GPU 컴퓨팅 또는 GPGPU는 과학 및 엔지니어링 컴퓨팅의 일반적인 목적에 그래픽 처리 장치(GPU)를 사용하는 것을 말합니다.
GPU 컴퓨팅 모델은 이질적인 공동 프로세싱 컴퓨팅 모델에 CPU와 GPU를 함께 사용하는 것입니다. 어플리케이션의 순차적 부분은 CPU에서 실행하고, 계산 집약적인 부분은 GPU를 통해 보다 빠르게 처리됩니다. 사용자 관점에서는 GPU가 성능을 크게 향상시켜 주기 때문에 더욱 향상된 어플리케이션성능을 경험하게 됩니다.

GPU는 지난 수년 간에 걸쳐 빠르게 발전하였으며 현재 수 테라플롭 부동 소수점의 성능을 발휘하는 단계에 이르고 있습니다. NVIDIA는 GPGPU의 혁신을 이끌어 왔으며, 지난 2006~2007년 “CUDA”라는 새로운 대규모 병렬 아키텍처를 도입함으로써 컴퓨팅 업계의 엄청난 발전에 기여하고 있습니다. CUDA 아키텍처는 수백 개의 프로세서 코어로 구성되어 있으며, 이들 코어가 함께 작동함으로써 어플리케이션 데이터 셋을 경이로운 속도로 처리합니다.
지난 수년 동안 GPGPU의 비약적인 발전을 통해 CUDA 병렬 프로그래밍 모델을 이용한 프로그래밍도 훨씬 용이해졌습니다. 이 프로그래밍 모델을 통해 어플리케이션 개발자는 계산 집약적 커널을 GPU에 매핑하도록 어플리케이션을 수정할 수 있습니다. 어플리케이션의 일부는 CPU에서 처리됩니다. 함수를 GPU에 매핑하려면 함수에서 병렬 처리가 가능하도록 함수를 새롭게 작성하고 “C” 키워드를 추가하여 데이터를 GPU로 전달해야 합니다. 개발자는 수천 개의 쓰레드 가운데 수십 개의 쓰레드를 동시에 실행시켜야 합니다. GPU 하드웨어가 이러한 쓰레드를 관리하고 스케줄링을 진행합니다.
Tesla 20 시리즈 GPU는 최신 CUDA 아키텍처인 “페르미(Fermi)”를 기반으로 하고 있습니다. 페르미는 500기가플롭 이상의 IEEE 표준 2배 정도 부동 소수점 하드웨어 지원, L1 및 L2 캐시, ECC 메모리 오류 보호, GPU 전반에 걸쳐 분산된 공유 메모리 형태의 로컬 사용자 관리 데이터 캐시, 집합적 메모리 액세스 등 주요한 기능들을 포함하고 있으며 과학 어플리케이션에 최적화되어 있습니다.
Jack Dongarra 교수
이노베이티브 컴퓨팅 연구실 책임자
The University of Tennessee
GPU 컴퓨팅의 역사
그래픽 칩은 고정된 기능의 그래픽 파이프라인으로부터 시작되었다. 이후, 이러한 그래픽 칩들이 점점 더 프로그래밍할 수 있게 되면서, 엔비디아가 최초의 GPU (Graphics Processing Unit)를 발표하게 되었다. 1999년에서 2000년경에는 전자기학 및 의료 이미징과 같은 분야의 연구원들 그리고 특히 컴퓨터 과학자들이 다용도의 컴퓨팅 애플리케이션을 구동하는 데 GPU를 사용하기 시작했다. 이들은 GPU의 뛰어난 부동소수점 성능이 광범위한 과학 애플리케이션들의 성능을 높인다는 사실을 알게 되었으며, 이것이 GPU를 통한 일반 목적의 컴퓨팅을 일컫는 ‘GPGPU’ (General Purpose computing on GPU)의 시작이 되었다.
문제는 GPGPU에서 GPU를 프로그래밍 하기 위해서는 OpenGL이나 CG와 같은 그래픽 프로그래밍 언어를 사용해야 된다는 점이었다. 개발자들은 과학 애플리케이션을 그래픽 애플리케이션처럼 보이게 하기 위해, 삼각형과 폴리곤을 그리는 맵핑 작업을 해야 했으며, 이는 과학계가 GPU의 뛰어난 성능을 누리는데 상당한 제약이 되었다.
엔비디아는 이러한 성능이 보다 다양한 과학분야에 가져다 줄 수 있는 이점과 그 잠재력을 간파하여, 과학 애플리케이션 및 C, C++ 와 Fortran같은 고급언어의 추가지원을 위해 완전히 프로그래밍화 할 수 있도록 GPU를 변환하는데 투자하기로 결정했다. 이러한 노력 끝에 GPU를 위한 CUDA 아키텍처가 탄생하게 되었다.
CUDA 병렬 아키텍처 및 프로그래밍 모델
CUDA 병렬 하드웨어 아키텍처는 태스크 병렬뿐 아니라 미세하게 그레인화 (grained) 되었거나 개략적으로 그레인화된 데이터를 표현하는 abstraction을 제공하는 CUDA 병렬 프로그래밍 모델을 동반한다. 프로그래머는 C, C++, Fortran과 같은 고급언어 또는 OpenCL™, DirectX-11 Compute와 같은 드라이버 API를 선택하여 병렬표현 할 수 있다.

