























’ 오픈")



![[정종철] 뚜따에 진심인 형+과학자코스프레+현미경을구입했어
CPU 뚜따 교육자료ㅋㅋ](https://raptor-hw.net/xe/files/thumbnails/739/203/241x165.crop.jpg "뚜따에 진심인 형+과학자코스프레+현미경을구입했어")










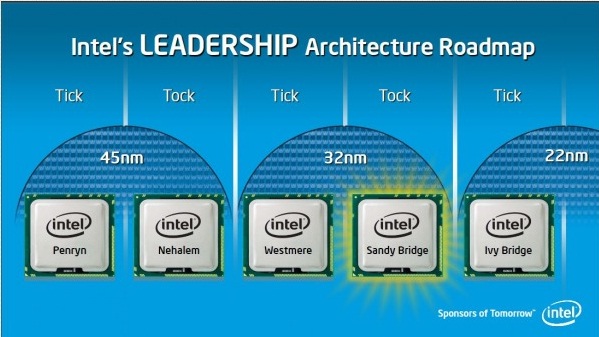
인텔의 Tick - Tock 전략에 따른 차세대 CPU 아키텍처 Sandy Bridge(샌디 브릿지)가 마침내 공개됐다. 인텔은 신형 아키텍처에 대해 매우 높은 자신감을 어필하며 2011년 프로세서 시장에 바로 투입할 예정이다. 따라서 신형 아키텍처의 구조와 특징에 대해 세부적으로 살펴보도록 한다.
신형 Sandy Bridge의 라인업을 보면 클라이언트 PC를 위한 제품은 4코어와 2코어 2가지 버전으로 양쪽 모두 GPU 코어를 내장한다. Sandy Bridge 4코어의 경우 4개의 CPU 코어와 공유 LL캐시(Last Level Cache), 1블럭의 GPU 코어, DDR3 메모리 컨트롤러, PCI Express, DMI 버스, 디스플레이 인터페이스, 그리고 각 블럭을 제어하는 시스템 에이전트를 탑재한다. 공유 LL캐시는 4개의 슬라이스(Slice)에 분할되고 각각의 CPU 코어에 부속되어 있다. 1개의 CPU 코어와 1슬라이스의 LL캐시로 하나의 CPU&캐시 블럭을 구성하고 있다.
Sandy Bridge 아키텍처의 디자인적인 특징은 on-chip 인터커넥트 링버스를 채용하고 있는 점이다. Sandy Bridge 4코어의 경우는 4개의 CPU & 캐시 블럭과 GPU 코어, 그리고 시스템 에이전트가 링버스에 접속되고 있다. 이러한 링은 합계 6스톱으로 4중의 링으로 구성되고 있다.
Sandy Bridge 2코어의 경우는 CPU 코어 & 캐시 블럭이 2개로 감소하지만 링버스를 사용하는 구조는 같다. 링을 사용한 높은 접속성의 설계 적용으로 인텔은 CPU 코어수를 어느 정도 자유롭게 늘릴 수 있으며 4코어와 2코어 2가지 버전 외에 8코어 버전의 제품군(Sandy Bridge-EN/EP/EX)도 준비되고 있다. 상위 8코어 제품군은 GPU 코어를 갖추지 않는 대신 링버스에 8개의 CPU 코어 & 캐시 블럭을 접속하고 있다고 예상된다.

Sandy Bridge CPU 코어의 기본 아키텍처는 네할렘 계열과 같이 코어 마이크로 아키텍처(Core MA)의 발전 계열이다. 그러나 새로운 명령 세트 확장 AVX(Advanced Vector Extensions)의 탑재 등 많은 확장이 이루어지고 있어 상당한 성능 향상이 도모되고 있다. 특별히 눈에 띄는 것은 AVX에 의한 벡터 연산 성능의 향상 뿐만이 아니라 싱글 스레드 성능의 향상에도 힘을 쓰고 있다는 점이다.
