
















’ 오픈")




![[정종철] 뚜따에 진심인 형+과학자코스프레+현미경을구입했어
CPU 뚜따 교육자료ㅋㅋ](https://raptor-hw.net/xe/files/thumbnails/739/203/241x165.crop.jpg "뚜따에 진심인 형+과학자코스프레+현미경을구입했어")









- GPU 시장 분석 PART.5 < CHAOS / TAKE OFF > [ 엔비디아 GF100 페르미 ~ AMD 라데온 6K / 엔비디아 지포스 5xx) ] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2010년 3월 27일, 엔비디아가 새로운 방향성을 나타낸 GPGPU 아키텍처 페르미가 마침내 세상에 공개됐다. 엔비디아의 페르미는 경쟁사인 AMD의 5K(코드명 에버그린) 패밀리의 발표시점에 맞춰 최초 2009년 10월경 발표할 것이라고 전해졌지만 설계상의 문제에 부딪혀 발표일을 12월경으로 미뤘고, 또 다시 2010년 초로 발표를 번복하면서 우여곡절 끝에 등장하게 된다. 먼저 엔비디아가 발표 이전부터 전세계의 관심을 증폭시켰던 GPGPU 아키텍처 페르미의 구조적인 이론에 대해서 살펴보도록 한다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
▲ GF100 페르미 다이(die) 사진 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
"페르미" 라는 코드명은 이탈리아의 물리학자 엔리코 페르미 (Enrico Fermi)에서 따왔다. 엔리코 페르미는 1901년 9월 29일 로마에서 출생, 1918년 피사의 왕립고등사범학교에 들어가 학위를 얻고, 괴팅겐대학교의 M.보른, 레이덴대학교의 P.에렌페스트에게 배웠으며, 1924년 피렌체대학교 역학·수학 강사, 1926년 로마대학교 이론물리학 교수가 되었다. 처음에는 상대성이론(相對性理論)을 연구하였으나 로마대학교로 옮길 무렵부터 원자의 양자론(量子論)을 연구, 1926년 P.A.M.디랙과는 별도로 ‘페르미통계(페르미-디랙통계)’를 제안하였고, 분광학을 연구하였다. 원자핵 연구로 옮겨 1934년 β붕괴이론을 제출, 복사이론과 W.파울리의 중성미자가설을 결합시켰다. 이것은 일본의 유카와 히데키의 핵력(核力) 연구의 선구적 업적으로 볼 수 있다. 졸리오 퀴리 등에 의해 인공방사능이 발견되자(1934), 중성자에 의한 거의 모든 원소의 핵변환 가능성을 시사, 느린중성자[緩中性子]에 의한 핵변환을 행하여 많은 방사성동위원소를 만들어 초우라늄원소 및 핵분열 연구의 길을 열었다. 1938년 중성자에 의한 인공방사능 연구의 업적으로 노벨물리학상을 수상하였다. 이 무렵 무솔리니에 의한 파시즘의 압박을 의식, 노벨상 수상을 기회로 미국에 망명, 컬럼비아대학 교수가 되었으며, 그 곳에서 중성자 연구에 전념하였다. O.한 등이 핵분열을 발견하자, 2차 중성자의 방사 및 연쇄반응의 가능성을 예견하였고, 1942년 시카고대학 야금연구소로 옮겨 대형 원자로를 건설, 제어된 연쇄반응을 실현시켜, 핵에너지 해방이라는 업적을 쌓았다. 그 후 맨해튼 계획에 참가하였으며, 제2차 세계대전 후 시카고대학 교수로 있었다. 원자로 이론, 우주선(宇宙線) 이론, 가속기에 의한 중간자 연구 등 이론과 실험 양면에 걸친 연구를 계속하던 중 53세에 암(癌)으로 죽었다. - 페르미 인물백과 이처럼 본격적인 원자력 시대의 장을 연 엔리코 페르미의 업적과 같이 엔비디아는 페르미 아키텍처로 새로운 가능성의 선구적인 GPU를 나타내고자 하는 의미에서 이러한 코드명을 부여한 것으로 볼 수 있다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
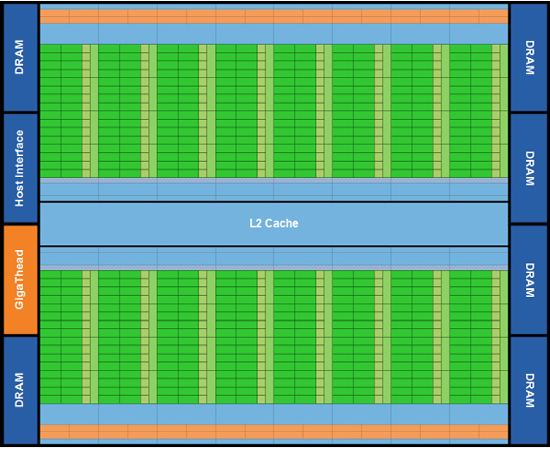
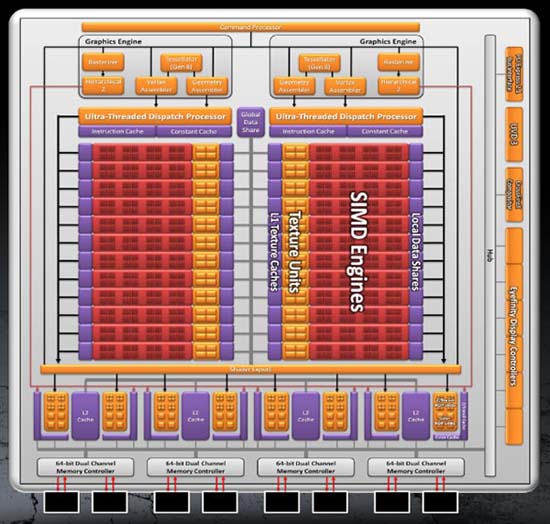
▲ GF100 페르미 계산(CUDA) 아키텍처 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
페르미는 엔비디아가 개발한 그래픽 렌더링 및 병렬계산에도 사용할 수 있는 최초의 통합 아키텍처 G80과 GT200 다음으로 선보인 제 3세대 통합 아키텍처다. 기존 G80과 GT200 아키텍처의 각 부분을 개선,보강,수정하여 만들어낸 페르미는 한층 진보된 기술들을 선보인다. 따라서 페르미의 계산 아키텍처와 그래픽 아키텍처로 나누어 세부적으로 살펴보도록 한다. 1. 페르미 아키텍처 이론 A. 계산 아키텍처 이전까지는 SP(Stream Processer)라고 불리고 있던 그래픽 연산기를 페르미부터는 새롭게 SM(Streaming Multiprocessor)이라 명명하고, SM을 이루는 각 유닛을 CUDA 코어로 명명한다. 기존 GT200 아키텍처는 1개의 SM에 8개의 CUDA 코어가 탑재되고 있었던 반면, 3세대 페르미의 SM은 1개의 SM에 32개의 CUDA 코어가 탑재되고 있다. 완전체 페르미는 이러한 SM 유닛이 총 16개로 512개의 CUDA 코어로 구성된다. [ 엔비디아에서 전한 CUDA의 정의 - CUDA ("Compute Unified Device Architecture", 쿠다)는 그래픽 처리 장치(GPU)에서 수행하는 (병렬 처리) 알고리즘을 C 프로그래밍 언어를 비롯한 산업 표준 언어를 사용하여 작성할 수 있도록 하는 GPGPU 기술이다. CUDA는 엔비디아가 개발해오고 있으며 이 아키텍처를 사용하려면 엔비디아 GPU와 특별한 스트림 처리 드라이버가 필요하다. CUDA는 G8X GPU로 구성된 지포스 8 시리즈급 이상에서 동작한다. CUDA는 CUDA GPU 안의 명령셋과 대용량 병렬 처리 메모리를 접근할 수 있도록 해 준다. 개발자는 패스스케일 오픈64 C 컴파일러로 컴파일 된 '쿠다를 위한 C' (C언어를 엔비디아가 확장한 것) 를 사용하여 GPU 상에서 실행시킬 알고리즘을 작성할 수 있다. 쿠다 구조는 일련의 계산 인터페이스를 지원하며 이에는 OpenCL, DirectX Compute가 포함된다. C 언어가 아닌 다른 프로그래밍언어에서의 개발을 위한 래퍼(Wrapper)도 있는데, 현재 파이썬, 포트란, 자바와 매트랩 등을 위한 것들이 있다. 최신 드라이버는 모두 필요한 쿠다 콤포넌트를 담고 있다. 쿠다는 모든 엔비디아 GPU (G8X 시리즈 이후) 를 지원하며 이 대상에는 지포스, 쿼드로, 테슬라 제품군이 포함된다. 엔비디아는 지포스 8 시리즈를 위해 개발된 프로그램들은 수정 없이 모든 미래의 엔비디아 비디오 카드에서 실행될 것이라고 선언하였다. 쿠다를 통해 개발자들은 쿠다 GPU 안 병렬 계산 요소 고유의 명령어 집합과 메모리에 접근할 수 있다. 쿠다를 사용하여 최신 엔비디아 GPU를 효과적으로 개방적으로 사용할 수 있다. 그러나 CPU와는 달리 GPU는 병렬 다수 코어 구조를 가지고 있고, 각 코어는 수천 스레드를 동시에 실행시킬 수 있다. 응용 프로그램이 수행하는 작업(계산)이 이러한 병렬처리연산에 적합할 경우, GPU를 이용함으로써 커다란 성능 향상을 기대할 수 있다. 컴퓨터 게임 업계에서는 그래픽 랜더링에 덧붙여, 그래픽 카드를 게임 물리 계산 (파편, 연기, 불, 유체 등 물리 효과)에 사용되며, 예로는 피즈 엑스와 불렛이 있다. 쿠다는 그래픽이 아닌 응용 프로그램, 즉, 계산 생물학, 암호학, 그리고 다른 분야에서 10배 또는 그 이상의 속도 혜택을 가져왔다. 이 한 예는 BOINC 분산 계산 클라이언트 이다. 쿠다는 저수준 API와 고수준 API 모두를 제공한다. 최초의 CUDA SDK는 2007년 2월 15일에 공개되었으며 마이크로소프트 윈도우즈와 리눅스를 지원했다. 맥 OS X지원은 2.0 버전에 추가되었다. 이점 쿠다가 그래픽 API를 사용하는 전통적인 범용 GPU에 비해 가지는 몇가지 장점은 다음과 같다. 흩뿌린 읽기 - 코드가 메모리의 임의 위치에서 데이터를 읽을 수 있다. 공유 메모리 - 쿠다는 고속 공유 메모리 지역 (16KB 크기) 을 드러내어 스레드 간에 나눌 수 있게 해 준다. 이는 사용자 관리 캐시로 사용될 수 있는데, 텍스처 룩업을 이용하는 경우 보다 더 빠른 대역폭이 가능해진다.GPU와의 읽기, 쓰기가 더 빠르다. 정수와 비트 단위 연산을 충분히 지원한다. 정수 텍스처 룩업이 포함된다. 