
하바나 가우디2 메자닌 카드
하바나 가우디2 메자닌 카드 이미지 2022년 5월 10일, AI 딥러닝 프로세서 기술에 중점을 둔 인텔의 데이터 센터 팀인 하바나 랩스는 학습 및 추론을 위한 2세대 딥 러닝 프로세서인 하바나 가우디2와 하바나 그레코를 출시했습니다. (크레딧: 인텔)
인텔은 오늘 자사 2세대 하바나® 가우디®2 딥 러닝 프로세서와 엔비디아 A100의 AI 총 학습 시간 (Time-to-Train, 이하 TTT) 성능을 MLPerf 산업 벤치마크 상에서 측정한 결과, 하바나® 가우디®2 딥 러닝 프로세서의 성능이 월등했다고 밝혔다. 인텔은 지난 5월 인텔 비전에서 발표한 가우디 2 프로세서가 비전 (ResNet-50) 및 언어(BERT) 부문에서 뛰어난 TTT를 기록했다고 밝혔다.
“가우디2가 출시 한 달 만에 MLPerf 벤치마크에서 뛰어난 성능을 기록해 매우 기쁘며, 동시에 이러한 결과를 가져올 수 있도록 노력한 팀원에 자부심을 느낀다”며 “인텔은 비전 및 언어 모델 모두에서 동급 최고의 성능을 제공해, 고객에 가치를 제공하고 AI 딥러닝 솔루션 개발을 가속화하도록 지원할 것”이라고 말했다.
산드라 리베라(Sandra Rivera), 인텔 수석부사장 겸 데이터센터 및 AI 그룹 총괄은
인텔 데이터 센터 팀은 하바나 랩스(Habana Labs)의 가우디 플랫폼을 활용해 딥 러닝 프로세서 기술에 중점을 두었으며, 데이터 과학자 및 머신러닝 엔지니어가 학습을 가속화할 수 있도록 지원했다. 아울러, 단 몇 줄의 코드로 새로운 모델을 구축하거나 기존 모델을 이전해 생산성을 높이고 운영 비용을 절감할 수 있도록 구현했다.
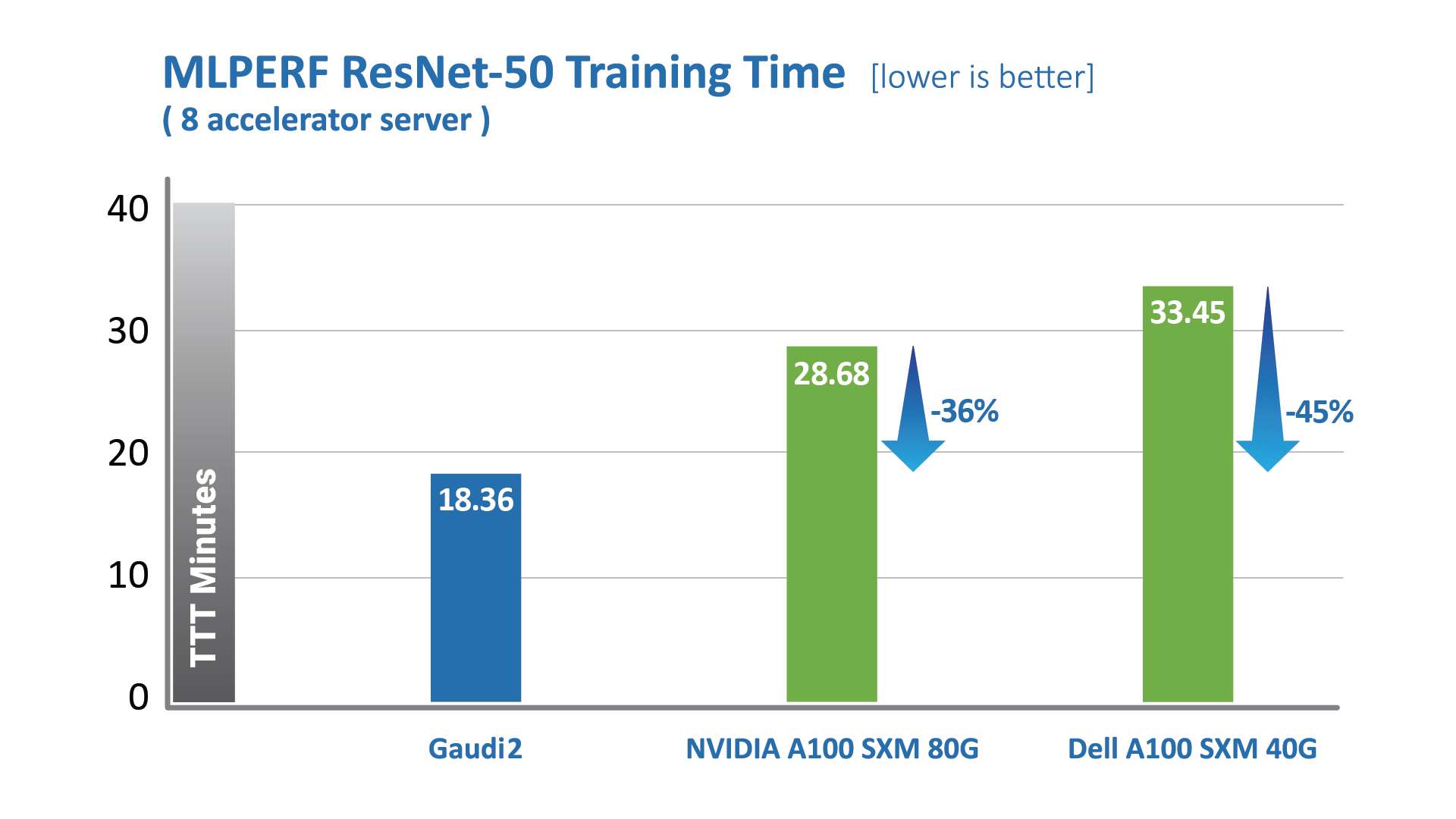
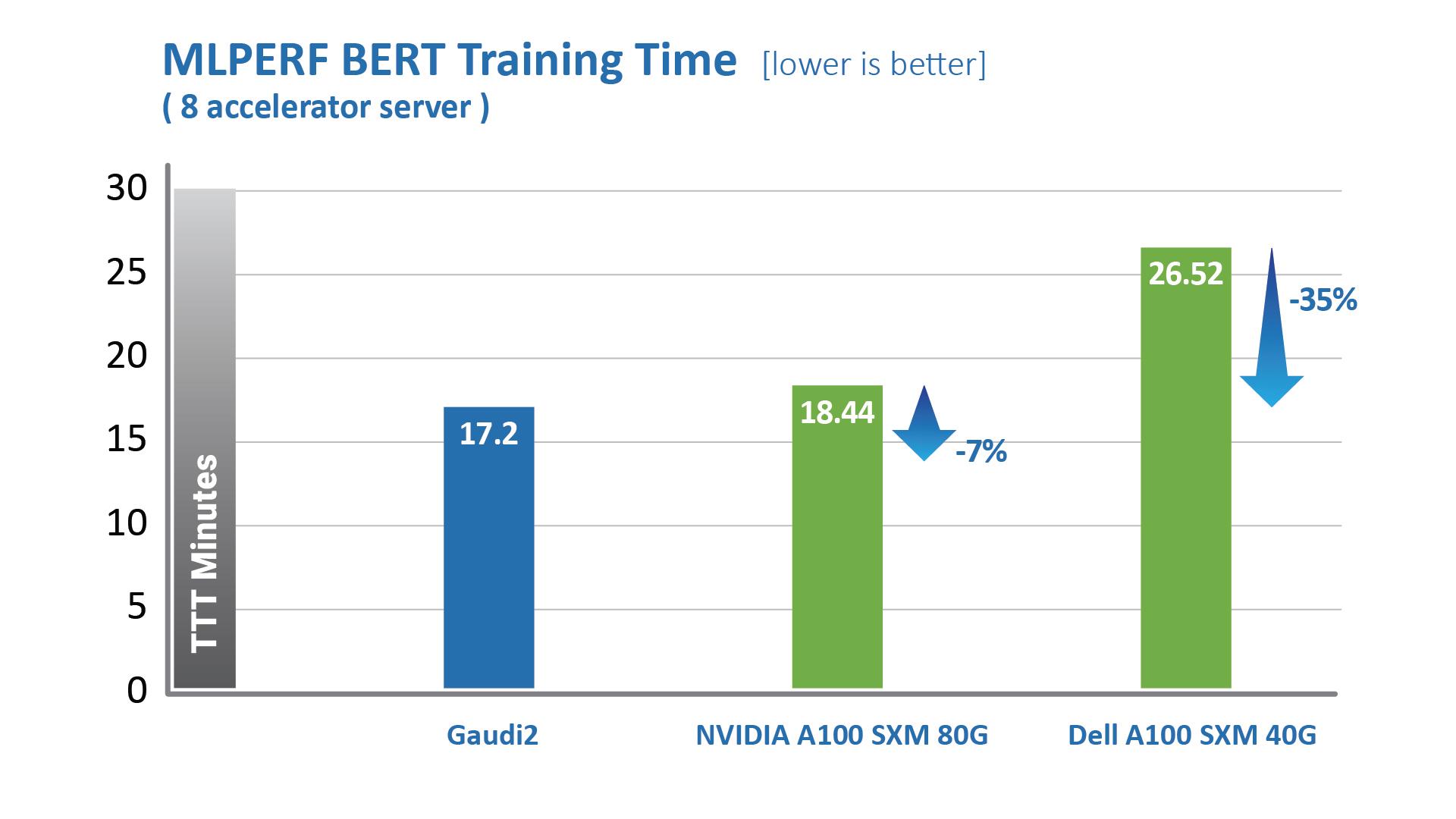
