 Python 머신러닝 강좌 - 2. Anaco...
Python 머신러닝 강좌 - 2. Anaco...