제한 재귀호출, 함수 포인터가 없는 C 언어의 하부 집합을 확장하여 사용한다. 그러나 한개의 처리 장치가 여러개의 쪼개진 메모리 공간에 대하여 작업하여야 하는 점이 다른 C 언어 실행 환경과 다른 점이다. 텍스처 랜더링은 지원 되지 않는다. 배정도에 관해서는 IEEE 754 표준과 다르지 않다. 단정도에서는 비정상값과 신호 NaN이 지원되지 않고, IEEE 반올림 모드 가운데서는 두가지만 지원하며, 이도 명령어에 따라서 지원되는 것으로 제어 단어(Control word)에서 지원 되는 것은 아니다.(이것이 제한점인지는 논란의 대상이 될 수 있다) 그리고 나눗셈과 제곱근의 정밀도가 단정도에 비해 조금 낮다. CPU와 GPU 사이의 버스 대역폭과 시간 지연에서 병목이 발생할 수 있다. 스레드가 최소한 32개씩 모여서 실행되어야 최선의 성능 향상을 얻을 수 있으며, 스레드 수의 합이 수천개가 되어야 한다. 프로그램 코드에서의 분기는, 각각의 32 스레드가 같은 실행 경로를 따른다면, 성능에 큰 지장을 주지 않는다. SIMD 실행 모델은 어떠한 내재적으로 분기하는 임무에게는 심각한 제한이 된다. (예를 들어, 광선 추적 가속 자료 구조) 쿠다 기반 GPU는 엔비디아에서만 나온다. ] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
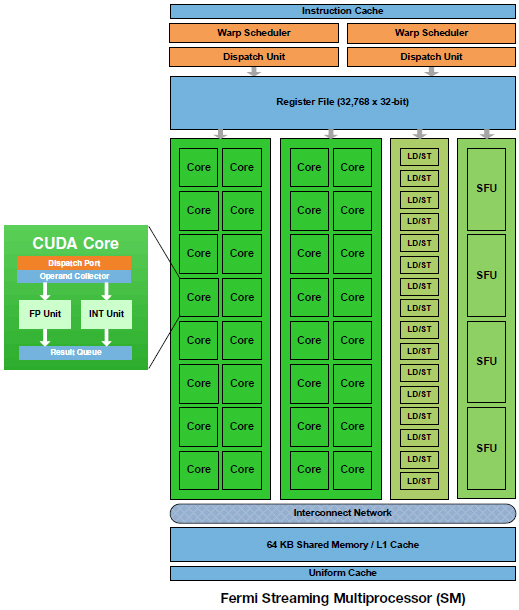
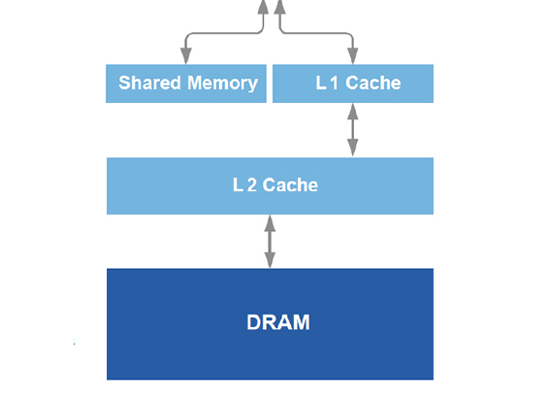
SM을 구성하고 있는 CUDA 코어는 세부적으로 부동 소수점(FP) 유닛과 정수(INT) 유닛을 각각 갖추고,기존 GT200의 24비트 ALU에서 32비트 고정밀 ALU로 확장하여 프로그램 언어의 요구에 대응하고 있다. 부동 소수점 [Floating point] = 하나의 수를 고정 소수점 부분을 나타내는 부분(가수)과 고정 소수점 위치를 나타내는 부분(지수)으로 나누어 표현하는 표기법, 또는 그러한 수치를 연산하는 연산 조직. 고정 소수점 방식보다 넓은 영역의 숫자를 나타낼 수 있어 과학적인 응용에 많이 이용된다. 정수 [Integer, integer number] = 분수나 혼합수가 아닌 모든 숫자, 계수나 셈에 사용되는 수들. 정수는 무한 수열이기 때문에 순서와 수열을 표시하는데 사용 3세대 CUDA 코어는 FP 유닛도 한 단계 진보하고 있다. 기존 GT200 아키텍처는 SM을 이루는 8개의 CUDA 코어중에 단 1개의 코어만 더블 프리시전 FP 유닛을 갖고 있었던 반면, 페르미는 32개의 CUDA 코어에서 각 2개의 코어가 1 사이클에 64비트 듀얼 프리시전 FP와 FMA 처리 과정을 실현한다. 따라서 1사이클에 16개의 더블 프리시전 부동 소수점 연산 과정을 실현할 수 있다는 점. 이 더블 프리시전이라는 것은 고성능을 요구하는 대량 계산에 반드시 필요한 부분으로, 싱글 프리시전이 32비트 실수형인것이 비해 더블 프리시전은 64비트 실수형이다. - 싱글 프리시전의 실수는 32비트의 메모리를 사용하며 7자리의 유효 숫자를 제공, 반면 듀얼 프리시전의 실수는 64비트 메모리를 사용하며 16자리의 유효 숫자 사용이 가능하다. 더블 프리시전은 원자, 양자 화학값, 선형 대수등 초고성능 계산에 반드시 필요한 부분 SM을 구성하고 있는 CUDA 코어 측면으로는 16개의 로드/스토어(LD/ST) 유닛이 위치하고, 한번의 동작 사이클로 16개의 스레드를 동시에 컨트롤 할 수 있고, 캐쉬 및 메모리의 불특정 모든 위치에서 읽어 낼수 있다. 또한 4개의 SFU(Special Function Units)는 Transcendental function (초월 함수=지수 함수,로그 함수,삼각 함수,역삼각 함수등)를 처리하는데, 한번의 클럭에 한 개의 명령조작(1개의 SM은 총 32스레드, 따라서 4개 각 조의 SFU WARP를 실행하기 위해서는 8 사이클이 필요)이 가능하고, 특정 SFU가 동작중이면 다른 SFU로 명령을 분산시킬수 있다. 이러한 SM을 구성하는 각 유닛은 인터커넥트 네트워크로 상호 이동이 가능하고, 각각의 64KB 공유 메모리와 L1 캐쉬가 데이터 완충 역활을 한다.(GT200 아키텍처는 L1 캐쉬가 없고, 16KB의 공유 메모리만 존재) 이것은 각각의 64KB 메모리를 프로그램(프로그래밍시)에서 48KB의 공유메모리와 16KB의 L1캐쉬, 또는 48KB의 L1 캐쉬와 48KB의 공유 메모리로 프로그램의 요구에 따라 커스텀할 수 있기 때문에 높은 메모리 대역을 필요로 하는 프로그램들에서는 기동 시간의 단축이나 더 빠른 처리능력을 실현할 수 있다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
또, 공유 L2 캐쉬의 추가로 공유 메모리와 L1캐쉬, 그리고 DRAM간의 데이터 순환을 유연하게 한다. 일부 계산에서는 실행전에 필요한 데이터를 예측하지 못하고, 대용량 GPU 컴퓨팅의 프로그래밍에서는 무수한 복합계산에 따라 더욱 더 캐쉬의 필요성이 증가되기 때문에 이러한 메모리 체계로 GPU 프로그래밍을 고려하고 있다. 페르미 메모리 체계의 또 한가지 특징은 최초로 ECC(Error Correcting Code) 메모리를 지원하는 GPU라는 점이다. ECC는 일반적인 환경의 유저들에게는 필요성의 여부자체가 고려되지 않지만, 페르미를 기반으로한 병렬 계산, 특히 HPC(하이 퍼포먼스 컴퓨팅)와 대용량 스케일의 컴퓨팅에서는 ECC는 필수적인 요건이다. 2세대 통합 아키텍처 GT200은 더블 프리시전FP는 실현했지만 ECC를 지원하지 않아 GT200 기반의 테슬라는 소규모 클러스터로만 사용이 가능했고, 고성능 또는 HPC 분야에는 사용하지 못했다. 페르미의 메모리 체계(공유 메모리/L1 캐쉬/L2캐쉬/레지스터/DRAM)는 모두 ECC의 보호를 받고, ECC를 지원한다는 것은 에러 정정 코드를 탑재한다는 것을 의미, 이것은 시스템의 신뢰성을 향상시키며 페르미가 초대역 스케일의 HPC 영역까지 진출할 수 있기된 기반중의 하나를 나타낸다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
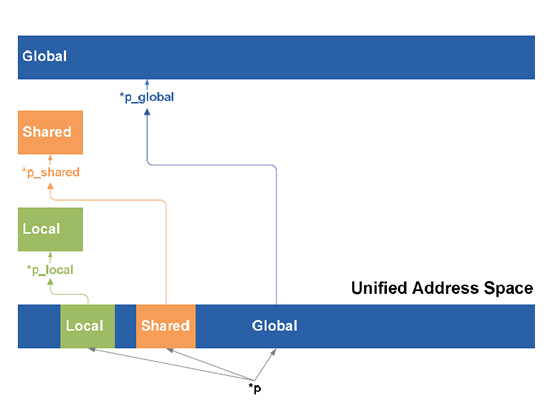
페르미는 최초로 2세대 PTX 명령어를 지원한다. PTX는 병렬 스레드 실행을 지칭하며 하드웨어와 연관이 없는 프로그래밍을 위함으로, 2세대 PTX는 통일된 어드레싱 공간과 IEEE 32비트 싱글 프리시전FP, 새롭게 추가된 오픈CL과 다이렉트 컴퓨트를 C/C++로 지원하기 위한 새로운 설계 등이 포함된다. G80과 GT200의 1세대 PTX에서는 로드/스토어를 조작할 때 LOCAL, SHARED, GLOBAL의 3가지중에 하나를 지정해야만 C/C++에서 모든 변수와 함수가 정확한 대상을 찾을수 있었다. 이것이 컴파일되면 분리된 주소 공간은 지침의 정확한 위치를 찾지 못하여 C/C++ 언어를 지원하지 못하게 된다. 페르미의 2세대 PTX에서는 이 3가지 주소 공간을 하나의 연속된 패턴 공간으로 통일해서 구체적인 주소 공간을 찾지 못하는 문제점을 해결했다. 또 2세대 PTX는 64비트의 로드/스토어 주소를 지원하여 1세대(40비트)보다 더 넓은 주소 공간을 제공하게 되면서, 대용량 계산시에 GPU 병렬계산의 공유 주소 공간을 확장시킬수 있어 전체적인 병렬 계산 능력 향상에 일조하고 있는 부분으로 볼수 있다. 페르미의 싱글 프리시전FP는 subnormal number와 4가지 라운드 모드(nearest, zero, positive infinity, negative infinity)를 지원한다. subnormal number는 0과 제일 작은 정규적인 숫자 사이에 위치하는 숫자로 페르미는 하드웨어적으로 subnormal number를 지원해서 0과 0보다 작은 FP를 정확하게 계산하여 손실을 줄일수 있게 되었다.(이전세대 G80과 GT200은 subnormal number를 지원하지 않아 0보다 작은 부동 소수점(FP)를 통상적으로 0으로만 처리하여 정확성이 떨어지고 손실율이 증가) 또 2세대 PTX는 명령어의 분산된 스레드에 predication을 하드웨적인 레벨에서 지원하여 명령 실행시 조건부 코드 부분을 단축해서 더 빠른 조건절을 처리한다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