하바나 가우디2는 1세대 가우디 제품 대비 TTT 부문에 있어 획기적인 발전을 이루었다. 하바나 랩스는 지난 2022년 5월 진행한 MLPerf 벤치마크를 통해 가우디2가 8개의 가속기를 사용하는 비전 및 언어 모델에서 엔비디아 A100-80G 대비 월등한 성능을 기록했다고 밝혔다. ResNet-50 모델의 경우, 가우디2는 엔비디아 A100-80G 제품 대비 학습 시간이 36% 단축됐다. 델(Dell)이 진행한 8개의 가속기 서버에서 진행한 ResNet-50 모델 및 BERT 모델 학습 테스트 결과 가우디2가 엔비디아 A100-40GB 대비 학습 시간을 45% 단축했다.
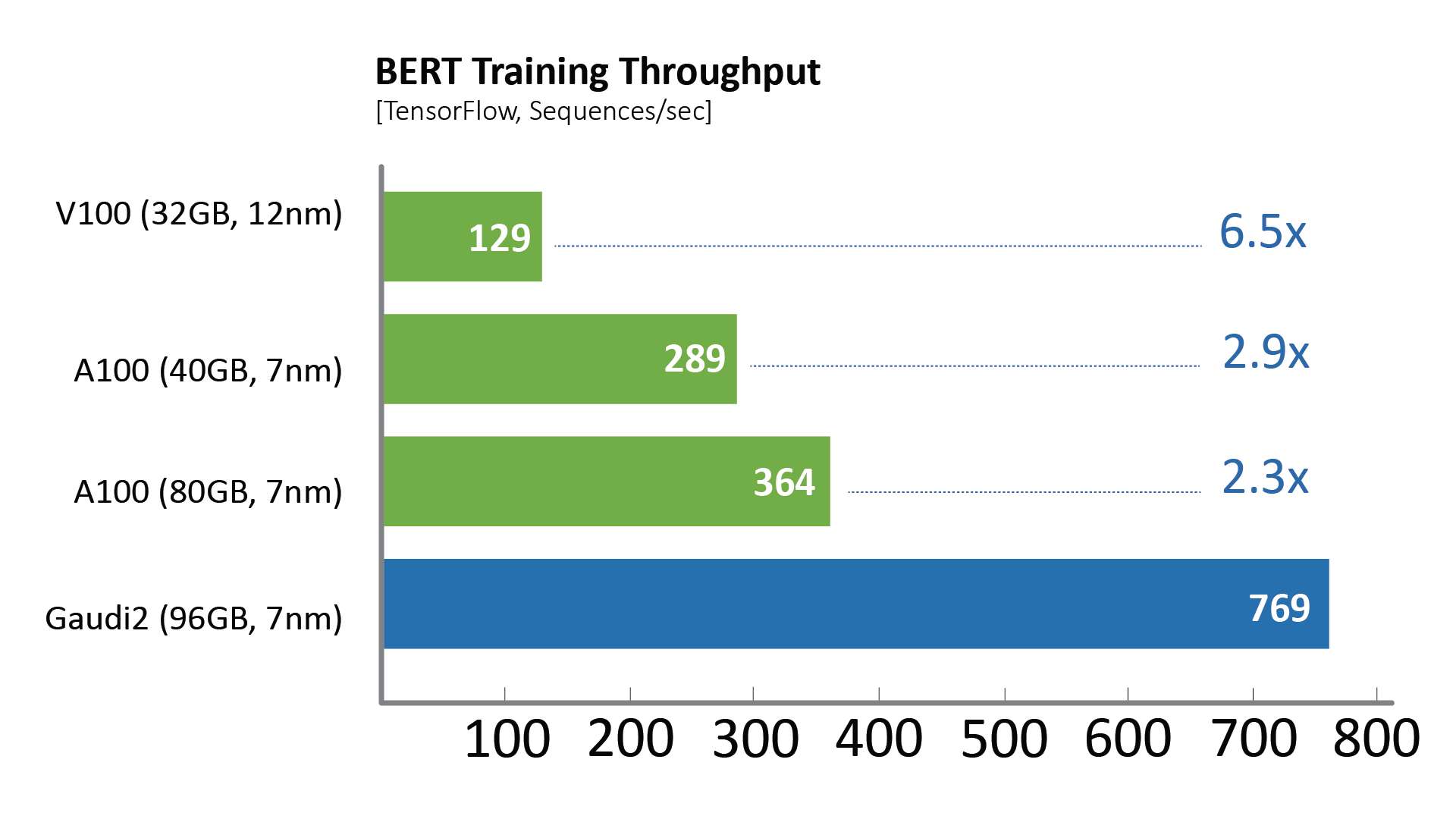
가우디2 RES BERT 그래프
가우디 BERT 시간
MLCommons에서 발표한 지표, 2022년 6월, https://mlcommons.org/en/training-normal-20/