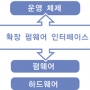
NVIDIA는 현재 C, C++, Fortran, OpenCL 및 DirectCompute를 이용한 GPU 프로그래밍을 지원합니다. 개발자는 위 그림에 나타나 있는 것처럼 라이브러리 및 미들웨어와 함께 다양한 소프트웨어 개발 도구를 이용할 수 있습니다(참조).
CUDA 병렬 프로그래밍 모델은 프로그래머들이 문제(problem)를 개략적인 하위 문제로 분할할 수 있도록 한다. 이에 따라, 하위문제에서의 미세 그레인 병렬화는 각각의 개별 하위문제가 협동 병렬로 해결될 수 있도록 표현된다.
OpenCL™는 애플사의 상표이며 크로노스 그룹이 배포한 OpenCL™을 사용하고 있습니다.
DirectX는 Microsoft의 등록상표입니다.
NVIDIA® CUDA™ 병렬 컴퓨팅 아키텍처는 GeForce®, Quadro®, Tesla™ 제품에서 지원합니다. GeForce와 Quadro는 각각 소비자용 그래픽과 전문 시각화를 위해 개발되었으며, Tesla 제품군은 병렬 컴퓨팅의 기반이 되어 다양한 컴퓨팅 기능을 지원합니다.
Tesla의 장점
| 성능 | 신뢰성 | HPC 솔루션 | |||||||||||||||||||
| 하드웨어 |
|
|
| ||||||||||||||||||
| 소프트웨어 (자세한 내용은 여기를 참조하세요.) |
|
|
|
성능을 고려한 구성
Tesla 제품은 컴퓨팅 전문가를 위해 성능을 극대화할 수 있는 다양한 기능을 포함하고 있습니다.
- 완벽한 이중 정밀 부동 소수점 성능
- Tesla C2050, M2050, S2050 제품에서 515GigaFlops
- 소비자용 제품보다 훨씬 높은 이중 정밀성
- 보다 빠른 PCIe 통신
- 양방향 PCIe 통신을 위해 DMA 엔진 두 개를 장착한 NVIDIA의 유일한 제품군
- 대용량 데이터셋을 포함해 전문 어플리케이션에서 보다 높은 성능 구현
- 대용량 온보드 메모리(3GB 및 6GB)
- NVIDIA GPUDirect™를 통해 InfiniBand와의 통신 속도 향상
- 특수 Linux 패치, InfiniBand 드라이버, CUDA 드라이버
- Windows 운영체제에서 보다 높은 성능을 구현하는 CUDA 드라이버
- TCC 드라이버는 CUDA 커널 오버헤드를 줄이고 Windows 원격 데스크톱과 Windows 서비스 지원
|
|

탁월한 신뢰성
컴퓨팅 전문가는 데이터 오류 없이 신뢰성 있는 작업을 진행해야만 하기 때문에 미션 크리티컬 어플리케이션에 의존합니다. Tesla 제품은 다른 어떠한 NVIDIA 제품보다도 오랜 시간에 걸쳐 가장 까다로운 조건에서 제로 오차 허용 테스트를 거칩니다. Tesla 전용 기능은 다음과 같습니다.
- 데이터 신뢰성을 보장하기 위한 ECC 보호
- GPU 내 메모리 및 외장형 GDDR5 메모리
- 제로 오차 범위의 스트레스 테스트
- 수일에 걸쳐 제작 과정에서 스트레스 테스트 수행
- NVIDIA가 직접 제조하여 품질 보장
- 추가된 메모리 마진 및 코어 클럭을 통한 신뢰성 보장
- 엔터프라이즈 레벨 지원
- 3년 보증을 통해 우선순위에 따른 버그 해결 및 기능 요청 지원을 수행하며, 18~24개월에 이르는 제품 라이프사이클 보장
- ISV 인증
- HPC 소프트웨어 벤더는 Tesla 제품에 한하여 소프트웨어 인증
HPC 솔루션을 위한 구성
HPC 고객은 고유한 요구조건을 가지고 있습니다. Tesla 비즈니스 부서만이 이러한 특별한 요구에 부합하는 제품과 솔루션을 제공할 수 있습니다.
- 통합 OEM 시스템
- Tesla 제품용으로 특별 제작한 혁신적인 OEM 서버 및 블레이드, 워크스테이션
- Tesla 제품의 정기적인 공급 및 가용성
- 18~24개월 가용성 및 라이프사이클
- 데이터 센터 보증
- Tesla 제품에 대한 NVIDIA와 OEM 파트너의 3년 보증
- 클러스터 관리 및 GPU 모니터링 소프트웨어
- GPU 온도 모니터링, 팬 속도, 전력
- 클러스터에서 GPU에 독점 액세스
- HPC 전문업체를 통한 판매 전/후 지원
- CUDA/OpenCL 튜닝 엔지니어, 솔루션 아키텍트, 전담 영업팀이 제공하는 토털 HPC 솔루션 전문 기술지원
위에서 언급한 이점은 대부분 Quadro 제품군에서도 경험할 수 있습니다.