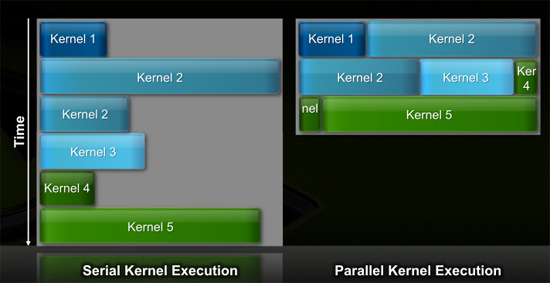
스레드 매커니즘은 GPU 리소스의 사용율을 최적화하기 위해 병렬 매커니즘으로 진화했다. GPU에서 계산되는 CUDA 어플리케이션을 커널(KERNEL)이라 부르는데, 페르미는 병렬 커널 매커니즘으로 동일한 스레드에서 또 다른 커널의 계산을 동시에 실행할 수 있다. 또, Context Switching의 향상으로 다른 스레드의 커널도 직렬방식으로 빠르게 전환하여 실행할 수 있다. Context Switching 이라는 것은 스레드 사이의 전환을 관리하는 유닛으로, 페르미는 기존의 아키텍처에서 밝혀지지 않은 특별한 기술로 Context Switching를 개선하여 스레드 사이의 전환 딜레이를 기존보다 10배 향상시킨 25밀리 세컨드 이하로 단축 시켰다. 이러한 프로그램의 최소 처리단위인 스레드의 종합적인 컨트롤은 페르미의 기가스레드 엔진이 관리한다. 1세대 통합 아키텍처인 G80에서 2배로 향상된 페르미의 기가스레드 엔진은 실시간으로 24567개의 스레드를 실시간으로 관리하고, 기가스레드 엔진은 아키텍처의 각 SM으로 스레드를 나누어 분산시키며, 각각의 SM의 2개의 WARP 스케줄러로 전달되어 SM 내부로 전달되게 된다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
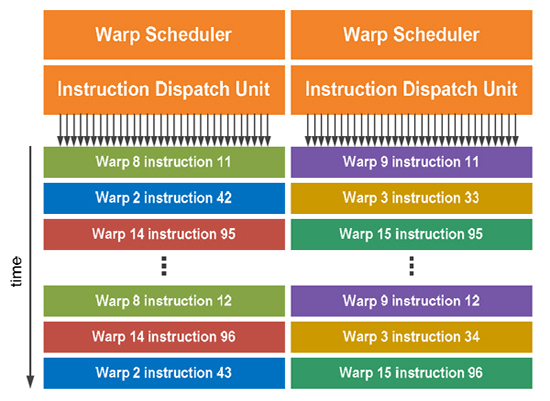
각각의 SM 내부에는 2개의 WARP 스케줄러와 2개의 명령어 디스패치 유닛으로 구성되고 있는데, 이러한 듀얼 WARP 매커니즘으로 각각의 스케줄러가 동시에 16개의 CUDA 코어로 명령을 전송하거나 로드/스토어 유닛(LD/ST), 4개의 SFU 유닛으로 전달되도록 컨트롤한다. 또한 두 개의 디스패치 유닛은 한번에 2개의 정수/부동소수점/SFU 명령/로드,스토어 명령등을 모두 병렬 실행할 수 있다. 페르미의 SM은 각 명령의 순환 과정에서 상호 의존성 검사(검증과정)를 패스할 수 있기 때문에 딜레이를 최소화하여 최대의 퍼포먼스로 연결시키고 있고, L2 캐쉬의 추가와 아토믹 유닛의 확장으로 아토믹 오퍼레이션(add, min, max, compare-and-swap와 같은 작업들이 읽기,수정,쓰기를 하는 과정중 다른 스레드를 중단시키지 않는 작업)성능을 극대화시켜 병렬 스레드에서의 연산 딜레이를 최소화 했다. (GT200의 10배 이상의 성능) < 페르미 GPGPU의 주요 특징 요약 > 차세대 실수연산 표준 규약인 IEEE 754-2008 2배 정밀도(더블 프리시전) 부동소수점(floating point) 지원 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
B. 그래픽 아키텍처 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
▲ GF100 페르미 그래픽 아키텍처 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
앞서 계산 아키텍처 측면에서 페르미의 구조를 살펴봤고, 이번에는 일반 유저들이 감흥할 수 있는 그래픽 아키텍처에 대해서 살펴보도록 한다. 그래픽 아키텍처는 일반 유저들이 3D 게임 벤치마크등으로 흔히 접할 수 있는 그래픽 처리 성능 부분으로, 일반 유저들의 GPU에 대한 가치 측정의 가장 중요한 요소로 자리잡고 있는 부분이다. 페르미는 앞서 다룬 계산 아키텍처로써도 상당한 진보를 나타내고 있는 것과 같이 그래픽 처리 측면으로서도 한단계 진보하고 있다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
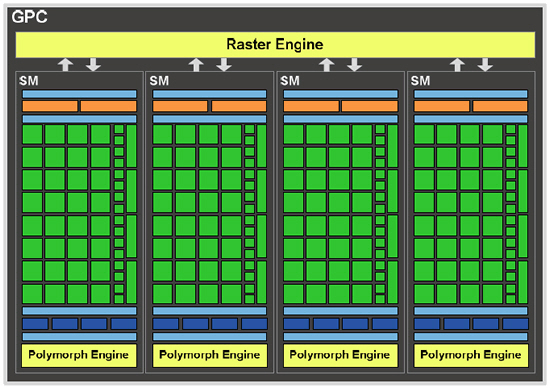
페르미의 그래픽 렌더링 아키텍처는 4개의 GPC(Graphics Processing Cluster / 각 GPC는 4개의 SM, 총 16개 SM)와 6개의 메모리 컨트롤러로 구성되고 있다. 각 GPC의 내부는 4개의 SM과 1개의 래스터 엔진을 포함하고 있다. 각각의 SM에는 앞서 설명했던 CUDA 코어에 추가적으로 텍스쳐 유닛과 폴리모프 엔진이 보이고 있다. 우선 텍스처 유닛은 각각의 SM에 4개가 배치되고 있는데, 이 텍스처 유닛의 효율 상승이 페르미의 효율 상승에 일조하고 있는 부분으로, 이전 GT200 아키텍처에는 1개의 TPC마다 8개의 텍스쳐 필터링 유닛을 텍스처 엔진이 공유하여 총 80개의 텍스처 유닛으로 구성됐다. 그러나 페르미는 텍스쳐 유닛이 64개로 줄었지만, 각각의 SM이 독립된 텍스처 유닛으로 이전 아키텍처에서는 텍스처 유닛의 동작 클럭이 코어 클럭과 동일했던 부분을 페르미는 텍스처의 동작 클럭을 코어 클럭보다 높게 설계하여 효율을 상승시켰다. 또, 텍스처는 텍스처 전용 L1캐쉬(12KB)를 추가함과 동시에 통합 L2캐쉬도 끌어 쓸수 있어 밀집된 세이더 환경에서의 적중률을 개선했다. (기존 GT200 대비 페르미의 텍스쳐 성능은 100~170% 향상) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
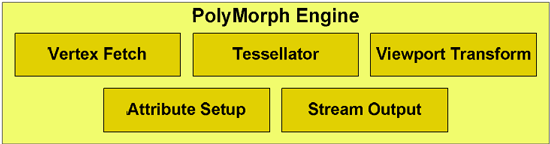
각 SM 하단으로 보이는 폴리모프 엔진은 Vertex Fetch, Tessellation, Viewport Transform, Attribute Setup, Stream Output을 관리한다. 각 SM 내부에는 1개의 폴리모프 엔진이 탑재되며 완전체 페르미에는 총 16개의 폴리모프 엔진이 탑재되는것. 각 단계의 계산결과는 SM 내부로 전달되며, 전달 받은 SM은 세이더를 실행하여 계산 결과를 다시 폴리모프의 다음 단계로 넘긴다. 이러한 계산 순환 과정이 끝나면 최종 결과가 래스터 엔진으로 전달된다. 폴리모프엔진에 보이는 테셀레이터는 경쟁사인 AMD의 RV870이 단일 테셀레이터로 설계되어 있는점과 비교하여 페르미는 각각의 SM에 1개의 테셀레이터로 총 16개의 테셀레이터를 탑재하고 있기 때문에 이 부분에서 확실한 성능 향상을 나타내고 있는 부분이다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
폴리모프 엔진에서 처리된 결과는 래스터 엔진으로 전달된다. 래스터 엔진은 Edge Setup, Rasterizer, Z-Cull의 3단계로, 첫 번째 엣지 셋업에서 버텍스나 선, 삼각형을 종합, 필요없는 부분을 제거하고, 래스터 라이저로 전달한다. 래스터 라이저에서는 각 테두리 방정식을 계산해서 픽셀을 덮을 위치를 계산하고, Z-CULL에서 최종적인 픽셀 덩어리를 얻어내고 스트림 파이프라인으로 전송한다. 페르미는 삼각형의 처리량을 늘리기 위해 총 4개의 래스터 엔진에서 1사이클에 32개의 래스터라이저 된 픽셀을 병렬 처리한다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
그래픽 아키텍처 측면으로 페르미의 또 한가지 핵심 부분은 테셀레이션(Tessellation)과 디스플레이스먼트 맵핑의 결합이다. 테셀레이션은 오브젝트나 지오메트리의 표현 형식으로 특정 화면에서 더 디테일한 지오메트리를 생성한다. 페르미는 한층 더 디테일한 표현을 위해 테셀레이션과 디스플레이스먼트 맵핑 기술을 결합했다. 테셀레이션은 새로운 기법은 아니고, 이미 영상제작 분야에서는 폭넓게 사용되고 있었고, PC 분야에서도 AMD(ATI)가 라데온 2900(R600)에서 이미 테셀레이션을 위한 테셀레이터를 탑재 했었다. 물론 당시 AMD의 테셀레이션 기법은 AMD 전용 언어에서만 구현이 가능했고, 3D 기법이나 프로그래밍에서 성숙되지 않았기 때문에 당시의 프로그래머들에게는 테셀레이션의 매력이 없었다. 또 테셀레이션이 그 동안 부각되지 않은 또 한가지 부분은 MS의 다이렉트 API에서 표준 스펙으로 채택하지 않았기 때문이다. 그러나 GPU의 하드웨어적 발전, 더욱 디테일해지고 화려해지는 그래픽 환경에 맞춰 MS는 윈도우7과 함께 등장한 다이렉트11에 바로 이 테셀레이션을 표준으로 지정하면서 다시 수면위로 떠오르게 된다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
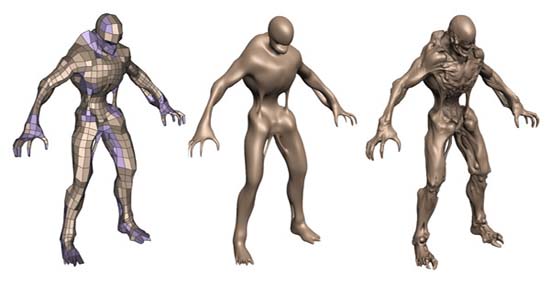