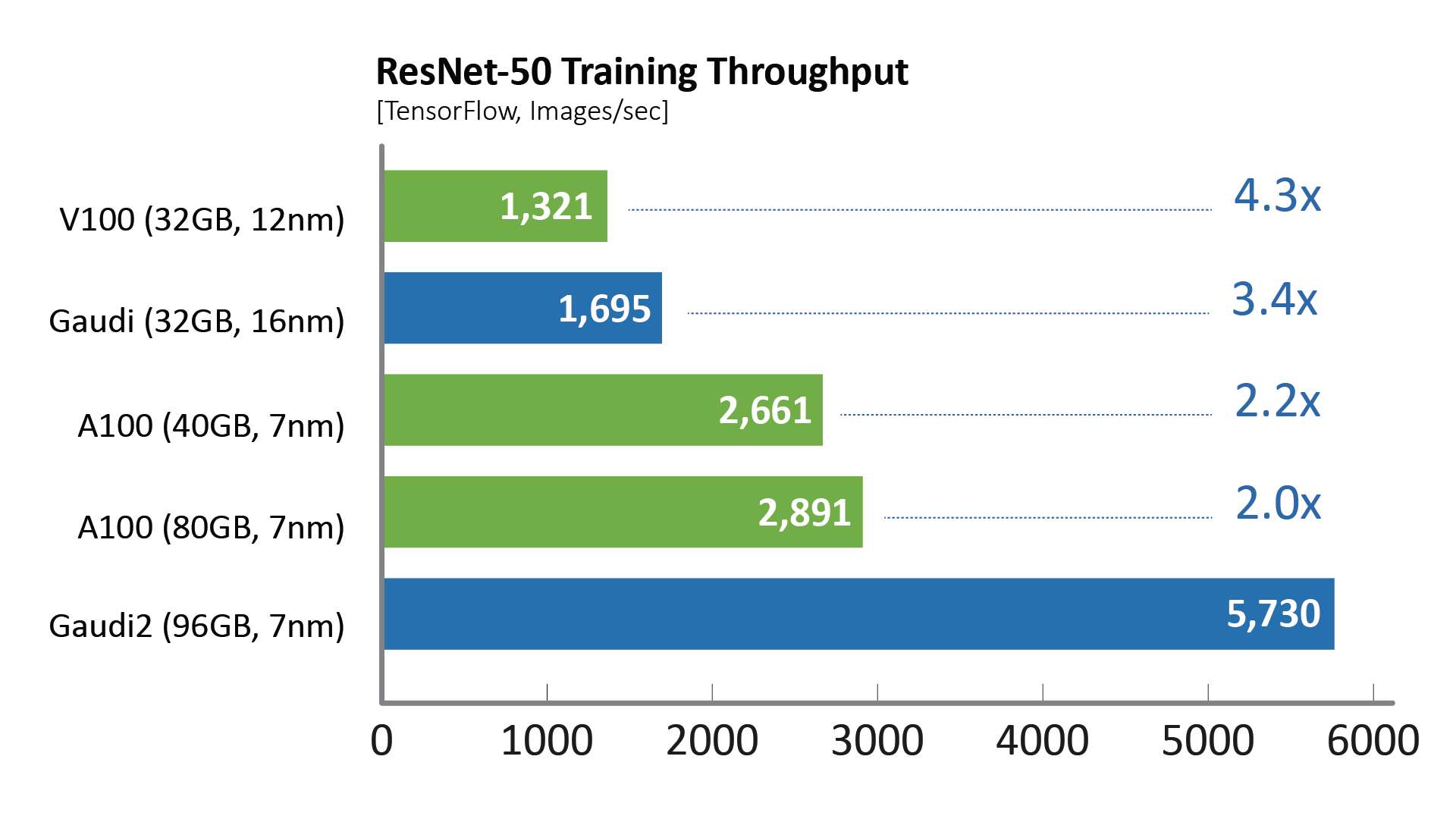
가우디2는 1세대 가우디 대비, ResNet-50 및 BERT 모델에서 각각 3배와 4.7배 높은 학습 처리량을 기록했다. 인텔은 해당 프로세서를 기존 16나노 공정에서 7나노 공정으로 전환해 텐서 프로세서 코어 수를 3배 증가했고, GEMM 엔진 컴퓨팅 용량 증설, 패키지 내 고대역폭 메모리 용량 3배 확대, 대역폭 및 SRAM 크기 2배 확장을 통해 이번 성과를 달성했다. 비전 모델의 경우 가우디2는 독립적으로 작동해 AI 학습에 필요한 데이터 증강을 포함, 압축 영상화를 위한 전반적인 전처리 파이프를 처리할 수 있는 통합 미디어 엔진 형태의 기능을 갖췄다.
가우디1 및 가우디2 프로세서는 특별한 소프트웨어 조작 없이도 고객에게 최고의 성능을 제공한다.
하바나 랩스는 8개의 GPU 서버 및 HLS-가우디2 레퍼런스 서버 상에서 가우디1 및 가우디2와 기존 상용 소프트웨어 간 성능을 비교했다. 학습 처리량은 NGC 및 하바나 공용 저장소의 텐서플로우 도커를 사용해 측정했으며, 제조사에서 권장하는 최고의 성능 매개 변수를 채택했다. 교육 시간 처리량은 결과 교육 시간 수렴에 영향을 주는 핵심 요소입니다.
"The Small Print" 섹션에 제공된 그래픽의 구성을 테스트합니다.
가우디2 RES BERT 그래프
"The Small Print" 섹션에 제공된 그래픽의 구성을 테스트합니다.
가우디2 RES BERT 그래프
"The Small Print" 섹션에 제공된 그래픽의 구성을 테스트합니다.
MLPerf을 통해 측정된 가우디2 제품의 성능 외에도, 가우디1은 고효율 시스템 스케일링을 지원하는 128-가속기 및 256-가속기를 위한 ResNet 모델에서 강력한 성능 및 선형 스케일을 제공했다.