CPU 코어로 확장된 포인트는 프론트엔드 클러스터로의 uOP 캐시 추가, 실행 엔진 클러스터에 AVX 유닛의 탑재와 재구성, 물리 레지스터 파일의 이행과 스케줄링 자원 강화, 메모리 클러스터의 로드/스토어 기능 강화로 크게 4가지로 볼 수 있다. 특히 프론트엔드에 추가된 uOP 캐시는 싱글 스레드 퍼포먼스의 향상에 크게 기여한다고 보이며 실행 클러스터와 메모리 클러스터의 강화는 주로 AVX의 벡터 연산 성능에 효과가 있는 것으로 보인다.

인텔은 이러한 마이크로 아키텍쳐 확장을 2가지로 나누고 있다. 첫번째의 마이크로 아키텍처 확장은 그 확장에 의해서 증가하는 전력 이상의 퍼포먼스 향상을 얻을 수 있는 것. 즉, 소비 전력이 10% 증가해도 10% 이상의 퍼포먼스가 향상되는 점이다. 인텔은 Nehalem 설계시 이 원칙을 만들어 전력 효율이 나쁜 아키텍처의 개량은 시행하지 않았다. 결과적으로 Nehalem에서는 전체의 소비 전력당 성능이 1.3배로 성장했다.
두번째의 마이크로 아키텍처 확장은 소비 전력을 줄이면서 퍼포먼스를 끌어올리는 것. 전력을 줄이고 퍼포먼스를 증가시키기 위해 와트당 성능을 크게 끌어 올리는 것으로 Sandy Bridge에서는 두번째의 경우를 더 중요시 한 아키텍처로 볼수 있다.
Sandy Bridge CPU 코어의 확장 중에서 소비전력을 낮추고 퍼포먼스를 끌어올리는데 중요한 점이 프론트엔드의 uOP(마이크로 오퍼레이션) 캐시(uOP Cache)다. 이유는 간단한데 uOP 캐시가 x86 명령의 디코드로 전력과 퍼포먼스 양쪽 모두의 병목현상을 회피할 수 있기 때문이다. 캐시의 후단 실행 엔진이 실행하는 uOPs가 uOP 캐시에 히트했을 경우 uOPs는 캐시로부터 읽어진다. 덩치가 큰 x86 명령 디코더는 아무것도 할 필요없이 sleeve 할 수 있거나 개별 스레드의 명령을 디코드할 수 있다.
실행 클러스터에는 기존의 128-bit 폭의 SIMD(Single Instruction, Multiple Data) 연산 유닛인 SSE 유닛이 추가되고, 256-bit 폭의 AVX 유닛이 탑재됐다. 인텔은 명령 세트를 256-bit 폭으로 확장해도 실행 유닛은 128-bit 폭인 채로 2 cycle throughput으로 AVX 명령을 실행할 수 있었다. 실제로 SSE는 처음에는 이러한 형태를 나타내지 않았으나 AVX는 최초부터 256-bit 폭으로 풀 스피드를 낼 수 있는 실행 유닛을 탑재했다.
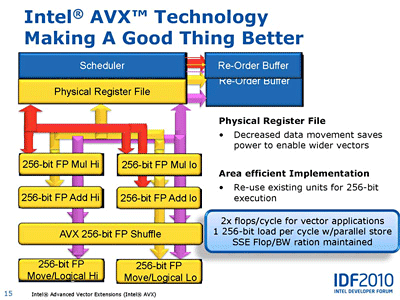
또, AVX의 탑재에 맞춰 인텔은 실행 엔진 클러스터의 명령 스케줄링의 자원도 큰폭으로 확장했다. Sandy Bridge도 out-of-order 형태의 실행 엔진으로 다수의 명령을 병렬로 늘어놓고 바꿔 실행할 수 있다. Sandy Bridge에서는 보다 많은 명령을 배열해 많은 스토어와 로드를 버퍼 할 수 있기 때문에 엔진의 성능을 더 끌어낼 수 있게 됐다. 또, 레지스터 파일을 물리 레지스터 파일에 리네이밍 하는 방식으로 전환하는 것으로 데이터의 이동을 최소화하여 전력 감소와 성능 향상을 도모했다.