디스플레이스먼트 맵핑은 일종의 지오메트리 데이터를 압축하는 방법으로, Z-축 (높이 데이터)를 가진 모델링/렌더링 기술의 일종이다. 하나의 모델이 맵핑 될 때 버텍스의 상대적인 위치를 수정하고, 더 디테일한 지오 메트리 그래픽으로 생성하여 텍스쳐와 유연하게 결합되도록 조절한다. 위의 사진에서 처럼 좌측의 폴리곤으로 만들어낸 대체적인 캐릭터의 형태에 중간 사진과 같이 테셀레이터가 세밀하게 테셀레이션을 하여 각진 모서리 부분들이 없는 부드러운 외관을 만들어 낸다. 그러나 부드러운 외관은 만들어졌지만 세부적으로 디테일한 부분들이 없는데, 여기에 디스플레이스먼트 맵핑 기술을 적용하여 우측 사진과 같이 세부적인 형상이 만들어 지게 된다. 디스플레이스먼트 맵핑의 장점은 하나의 디테일한 모델을 표현하는데 필요한 여러 단계를 줄이면서 효율성이 높은 계산을 실현할 수 있다는 점이다. 이점은 프레임 버퍼를 더 적게 차지하고, 계산에 사용하는 대역폭이 상대적으로 줄어들면서 더 디테일한 비주얼과 리얼리틱한 동작을 표현할 수 있게 되는 것이다. 또 페르미는 하드웨어적으로 SPH(Smoothed Particle Hydrodynamics=매끄러운 입자 유체 역학) 해석 유닛을 탑재하여 프로그래머들이 사실에 가까운 유체 시뮬레이션의 구현이 가능하도록 했다. SPH를 하드웨어적으로 지원할 수 있게 된 배경은 앞서 다룬 페르미의 진보된 고속 캐쉬구조와 Context Switching 매커니즘으로 대량의 입자를 시뮬레이트 할 수 있게 된것.(SPH는 PhysX API와 연동되어 동작) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
페르미의 또 한가지 비주얼적인 진보는 바로 광선 추적(Ray tracing)이다. 사진과 같이 광선이 물체의 표면에 닿게 되면 빛이 반사 또는 굴절, 스펙트럼의 과정을 거치면서 사물의 모습에 외관적인 효과가 생긴다. 이러한 광선 추척을 기존에는 실시간으로 렌더링하기 위해서는 막대한 계산량에 따라 일반적인 구성의 CPU와 GPU만으로는 처리하기가 힘들었다. 엔비디아는 페르미의 설계 과정부터 더 디테일하고 현실적인 비주얼을 위해 앞서 설명했던 L1 캐쉬와 L2캐쉬, 래스터 라이저의 성능을 대폭 향상시키면서 최초로 하드웨어적으로 인터랙티브 광선추적을 지원하게 된다. 이러한 광선 추척 성능이 향상되었다는 점은 대량의 광선 데이터를 수집하는 광선 경로 추적(Path tracing)성능도 함께 상승되어 글로벌 일루미네이션 연산 성능 또한 향상 되고 있다는 점을 의미한다. 위의 사진은 엔비디아의 Optix 기술의 경로추적을 사용하여 렌더링된 화면으로 매우 디테일한 비주얼을 나타내고 있다. 특히 빛의 반사효과가 매우 사실적으로 묘사되고 있는 점을 확인할 수 있다. - 광선 추적(Ray Tracing) : 가상적인 광선이 물체의 표면에서 반사되어, 카메라를 거쳐 다시 돌아오는 경로를 계산하는 반사 과정. 방대한 계산이 필요하기 때문에 렌터링 속도가 가장 오래 걸릴 수 있다. - 글로벌 일루미네이션(Global illumination) : 일반적인 자연광 효과처럼 빛의 상호 반사를 모방하는 알고리즘. - 엔비디아 옵틱스 엔진 (Nvidia optix engine) : 프로그래머블 레이 트레이싱 파이프라인으로 개발자들이 C 언어로 3D 그래픽을 보다 현실적이고 디테일하게 개발하도록 지원. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 또 페르미는 3D 비전 서라운드 테크놀로지를 지원한다. 경쟁사 AMD가 라데온 5K부터 선보였던 아이피니티와 동일한 맥락의 기술로 볼수 있지만. 아이피니티가 있는 그대로의 화면(2D)을 보여준다면 엔비디아의 3D 비전 서라운드는 화면출력과 동시에 입체감 있는 3D 효과를 출력할 수 있다. 하지만 3D 비전 서라운드를 구축하기 위해서는 120Hz 리프레시를 지원하는 3D 모니터와 전용 3D 안경이 부수적으로 필요하다. 기존 GT200 아키텍처의 지포스 계열도 3D 비전 서라운드를 지원하지만 2장 이상의 카드로 SLI 구성을 해야만 원할한 프레임이 유지된다는 제약이 있고, 페르미에서 3D 비전 서라운드를 하나의 GPU로 구축이 가능해진 것은 병렬 폴리모프 엔진과 래스터 엔진, ROP의 개선에 따른 점으로 나타나고 있다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. 시장 경쟁 2009년 10월경부터 페르미가 출시된 2010년 3월까지 페르미의 출시가 지연된 세부적인 이유에 대해서는 정확하게 밝혀지지 않았고, 아키텍처 설계 과정에서 심각한 문제에 직면한 것은 확실시 되고 있었다. 페르미의 공식 발표 이후에도 정확한 이유는 확인할 수 없었지만, 엔비디아의 CEO 젠슨황은 페르미의 출시후 6개월이 지난 9월경 출시 지연에 대한 이유를 직접 설명했다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
▲ 해외 http://www.golem.de/ 에서 진행한 젠슨황과의 인터뷰 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
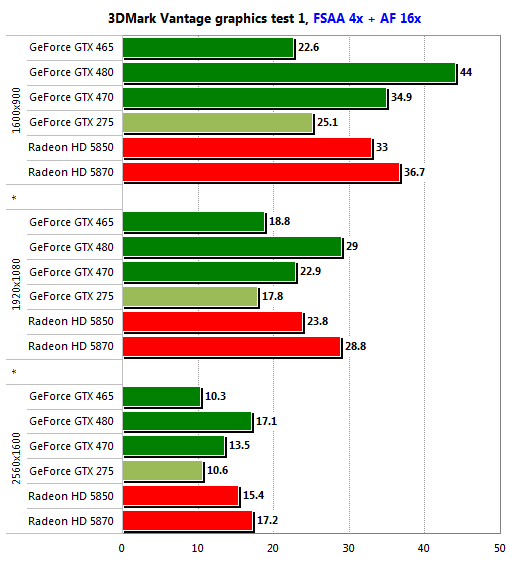
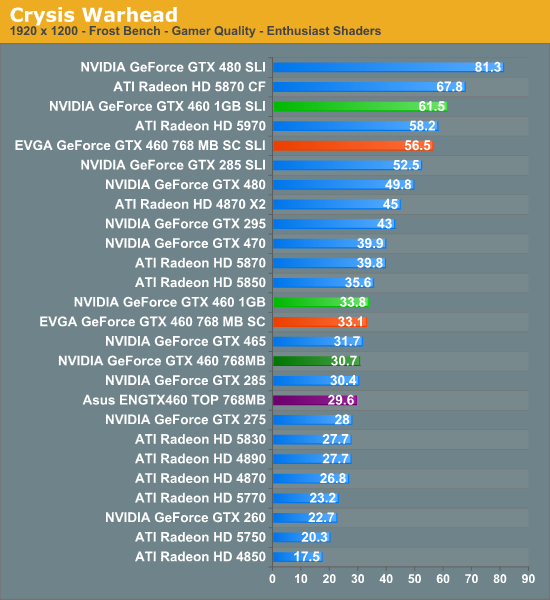
페르미의 출시가 지연된 핵심적인 이유는 아키텍처의 설계도와 이를 바탕으로 제작을 했을 때, 이론과 현실상에는 갭이 있다는 점 때문이다. 엔비디아가 2009년 9월경 설계도대로 제작한 최초의 페르미 웨이퍼 샘플을 대만 TSMC로부터 전해 받았을 때, 아키텍처의 SM(Streaming Multiprocessor)이 개별적으로는 제대로 동작하는 것으로 보였지만, 상호 SM간에 통신이 전혀되고 있지 않았다는 점. 결과적으로 각각의 SM간에 통신을 위한 접속 인터페이스에 신호 간섭이 발생해 GPU 내에서 수많은 SM이 상호 통신이 불가능하여 페르미 아키텍처를 재설계의 과정으로 빠뜨렸고, 결국 출시 시기가 지연된 것으로 밝혀졌다. 재설계의 과정 끝에 마침내 세상에 등장한 페르미의 성능은 어느정도인 것일까? 페르미가 출시된 시점에 이미 AMD는 페르미가 출시되기 6개월 전부터 라데온 5K(에버그린)시리즈로 시장에서 확고한 포지션를 구성하고 있었다. 라데온 5850과 5870은 당시 엔비디아에 경쟁할 수 있는 모델이 없었고, 이후 5700(주니퍼) 시리즈로 퍼포먼스 및 퍼포먼스 메인스트림, 5970(햄록)으로 최상위 플래그쉽, 5670(레드우드)로 메인스트림 시장까지 전체적으로 90% 이상의 세대교체가 이루어지고 있었다. 엔비디아는 AMD에게 6개월간 무방비로 시장을 내주면서 이 당시부터 라데온의 점유율은 강한 탄력을 받기 시작했고, 물론 대만 TSMC의 수율문제 때문에 수직 상승은 하지 못했지만 심대한 타격을 받게 된다. 엔비디아는 뒤늦게라도 페르미가 등장하면서 마침내 경쟁할 수 있는 모델이 라인업 되기 시작한다. 페르미 아키텍처로 최초 발표된 지포스 GTX480과 470은 출시된 직후 바로 경쟁사의 라데온 5870, 5850과 도마위에 오르게 된다. 이후 밝혀진 페르미의 퍼포먼스는 480은 라데온 5870보다 높은 성능, 470은 라데온 5850보다 높은 성능으로 나타나면서 다시 한번 자존심 회복에 성공하게 된다. [ 이하 벤치마크 그래픽(사진) 참조 : www.anandtech.com, www.xbitlabs.com ] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
▲ 상단 지포스GTX 480 / 하단 지포스GTX 470 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
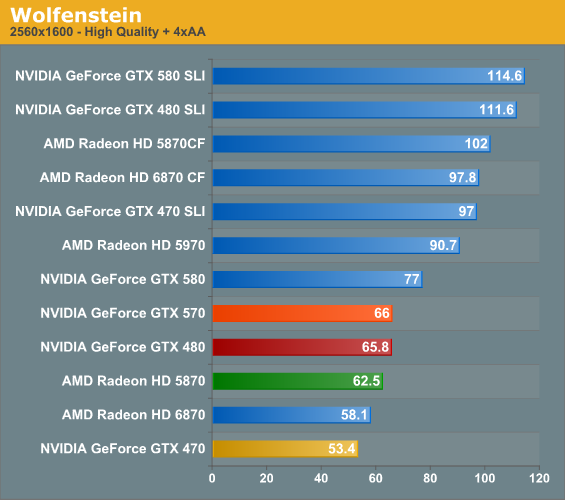
▲ 게임 성능 비교 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
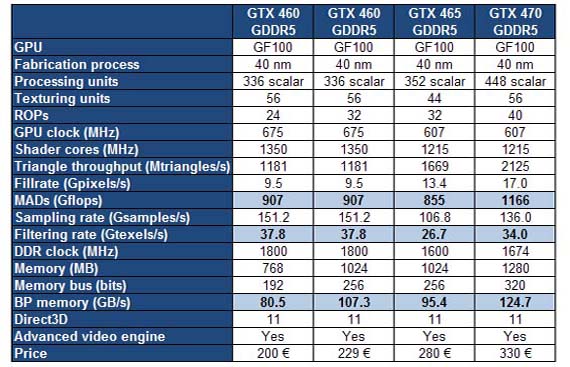