에이탄 메디나(Eitan Medina) 하바나 랩스 최고운영책임자는 “가우디2는 최신 MLPerf 결과로도 입증됐듯이 모델 학습에 있어 업계 선도적인 성능을 제공한다”며 “하바나 랩스는 비용 경쟁력이 높은 AI 학습 솔루션을 제공하기 위해 딥 러닝 교육 아키텍처와 소프트웨어를 지속적으로 혁신하고 있다”고 말했다.
MLPerf 벤치마크에 대하여: MLPerf 공동체는 머신러닝 솔루션에 대해 “정확성, 속도, 효율성에 대한 일관적인 측정치”를 제공하는 공정하고 유용한 벤치마크를 설계하는 것을 목표로 한다. 학계, 연구실, 업계의 AI 분야 리더들이 벤치마크를 결정하고, 모든 공급업체 간 공정한 비교를 보장하는 일련의 엄격한 규칙을 정의해 만들었다. MLPerf 벤치마크는 엔드-투-엔드 작업에 대한 공정한 비교를 가능하게 하는 명시적인 규칙 집합으로 인해 AI 산업에 유일하게 신뢰할 수 있는 벤치마크다. 아울러, MLPerf에 결과를 제출하는 경우, 이를 검증하기 위해 한 달 동안의 동료 검토 프로세스를 거친다.
통지 및 고지사항 :
ResNet-50 성능 비교를 위한 테스트 구성
A100-80GB: NGC의 TF docker 22.03-tf2-py3을 사용하여 단일 A100-80GB를 사용하여 Azure 인스턴스 Standard_ND96amsr_A100_v4에서 Habana가 2022년 4월에 측정했습니다(옵티마이저=sgd, BS=256).
A100-40GB: NGC의 TF 도커 22.03-tf2-py3를 사용하여 단일 A100-40GB를 사용하여 DGX-A100에서 하바나가 2022년 4월에 측정했습니다(옵티마이저=sgd, BS=256).
V100-32GB¬: NGC의 TF 도커 22.03-tf2-py3를 사용하여 단일 V100-32GB를 사용하여 p3dn.24xlarge에서 하바나가 2022년 4월에 측정했습니다(옵티마이저=sgd, BS=256).
가우디2: SynapseAI TF 도커 1.5.0을 사용하여 단일 Gaudi2를 사용하여 가우디2-HLS 시스템에서 하바나가 2022년 5월에 측정(BS=256)
결과는 다를 수 있다.
BERT 성능 비교를 위한 테스트 구성
A100-80GB: NGC의 TF docker 22.03-tf2-py3이 있는 단일 A100-80GB를 사용하여 Azure 인스턴스 Standard_ND96amsr_A100_v4에서 Habana가 2022년 4월에 측정했습니다(Phase-1: Seq len=128, BS=312, accu steps=256; 페이즈-2: 시퀀스렌=512, BS=40, 아큐스텝=768)
A100-40GB: 2022년 4월 하바나가 NGC의 TF 도커 22.03-tf2-py3와 함께 단일 A100-40GB를 사용하여 DGX-A100에서 측정했습니다(Phase-1: Seq len=128, BS=64,
accu 단계 = 1024; Phase-2: seq len=512, BS=16, accu steps=2048)
V100-32GB: NGC의 TF 도커 21.12-tf2-py3가 있는 단일 V100-32GB를 사용하여 p3dn.24xlarge에서 하바나에 의해 2022년 4월에 측정됨(Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=8, accu steps=4096)
가우디2: SynapseAI TF 도커 1.5.0이 있는 단일 가우디2를 사용하여 가우디2-HLS 시스템에서 하바나에 의해 2022년 5월에 측정됨(Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048)
결과는 다를 수 있다.
하바나 연구소. Habana, Habana 로고, Gaudi 및 SynapseAI는 Habana Labs의 상표입니다.
보도 - 인텔
 Meta, 퀘스트 프로(Quest Pro) 발...
Meta, 퀘스트 프로(Quest Pro) 발...
 [체험기] “게이밍에 진심” 오디세...
[체험기] “게이밍에 진심” 오디세...