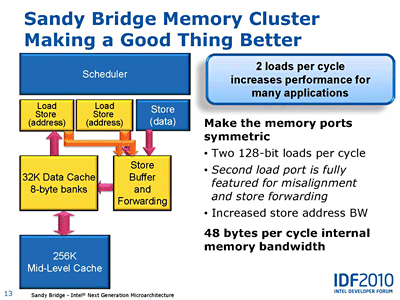
AVX로 SIMD 유닛의 연산 능력이 2배가 되면 2배의 데이터가 필요하다. 그 때문에 인텔은 메모리 클러스터의 핸들 기능을 높였다. 기존의 Nehalem은 로드와 스토어의 파이프라인이 분리되어 있었지만 Sandy Bridge는 로드/스토어의 양쪽 대응 유닛으로 바꿔 L1 데이터 캐시의 포트도 확장하고, 최대 2개의 16 bytes 로드와 1개의 16 bytes 스토어를 병렬로 처리할 수 있도록 했다.
이러한 개량의 결과로 Sandy Bridge는 정수 연산과 SIMD 부동 소수점 연산의 양쪽 모두 성능이 높은 아키텍처가 됐다.
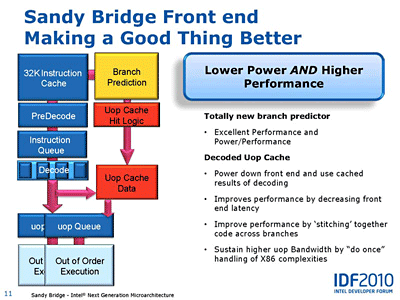
Sandy Bridge CPU 코어의 프론트엔드 클러스터, 즉 명령을 메모리로부터 가져 오고 실행할 때까지의 부분은 매우 복잡하고 강력하다. 이것은 명령 세트가 복잡한 x86 CPU 에서는 명령의 실행 자체보다 명령의 패치와 디코드가 병목현상이 되기 쉽기 때문이다. 인텔은 Core MA로 이 부분을 매우 강화했는데 Nehalem이나 Sandy Bridge에서도 계속해서 강화되고 있다. 이미 말한 것처럼 그 중에서도 핵심은 uOP 캐시(uOP Cache)로 전력 소비를 줄이면서 퍼포먼스를 올릴 수 있었다.
대부분의 x86 계열 CPU는 x86 명령을 CPU 내부 명령 uOP에 디코드해 실행한다. x86 CPU에서는 x86 명령으로부터 uOP의 디코드가 매우 무거운 짐이며 CPU 중에서도 전력을 소비하는 근원이 되고 있다. 그 때문에 x86 명령 디코드 부분을 스킵 할 수 있으면 퍼포먼스도 상승하고, 전력 소비는 줄어든다. 인텔은 이 원칙에 따라 Sandy Bridge의 프론트엔드를 크게 개량했다. 즉, 디코드한 uOPs를 캐시해 버리는 것으로 디코드하지 않아도 생략하게 설계했다.
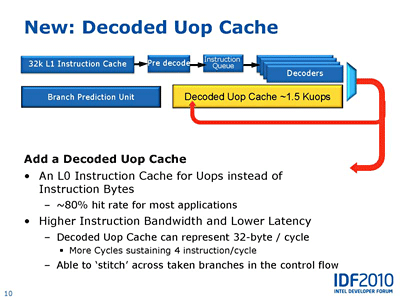

Sandy Bridge에서는 1.5K 분의 uOPs를 저장 및 유지할 수 있도록 uOP 캐시를 디코더의 후단에 대비하고 있다. 이것은 1.5KB 분의 명령이 아닌 약 1,500개분의 uOPs를 저장한다. 인텔은 이 1.5K 분 밖에 보관하지 않는 uOP 캐시로 80%의 캐시 히트율을 달성할 수 있다고 설명하고 있다. 명령 디코더를 20% 밖에 사용하지 않거나 또는 8할의 확률로 디코더를 생략할 수 있게 되면 CPU의 퍼포먼스는 현격히 오를 것이라는 점이 핵심이다. 특히 퍼포먼스 향상이 어려운 정수 연산의 향상을 기대할 수 있는 점이 크다. 다만 인텔은 아직 uOP 캐시로 80%의 근거가 되는 명확한 데이터는 밝히지 않았다. 현재대로라고 한다면 사이즈에 비해 효율이 좋은 캐시가 분명하다.