최초 발표된 페르미 기반의 지포스 480은 아키텍처의 오리지날 설계와는 다른 480개의 쿠다 코어로 발표됐다. 페르미의 완전체 쿠다코어는 앞서 설명했던대로 512개의 쿠다코어가 탑재되야 하지만 1개의 SM 모듈이 제거 되어 480개의 쿠다코어를 갖추고 있다. 이점은 페르미의 디자인에 따른 근본적인 전력소모 문제와 TSMC의 40나노 수율 문제가 겹쳐 최초의 페르미는 32개의 쿠다 코어가 제거되어 발표됐다. 그 외 텍스쳐 유닛이 기존 GT200 아키텍처 대비 60개로 줄었지만, 각각의 SM이 독립된 텍스처 유닛으로 이전 아키텍처에서는 텍스처 유닛의 동작 클럭이 코어 클럭과 동일했던 부분을 페르미는 텍스처의 동작 클럭을 코어 클럭보다 높게 설계하여 더 높은 퍼포먼스를 나타내고, ROP는 48개로 확장, 트랜지스터 카운트가 기존 대비 2배 이상 증가했고, 더 빠른 GDDR5 메모리를 탑재하고 있다. 페르미는 6개월이나 늦게 등장했음에도 경쟁사의 라데온 5870과 5850과 큰 성능차이는 나타나지 않았다. 문제는 바로 와트당 성능비로, 페르미는 하나의 GPU 임에도 두 개의 GPU로 만들어진 라데온 5970과 지포스 295를 넘어서는 심각한 전력소모 및 온도, 소음문제를 동반했다. 이에 따라 오랜 시간동안 페르미를 기다려온 일반 컨슈머들 사이에서는 페르미에 대해 "실패작이다" "망작이다" 라는 의사들이 지배적이었다. 일반 컨슈머들에게는 단순 그래픽 처리 능력이 성능 측정의 가치이기 때문에 이러한 낮은 와트당 성능과 부수적으로 높은 온도 및 쿨링 환경 문제에 따라 페르미는 발표된 시장 초기 컨슈머들이 등을 돌리게 된다. 다행히도 절대적인 성능만으로는 싱글 GPU 부분의 최고 위치를 다시 탈환했기 때문에 더 낮은 평가는 벗어날 수 있었다. 엔비디아의 지포스 480과 470의 출시 이후, 오히려 기존 라데온 5850과 5870은 높은 와트당 성능비로 오히려 더 높은 인기를 구가하기 시작한다. 특히 5850은 하이엔드 시장의 메인스트림 모델로 평가할 수 있을 만큼 높은 와트당 성능비와 적절한 가격대로 게이밍 유저들에게 최고의 인기를 독차지한다. 이에 엔비디아는 자사의 페르미 출시 이후에도 꺽이지 않고, 오히려 더 선호도가 높아지고 있는 라데온 5800에 대응하기 위해 기존 페르미의 스펙을 좀 더 낮추고, 가격까지 낮춘 지포스 GTX 465를 발표하게 된다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
엔비디아의 지포스 GTX 465은 기존 아키텍처에서 쿠다 코어를 352개로 줄이고, 메모리 인터페이스를 256비트로 낮춘 모델로, 밝혀진 성능은 라데온 5850보다는 떨어지는 라데온 5830급의 성능. 전력소모는 기존 페르미 상위 모델과 차이가 없는 매우 저조한 와트당 성능비로 라데온 5850을 상대하기에는 역부족이였다. (라데온 5830은 라데온 5850과 5770 사이의 퍼포먼스적인 갭이 커 5850의 1440개의 스트림프로세서에서 1120개로 줄이고, 코어클럭을 상승시켜 2010년 2월에 출시한 모델) 이 시기까지 엔비디아는 페르미의 6개월간의 공백, 계속된 시장에서의 라인업 실패로 마침내 글로벌 GPU 시장은 새로운 전환점을 맞이한다. AMD가 라데온 5K 시리즈를 발표하기 이전까지 8:2 또는 7:3으로 글로벌 점유율을 AMD에 확실하게 리드하고 있었지만, 머큐리 리서치가 2010년 2분기까지의 글로벌 GPU 점유율 상황을 발표한 결과, AMD의 라데온이 엔비디아의 지포스를 마침내 넘어선 것. 세부적으로 외장 독립형 라데온의 점유율은 51%, 외장 독립형 지포스의 점유율은 49%로 보고됐고, 내장 그래픽을 포함한 전체 시장 또한 AMD가 24.5%, 엔비디아가 19.8%로 AMD의 라데온이 모바일(노트북,넷북) / 데스크탑 시장 모두 엔비디아를 넘어서면서 GPU 시장은 새로운 국면을 맞이하게 되고, 지포스의 절대적인 브랜드적 우위도 이시기부터 무너지게 된다. 이러한 결과는 AMD의 라데온 5K 시리즈 발표 직후, 정확히는 2009년 9월부터 페르미가 출시되기 직전인 2010년 3월까지 엔비디아는 무방비 상태로 AMD에게 시장을 내줬고, 이후 발표된 페르미 또한 냉담한 시장 반응을 얻게 되면서 라데온의 점유율이 수직 상승하게 된 것으로 분석되고 있다. 데스크탑 시장 뿐만 아니라 모바일 시장에서도 이제는 모빌리티 라데온 시리즈를 탑재한 모바일 디바이스를 쉽게 찾아볼수 있을 정도로 AMD 라데온의 경쟁력이 급상승했다는 점을 인지할 수 있다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
▲ 엔비디아 지포스GTX 460 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
계속된 페르미의 라인업 실패, 컨슈머들에게 강하게 어필할 수 있는 제품이 엔비디아에겐 필요했다. 엔비디아는 이전세대 GTX260과 같은 당시 시점에서 AMD의 5850에 대응할 강력한 메리트의 퍼포먼스급 카드가 필요했고, 마침내 지포스 GTX460 (GF104)을 발표하게 된다. 지포스 460은 등장과 함께 많은 유저들에게 찬사를 받으며 엔비디아가 페르미 아키텍처를 기반으로한 카드를 시장에서 공격적으로 공략할 수 있는 기반을 만들어주게 된다. 지포스 460은 이전 480과 470, 465의 고질적인 높은 소비전력 및 온도, 소음 문제, 종합적으로는 낮은 와트당 성능을 상대적으로 개선하며 일반 컨슈머들이 실질적으로 구매할 만한 가치가 있는 페르미 기반의 카드를 제공할 수 있게 된 것. 지포스 GTX460 (GF104)는 페르미의 그래픽 연산 부분을 최적화시킨 GPU로 카드 네이밍은 460으로 표기되고 있지만 이전에 출시된 지포스 465보다 높은 퍼포먼스와 상당한 전력감소를 실현하여 상대적으로 높은 와트당 성능을 실현했다. 일반적인 스펙으로만 볼때는 쿠다 코어를 줄이고 코어/세이더/메모리 클럭을 향상시킨것으로만 생각할 수 있지만, 이전모델 대비 확실히 높아진 와트당 성능은 일정 부분 아키텍처 개선이 시행된 것으로 세부적으로 어떤 유닛을 어떻게 개선했는지는 정확하게 밝혀지지 않았다. 지포스 460은 메모리 인터페이스가 각각 256비트/192비트, 메모리 용량이 1GB / 768MB 로 분류되어 지포스 GTX460 1GB, 지포스 GTX460 768MB의 2가지 모델로 출시됐고, 지포스 GTX460 1GB 모델은 라데온 5850에 근접하는 성능으로 가격대는 30만원 전후, GTX460 768MB 모델은 라데온 5830 모델보다 좀더 높은 성능으로 가격대는 20만원 중반대로 출시되면서 당시 30만원 후반선에 포진션된 라데온 5850, 20만원 후반선에 포지션된 라데온 5830을 강하게 압박하면서 이후 급격한 가격인하는 없었지만 순차적으로 가격인하를 진행하게 된다. 엔비디아는 AMD가 라데온 5K 시리즈를 발표한뒤 10개월이 지난 시점, 약 1년이 다 되어가는 시점에 지포스 460으로 시장에서의 경쟁력을 갖추기 시작했고, 이후 쿠다 코어의 갯수와 메모리 인터페이스, 코어/세이더/메모리 클럭의 차이를 둬 메인스트림 라인업 타겟의 지포스GTS 450과 밸류 라인업 타겟의 GT430을 순차적으로 발표하면서 전체적인 라인업을 구축하게 된다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
지포스GTS 450은 AMD의 라데온 5770과 엔비디아의 이전 지포스GTS 250의 미들급 성능, 결과적으로는 라데온 5750과 동급의 성능으로 밝혀졌고, 밸류 시장 타겟의 지포스 GT430은 라데온 5550급의 성능으로 밝혀졌다. (퍼포먼스 부분은 설명과 같고, 페르미 기반의 모든 GPU는 AMD의 동급 GPU보다 소비전력이 높다는 점도 참고) 엔비디아는 AMD의 에버그린 패밀리의 출시이후 1년여간의 딜레이 기간동안 차세대 페르미 아키텍처 기반의 라인업을 구축했고, 엔디비다아가 지포스 460과 450을 발표하고 있을 무렵, 이미 해외에서는 AMD의 차세대 GPU (6K 노던 아일랜드)에 관한 정보가 유출되고 있었다. AMD는 엔비디아가 페르미의 출시 딜레이와 라인업 구축 문제에 직면하고 있을 때, 이미 완성된 라데온 5K 시리즈의 라인업에 따라 다음 세대의 GPU를 준비하고 있었다. 그러나 TSMC가 40나노의 다음 단계인 32나노 공정을 취소하고 28나노 공정으로 이행한다는 발표를 함으로써, AMD는 향후 GPU 로드맵을 수정해야 했다. AMD는 새로운 GPU를 출시할 때 엔비디아보다 한세대 빠른 제조공정을 적용함으로써, 더 높은 와트당 성능 및 코스트 대비 성능이 우위에 있는 카드를 컨슈머들에게 제공할 수 있는 원동력이었다. 그러나 TSMC의 32나노 공정 취소는 AMD가 5K 이후의 GPU를 구상하는데 제동이 걸려 AMD는 라인업의 수정이 불가피했다. AMD의 최초 계획은 40나노에서 32나노로 이행하면서 기존 아키텍쳐를 쇄신하여 퍼포먼스를 높힌 서던 아일랜드(라데온 6K)를 발표할 예정이었으나 TSMC가 32나노 공정을 취소하면서 동일한 40나노 공정으로는 혁신적인 아키텍쳐 개선은 불가능해졌다. 따라서 AMD는 동일한 40나노 공정으로 기존 아키텍쳐를 개량한 새로운 로드맵으로 "노던 아일랜드"로 명명하여 로드맵을 수정했다. 이점은 엔비디아에게는 호재로 작용했다. 앞서 설명한대로 엔비디아는 이전까지 AMD에 한세대씩 공정 전환에 뒤쳐져 왔기 때문이다. 이로 인해 상대적으로 다이사이즈는 더 거대했고,(설계상의 방향성의 차이도 있다), 더 낮은 와트당 성능, 칩의 단가, 더 나아가서는 카드의 단가 경쟁에서도 밀려왔기 때문이다. 결과적으로 AMD의 서던 아일랜드에서 또 한번 뒤쳐질수 있었던 제조 공정의 문제를 TSMC의 32나노 공정 취소가 해결하게된 것. AMD는 엔비디아가 뒤늦게 페르미 기반의 라인업 구축을 완성할때쯤 수정된 로드맵에 따라 기존 에버그린 5K를 개량한 새로운 라데온 6870 / 6850 (코드명 BARTS)를 2010년 10월 공식 발표한다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
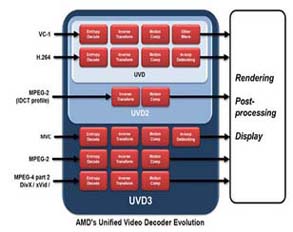
라데온 6800 시리즈는 앞서 설명한바와 같이 기존 라데온 5K 아키텍쳐의 기본적인 내부구조는 크게 변한 것이 없다. 6800 시리즈는 5K 아키텍쳐의 효율개선에 초점을 맞춰 SP(스트림 프로세서)의 갯수는 감소했지만 동작 클럭을 상승시켜 퍼포먼스를 보완하고, I/O 부분을 개선, 페르미 기반의 지포스 4시리즈에 확실히 밀리고 있었던 테셀레이터 유닛을 강화했다. AMD는 세부적인 아키텍쳐내의 개선 내용은 밝히지 않았지만, 동일한 40나노 공정으로 다이 사이즈가 기존 5850 대비 25% 작아지면서도 퍼포먼스를 유지하고, IDLE TDP까지 감소하고 있다는 점은 어느정도 아키텍쳐내의 각 유닛 블록을 개량하여 최적화 했다는 점을 인지할 수 있다. 또, 개선된 I/O 부분에서 세부적으로는 UVD3를 지원한다는 점이다. UVD는 AMD의 라데온 GPU에 탑재되는 비디오 가속 엔진으로 라데온 HD 2000 시리즈에서 처음으로 탑재됐다. 라데온 6800에 탑재된 UVD3 엔진은 기존 UVD의 VC-1(WMV-HD), H.264(MPEG-4 AVC), 듀얼 스트림 재생 기능에 MPEG-4 MVC(Blu-ray 3D 코덱), DivX/Xvid의 하드웨어 디코더 기능까지 추가되면서 대부분의 주요 동영상 포맷 가속에 대응하고 업계 최초로 디스플레이포트 1.2와 HDMI 1.4a 인터페이스를 지원한다. 라데온 6800은 기존 라데온 5K에서 선보였던 하나의 카드로 3개의 디스플레이로 출력하는 아이피니티 기술 또한 확장했다. 라데온 6800은 하나의 카드로 4개의 디스플레이까지 출력이 가능하게 되면서 더 진보된 데스크탑 멀티 플레이 환경을 실현할 수 있게 된다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |  | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
라데온 6800 시리즈의 밝혀진 성능은 라데온 6870이 5870과 5850의 미들급, 세부적으로는 지포스 470급 퍼포먼스, 라데온 6850은 라데온 5850과 5830의 미들급으로 세부적으로는 지포스 460과 동급의 퍼포먼스를 나타냈다. AMD는 TSMC의 32나노 공정 취소에 따라 동일한 40나노 공정으로 제한적 개량의 한계성으로 확실한 퍼포먼스 상승이 불가능했기 때문에 세부 유닛 블록 최적화로 이전 5800의 퍼포먼스는 유지하면서 I/O 기능을 강화, 전체적으로 다이사이즈가 감소하면서 단가 경쟁력이 상승하여 기존 고가의 라데온 5800을 보다 더 저렴한 가격으로 구매할 수 있게 된다. 라데온 6800의 등장은 기존의 높은 가격대에 형성되어 있었던 라데온 5800 시리즈를 보다 더 저렴한 가격으로 컨슈머들이 어프로치 할 수 있게 되면서 출시와 동시에 시장에서 높은 인지도를 형성한다. 이미 시장에서 안정적인 포지션으로 엔비디아의 경쟁력을 다시 회복하는데 중추 역할을 담당하고 있었던 지포스GTX 460과 AMD의 라데온 6800의 등장으로 퍼포먼스 메인스트림 라인업의 GPU 시장은 다시 한번 치열한 경쟁이 점화되기 시작한다. 지포스 GTX460 시리즈와 라데온 6800 시리즈는 초기 30만원선(6870은 30만원 중후반선)에서 20만원 중반선의 가격대 형성에서 현재는 20만원 중 후반선(6870은 30만원선)과 20만원 초반선으로 가격 안정화가 진행되면서 유저들의 선호도에 따라 높은 인기를 구가하고 있는 양사의 현재 진행형 퍼포먼스 메인스트림 모델들이다. AMD의 6K 시리즈 공식 로드맵에 의하면, AMD는 최초 6800 (BARTS)를 발표, 이후 6900 (CAYMAN), 플래그쉽 듀얼 GPU 6990 (ANTILUS)와 메인스트림 및 밸류 라인업을 순차적으로 선보일 것이라 나타났다. 이에 엔비디아는 AMD가 6800을 개발하고 있을 당시부터 이에 대응하기 위해 기존 페르미 아키텍쳐를 개량한 새로운 지포스GTX 5xx 모델을 준비하고 있었다. 엔비디아는 AMD가 2010년 10월 6800을 발표하고난 약 한달이 지난 11월, 새로운 지포스GTX 580을 발표하면서 다시 한번 싱글 GPU 최상위 왕좌를 석권하면서 AMD의 6K 세대에 본격적으로 대응하기 시작한다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
엔비디아의 지포스GTX 580은 엔비디아가 최초 설계한 페르미의 오리지날 아키텍쳐의 완성형으로, 중추 퍼포먼스 유닛인 쿠다 코어가 앞서 발표했던 지포스GTX 480의 480개 쿠다 코어에서 512개의 쿠다 코어로 확장, 텍스쳐 유닛 또한 64개로 확장했다. 최초 발표한 지포스 480은 계속된 발표 딜레이로 인한 시기상의 압박과 TSMC의 불안정한 40나노 수율에 따른 아키텍쳐의 최적화 문제가 결합되어 하나의 SM 모듈(32개 코어)를 제거한 480개의 쿠다 코어로 선보였다. 당시 480개로 쿠다 코어를 줄였음에도 막대한 소비전력을 나타냈기 때문에 512개의 쿠다코어를 적용했다면 더 심각한 결과를 초래했을 것이지만, 지포스GTX 580은 페르미 아키텍쳐의 최적화가 함께 진행되면서 확실한 와트당 성능 향상을 실현하게 된다. 엔비디아도 AMD와 마찬가지로 TSMC가 32나노 공정을 건너 뜀에 따라 동일한 40나노 공정으로 아키텍쳐를 개량해야 했기 때문에 기존 페르미의 전체적인 디자인에서 32개의 쿠다 코어를 활성화 시키면서 퍼포먼스는 증가하되 그에 따른 소비전력을 최소화 하기 위한 유닛 블록 최적화 및 트윅 과정을 거쳐 개선된 모습으로 등장했다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
AMD 라데온 6K 시리즈와 엔비디아의 5XX 모델은 TSMC의 32나노 공정 취소로 인해 기존 아키텍쳐의 약간의 개량을 통한 와트대비 성능 향상을 실현한 공통점을 갖고 있지만, 아키텍쳐의 구조적인 설계에 따른 방향성의 차이로 개량의 과정은 다른 성향을 띠고 있다. 예를 들어 AMD의 6870은 기존 5850의 1440개의 스트림 프로세서에서 1120개로 스트림 프로세서를 줄이고, 트랜지스터 카운트도 2.15B에서 1.7B로 줄여 25% 정도 다이사이즈도 감소했지만 5850의 성능은 넘어서고 있다. 반면 엔비디아의 580은 기존 480대비 다이사이즈도 비슷하고, 트랜지스터 카운트도 동일, 쿠다 코어 32개를 추가 활성화 하여 성능향상을 도모하고 있다. (양사 모두 아키텍쳐의 유닛 블록 최적화 작업, 이전 모델 대비 클럭 상승 부분은 동일) 이점은 아키텍쳐의 차이점으로, AMD의 라데온은 순수한 그래픽 처리기의 성향으로 설계가 되었다면, 엔비디아의 페르미 기반의 GPU는 서두에 설명한 것과 같이 그래픽 처리기로써 뿐만 아니라 GPGPU(연산기)로써의 설계와 계산 유닛의 연계로 인해 다이가 복잡한 모습을 나타내고 있기 때문에 상대적으로 AMD보다 개량을 함에 있어서 좀 더 어려운 부분이 많다. 결과적으로 AMD는 퍼포먼스 라인업의 라데온 6800을 발표, 이후 엔비디아는 하이엔드 라인업의 지포스 580을 발표하여 각각 포지션이 다른 라인업의 모델을 선보였지만 양사 모두 새로운 세대의 모델로 또 다시 경쟁이 점화되기 시작했다. 엔비디아는 지포스GTX 580의 발표 이후, 지포스GTX 570을 연이어 발표하면서 AMD보다 한층 더 두터운 하이엔드 라인업을 구축하기 시작했고, AMD에 강한 압박을 가하게 된다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