또, 이 uOP 캐시는 단순한 캐시가 아닌 명령 플로우 내의 분기를 넘어 명령 플로우를 연결시킬 수 있다. 즉, 실제로 실행되는 명령(분기 명령을 포함)의 트레이스에 따라서 캐시에 uOP를 저장할 수 있는 트레이스 캐시적인 구조가 되고 있다. 캐시 라인을 읽어내면 분기를 또 가져다 실행 트레이스로 uOP가 패치 되어 원리적으로는 효율이 오른다(조건 분기의 결과가 다르면 효율이 떨어진다). 원래 uOP가 캐시 되면 통상적인 명령 캐시와 같이 캐시 라인마다 메모리상의 정적인 명령 라인을 캐시하는 것은 아니다.
인텔이 uOPs를 캐시하는 시도는 이번이 3번째다. 우선 NetBurst(Pentium4) 아키텍처로 12K의 uOPs를 저장하는 트레이스 캐시를 L1명령 캐시 대신 적용, 다음에는 Nehalem에 28개의 uOPs를 저장하는 작은 루프 스트림 디텍터 버퍼(Loop Stream Detector Buffer)를 마련했다. 실제로는 캐시가 아니고 uOPs의 큐를 잘 이용하는 구조지만 uOPs의 재사용이라고 하는 점에서 목적이 같다.
또, 캐시의 개량에 맞춰 인텔은 Sandy Bridge의 분기 예측도 개선 했다고 설명하고 있다. 다만, 자세한 것은 거의 공개하고 않고, 분기 타겟의 버퍼가 2배가 된 것과 히스토리 버퍼가 보다 효율적으로 개선된 것등을 설명하고 있다.
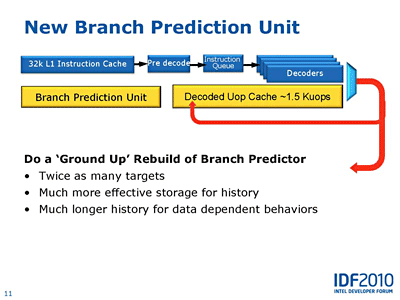
이렇게 보면 인텔은 여전히 프론트엔드 부분의 개량에 힘을 쏟고 있는 점을 확인할 수 있다. 펜티엄M(바니어스)에서는 Micro-Fusion으로 2개의 uOPs를 1개로 통합하고 내부 파이프라인으로 취급할 수 있도록 했다. Core MA에서는 매크로 퓨전(Macro-Fusion)을 도입하고, 특정의 2가지 명령을 1가지 명령에 융합시키는 것으로 명령어 인출 대역과 uOPs 대역을 실질적으로 늘렸다. 네할렘에서는 uOPs 베이스의 루프 디텍터로 루프시에 디코드 스테이지를 생략할 수 있도록 했다.
이 흐름을 보면 인텔은 향후로도 이 부분의 개량을 계속할 것으로 보인다. 명령어 인출과 디코드가 무거운 것은 x86 계열 명령이 복잡하기 때문이다. 인텔의 강력함은 x86 명령에 있지만 그것을 위한 부담이 CPU 프론트엔드를 무겁게 짓누르고 있다. 인텔은 강력함을 유지하기 위해 프론트 엔드의 개량에 계속해서 힘을 쏟고 있으며 아직까지 프론트엔드 개량의 여지가 있는 것은 확실해 보인다.