지포스GTX 570은 이전 세대 지포스 480과 쿠다 코어, 텍스쳐 유닛이 각각 480/60 개로 동일하고, 메모리 인터페이스가 320비트로 축소, 메모리 용량도 축소됐지만 코어/세이더/메모리 클럭을 높여 성능을 만회하고 있다. 지포스 570의 밝혀진 성능은 기존 480과 동급의 성능을 나타냈고, 480의 고질적인 문제였던 전력소모, 발열, 소음등을 개선하여 480을 최적화하여 대체 모델로써 라인업에 포지션 된다. 또한 지포스GTX 570은 40나노 공정의 안정화에 따라 480대비 50달러 정도 저렴한 가격대를 형성하면서 게이밍 유저들의 어프로치를 향상시키면서 엔비디아의 하이엔드 라인업을 보다 강화시킨다. 이에 AMD는 최초 선보인 새로운 6세대의 6800 이후, 로드맵에 따라 라데온 6900을 준비하고 있었고, 엔비디아의 지포스GTX 570보다는 1주일 정도 늦게 2010년 12월, 라데온 6900(코드명 CAYMAN)을 발표하게 된다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
발표된 라데온 6900의 근본인 VLIW4 아키텍쳐는 AMD의 과거 2K 시리즈에 처음 탑재되었던 R600 아키텍쳐 이후 처음으로 많은 쇄신이 이루어진다. AMD의 R600 아키텍쳐는 최초의 2900 시리즈부터 3K,4K,5K,6800 시리즈까지 적용된 아키텍쳐로, 기본적인 핵심 연산 유닛 형태는 유지했고 제조 공정의 이전에 따른 연산 방법의 최적화 및 효율 증대, 규모 확장등의 개량을 통하여 비약적인 발전을 도모했다. 기존까지 사용해 왔던 VLIW5 아키텍쳐와 CAYMAN의 VLIW4 아키텍쳐의 주요 차이점은, 기존 VLIW5가 4개의 ALU와 1개의 특수한 함수 조작을 처리했던 ALU.TRANS 유닛을 포함하고 있었던 반면, VLIW4는 이 ALU.TRANS(FP MAD 및 SIN, COS, LOG, EXP등)의 역할을 4개의 ALU에 분산하여 포함시키면서 이 부분을 제거하여 효율 향상을 도모하고 있다는 점. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
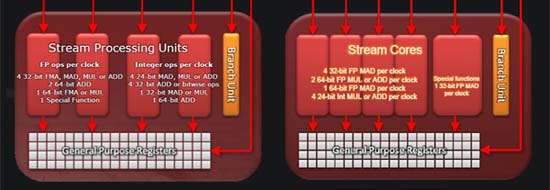
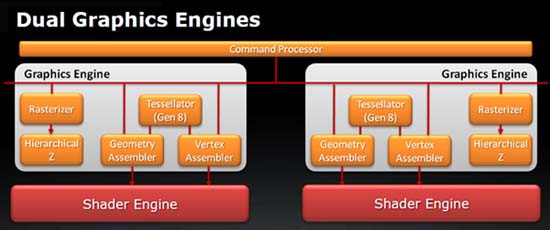
▲ 좌측 VLIW4 (6900) / 우측 VLIW5 (6800 및 이하 HD 라데온) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
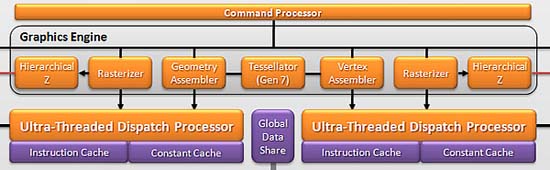
VLIW4의 또 한가지 핵심적인 부분은 싱글 그래픽 엔진에서 듀얼 그래픽 엔진으로 변경하면서 효율을 증가 시켰다는 점이다. 이 그래픽 엔진에는 Tessellator, Geometry Assembler, Vertex Assembler, Rasterizer, Hierarchical Z 유닛으로 구성되는데 기존까지는 이 부분을 하나로 배열 했지만 VLIW4에서는 이 부분을 각각 2개의 유닛 그룹으로 나누었다. 세부적으로는 2개의 엔진으로 나누면서 1 사이클에 2개의 Primitive (그래픽 처리의 기본 요소)를 처리할 수 있게 되면서 좌표 전환과 불필요한 요소를 제거할 때의 퍼포먼스가 2배로 증가하고 렌더링 처리능력도 개선됐다. 또 기존까지 1개만 탑재되었던 테셀레이터를 두 개로 나뉘어진 각각의 그래픽 엔진에 탑재하여 총 2개로 강화했고, 탑재된 테셀레이터도 8세대로 개선하면서 테셀레이션의 처리 능력이 비약적으로 상승했다. 이점은 엔비디아의 경쟁모델이 10개의 테셀레이터를 탑재하고 있는 것과 비교하면 2개의 테셀레이터 탑재는 AMD가 아직까지 테셀레이션에 보수적인 점을 확인할 수 있고, 일부 고정밀 비주얼의 테셀레이션 처리 능력을 필요로 하는 프로그램 및 게임에서 경쟁사의 모델과 많은 성능차이가 발생할 수밖에 없는 부분이다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
VLIW5 싱글 그래픽 엔진 (라데온 2K ~ 라데온 6800) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
VLIW4 듀얼 그래픽 엔진 (라데온 6900) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
또, VLIW4는 안티 앨리어싱 퍼포먼스에 연계되는 ROP를 기존과 동일한 32개를 탑재했지만 Render Back-Ends의 16비트 조작 성능을 2배, 32비트 싱글/듀얼 부동 소수점의 조작을 2~4배 정도 개선하여 고해상도 환경에서의 퍼포먼스를 증가시켰다. CAYMAN은 VLIW4 아키텍쳐로 설계를 변경하면서 GPU 컴퓨트(통용 계산)의 퍼포먼스도 개선된 모습을 보여주고 있는데, 세부적으로는 비동기 매커니즘을 적용하면서 동시에 다수의 커널을 실행할 수 있고(멀티 컴퓨트 커널), 듀얼 DMA(DIRECT MEMORY ACCESS) 엔진을 탑재하여 시스템 메모리와 더 빠른 읽기/쓰기 엑세스가 가능하도록 했다. 추가적으로 통합 세이더 읽기 조작, 다이렉트 LDS(LOCAL DATA SHARE), 개선된 스트림 컨트롤등으로 전체적인 통용계산 성능을 증가시켰고, AMD는 이러한 VLIW5 -> VLIW4 아키텍쳐로 전환하면서 동일한 크기의 다이 사이즈로 전체적으로 10% 정도 더 증가된 퍼포먼스를 얻을수 있었고, 명령어와 레지스터 조절이 간결, 로직회로의 효율이 상승했다고 설명했다. AMD가 이처럼 GPU 컴퓨트 퍼포먼스를 비약적으로 개선했지만 서두에 다룬 GPGPU를 근본적으로 지향한 엔비디아의 페르미 아키텍쳐에는 구조적인면부터 역부족이며, 앞서 설명한 테셀레이션과 마찬가지로 GPU의 GPGPU적 방향성 부분 또한 AMD는 아직까지 보수적이라는 점을 재차 확인할 수 있다. 라데온 6900은 AMD의 이전 세대 싱글 최상위 GPU 였던 라데온 5870의 VLIW5 아키텍쳐에서 VLIW4로 변경하면서 스트림 프로세서를 줄이고 프로세스의 효율은 상승시켰지만 명령어 송출, 분기 실행 유닛, 통용 레지스터등의 유닛이 증가되면서 더 많은 트랜지스터를 요구하여 소비전력과 다이사이즈가 증가했다. 이러한 부분은 동일한 40나노 공정으로 VLIW4 아키텍쳐의 전환에 따른 점으로, TSMC의 32나노 공정취소로 엔비디아와 AMD 모두 제한적 개량에 의해 이전 세대 대비 확실하게 발전된 모습을 보여주지 못했다. (6970의 트랜지스터는 26.4억개, 코어 면적은 389mm2 / 5870의 트랜지스터는 21.5억개, 코어 면적은 334mm2) 그 외 지포스 5세대와 라데온 6900에서는 향상된 전력 컨트롤 기능을 탑재했지만 TSMC의 32나노 공정취소에 따라 동일한 공정내에서 효율의 제한성으로 확실한 차이점을 나타내고 있지 않기 때문에 이 부분은 다루지 않는다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
AMD가 이처럼 4년만에 많은 개선을 적용한 VLIW4 아키텍쳐의 라데온 6900의 퍼포먼스는 어느 정도 일까, 라데온 6900은 출시 이전부터 아키텍쳐의 전환으로 인한 상당한 퍼포먼스가 기대되고 있었다. 당시 해외의 많은 매체들이 관련 루머들을 유출하면서 그 기대감을 증폭시켰지만 결과는 예상보다는 낮은 성능을 보이고 있었다. 세부적으로 라데온 6970은 지포스 580과 570의 미들급 퍼포먼스, 라데온 6950은 지포스 570과 동급, 또는 미세하게 떨어지는 성능으로, AMD가 말한 이전 세대 5800 대비 10% 향상이 그대로 나타난것. 라데온 6900과 지포스 580/570의 차이점은 지포스 580/570은 기존 페르미 아키텍쳐의 최적화판이라면, 라데온 6900은 그 동안 라데온 2K부터 6800까지 적용해왔던 VLIW5 아키텍쳐에서 VLIW4로 아키텍쳐가 쇄신된 프로토 모델이라는 점이다. AMD는 2K(R600)에 적용된 VLIW5 아키텍쳐를 공정 이전과 효율 개선등으로 라데온 3K,4K,5K를 거쳐 라데온 6800에서 정점에 도달한다.(라데온 6800은 VLIW5가 적용됐지만 TSMC의 32나노 공정 취소로 로드맵의 수정으로 탄생한 파생물) AMD는 라데온 5K 시리즈의 라인업 완성 이후, 같은 아키텍쳐로 더 이상의 상위 GPU를 발표하는 것은 무의미하다고 판단하여 새로운 아키텍쳐로 이행할 계획이었지만 TSMC의 32나노 공정 취소가 발목을 잡았고, 수정된 로드맵에 따라 AMD는 6800에 한번 더 VLIW5를 적용, VLIW4로 아키텍쳐가 쇄신된 라데온 6900을 차례로 선보인것. 과거 VLIW5를 최초 탑재한 라데온 2900이 심각한 전력소모와 낮은 성능으로 시장에서 최악의 평가를 받았고, 이후 공정이전과 아키텍쳐의 최적화로 라데온 3K부터 5K까지 지금의 라데온의 높은 입지를 다져준점을 생각한다면 VLIW4를 적용한 최초의 라데온 6900도 이후 28나노로의 공정이전과 연산 방법의 최적화 및 효율 증대, 규모 확장등으로 다음 세대부터 보다 더 강력한 모습을 기대해 볼수 있다. 반면 엔비디아는 아키텍쳐가 완전히 쇄신된 페르미를 선보인지 1년도 지나지 않은 시점으로, 최적화나 개량할 여지가 많이 남아 있기 때문에 당분간은 시장에서 엔비디아의 우위가 유지될 것으로 전망된다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
현재 엔비디아는 지포스GTX 580/570에서 쿠다 코어, 메모리 인터페이스를 낮추고, 코어/세이더/메모리 클럭을 상승시킨 지포스GTX 560 TI까지 발표한 상태다. 지포스GTX 560 TI는 기존 지포스GTX 4세대의 460과 같이 지포스 5세대의 퍼포먼스 메인스트림 라인업에 포지션 되고, 이에 AMD는 라데온 6950 1GB 메모리 버전으로 맞불을 놓은 상태로, 이후 2011년 3월경 양사는 두 개의 GPU로 설계되는 지포스GTX 590 / 라데온 HD 6990을 발표하여 최상위 플래그쉽 왕좌의 쟁탈전을 준비하고 있는 상황으로 시장은 계속 진행되고 있다. 엔비디아가 페르미 아키텍쳐를 발표한 이후 페르미가 적용된 지포스 4세대부터 5세대 모델까지 모두 AMD의 각 라인업 경쟁 모델(라데온 5K / 6K)에 와트당 성능이 떨어진다는 점도 인지할 필요성이 있다. 이점은 엔비디아와 AMD의 방향성의 차이로 엔비디아는 단순 그래픽 처리기를 벗어나 범용 컴퓨팅을 지향하는 구상으로 앞서 설명한 것과 같이 다이가 상대적으로 더 복잡하고 거대하여 상대적으로 AMD의 그래픽 처리 지향적인 아키텍쳐보다 높은 전력소모와 발열을 나타내고 있는 것. 물론 AMD도 계속해서 GPU 컴퓨트 퍼포먼스를 개선하고 있지만 페르미와 비교할 수준은 아니기 때문에 이 부분에서 AMD는 아직까지 보수적인 면을 재차 확인할 수 있다. 그렇다면 엔비디아가 GPGPU를 근본적으로 고려한 페르미는 현재 범용 컴퓨팅 시장에서 어떤 모습을 보이고 있을까, 3. 엔비디아의 비전 GPGPU = (General Purpose computing on Graphics Processing Units, 범용 컴퓨팅) GPU를 사용하여 CPU가 담당했던 응용프로그램등등의 계산을 그래픽 파이프라인(아키텍쳐 유닛)에 연결하여 계산을 수행하는 기술 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
▲ 현존 최고의 슈퍼 컴퓨터 티엔허(Tianhe)1-A | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
엔비디아는 최초로 CUDA를 적용한 1세대 통합 아키텍쳐 G80 세대부터 테슬라 GPU를 선보였다. 테슬라는 19세기 발명가 니콜라 테슬라에서 따온 명칭으로, GPGPU를 위해 아키텍쳐를 계산 유닛 중점으로 설계한 그래픽 프로세서. G80세대부터 선보인 테슬라는 당시 GPU의 계산 능력과 효율성, 파이프라인에 명령을 연결시키는 과정에 대한 문제가 부각되어 일부 라이트한 연산 머신들에 탑재되긴 했지만 고성능 컴퓨팅, HPC 시장에서 요구되는 부분들의 한계성(서두의 페르미 계산 아키텍쳐 이론 참고)으로 시각은 부정적이었고, 시장에서 강한 어필을 할 수 없었다. 엔비디아의 CEO 젠슨황은 자사의 통합 아키텍쳐 G80과 GT200의 시기를 거치면서 중요한 결정을 해야했다. 이전까지 자사 수익의 30% 정도를 점유했던 마더보드 칩셋 시장의 철수와 계속되는 AMD의 강한 압박, 또한 장기적으로 인텔과 AMD의 퓨전프로세서(CPU+GPU)로의 이전등으로 인해 PC 시장에서 엔비디아의 비전이 불투명 해졌기 때문이다. 이에 젠슨황은 차세대 아키텍쳐 페르미를 개발하고 있을 당시부터 페르미를, "GPGPU를 위한 풀 스크래치로, GPU의 아키텍쳐 비중을 단순 그래픽 처리로부터 범용 컴퓨팅으로 이전하는 새로운 세대의 GPU다" 라고 선언하며 자사의 경쟁력중에 하나를 GPGPU라고 공식 발표한 것과 같은 의미를 나타내고 있었다. 2010년 3월, 엔비디아는 마침내 많은 기대와 함께 페르미를 공식 런칭한다. 발표 초기, 그래픽 처리기로써의 페르미의 평가는 높지 않았지만, GPGPU 로써의 페르미는 업계의 관심을 끌기에 충분한 구조적인 진보를 나타냈고, 기존의 단순 CPU 클러스터 대비 10분의 1의 비용과 20분의 1의 전력으로 동일한 성능을 낼수 있는 시스템 설계가 가능해진 것. 이후 HPC 벤더들은 페르미 기반의 테슬라로 HPC를 설계하기 시작했고, 마침내 이정표를 찍는 결과물이 발표된다. 중국의 국방과학기술대학(National University of Defense Technology, NUDT)에서 인텔 CPU 14,336개와 엔비디아의 테슬라 7,168개를 사용하여 린팩(LINPACK) 벤치마크 기준 2.507 페타플롭이라는 세계 신기록을 세우면서 엔비디아의 페르미 아키텍쳐의 우월성을 글로벌적으로 강하게 어필하게 된다. 이러한 성능은 단순 CPU만으로 설계할 경우 5만개 이상의 CPU와 2배의 사용 공간, 12메가와트의 전력소모를 필요로 하지만, 다수의 CPU와 GPU의 헤테로지니어스 조합(Heterogenious=이종 혼합)으로 엔비디아가 앞서 밝힌 코스트 절감 대비 높은 와트당 퍼포먼스의 실현과 공간의 활용성까지 정확하게 입증하게된 셈이다. 세계 슈퍼컴퓨터 성능·순위 공개 사이트인 탑 500(top500.org)에 따르면 현재 글로벌 1위인 중국의 티엔허 1-A, 3위 중국의 네뷸리, 4위 일본의 츠바메등등, 엔비디아가 페르미를 발표한 이후 현 최고 순위에 계속해서 페르미기반의 테슬라로 구축된 HPC가 순위에 랭크되고 있고, 이미 많은 HPC벤더들이 엔비디아의 테슬라를 도입한 HPC를 설계하고, 연이어 발표하면서 엔비디아의 HPC 시장, GPGPU 시장에서의 경쟁력이 급상승하고 있다. 또 한가지 흥미로운 부분은 글로벌 OS 시장의 패권을 쥐고 있는 미국 마이크로소프트가 차기 윈도우즈에서는 ARM의 프로세서에서도 동작이 가능하게 만든 다는 발표를 한 뒤, 엔비디아는 코드명 "프로젝트 덴버"를 발표하고, GPGPU의 야심찬 비전을 구상하고 있다는 점. 코드명 "프로젝트 덴버"는 인텔과 AMD가 CPU와 GPU를 하나로 융합한 퓨전 프로세서로 이행하고 있는 것과 같이, 자사의 테그라에 포함된 ARM CPU와 대량의 병렬 지포스 GPU를 하나로 융합한 퓨전 프로세서를 선보이겠다는 것. 이러한 강력한 프로세서로 윈도우즈를 기반으로한 개인용 데스크탑 슈퍼컴퓨터, 워크스테이션, 서버 시장으로 시장 영역을 넓혀 가는 것과 동시에 GPGPU의 활용 영역도 점차 확대시키겠다는 계획이다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
▲ 엔비디아 테그라 아키텍쳐 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
엔비디아의 테슬라와 함께 모바일 시장 타겟의 테그라(System on chip=단일 칩 시스템) 도 현재 태풍의 눈으로 부각되고 있다. 테그라는 ARM의 CPU와 엔비디아의 GPU를 주축으로 이미지 프로세서, 비디오 프로세서등 구체적인 용도에 따라 여러개의 유닛을 하나의 칩에 담은 이종 혼합 아키텍쳐를 의미한다. 모바일 시장에서 현재 급격한 성장을 거듭하고 있는 스마트폰 시장은 초기 라이트한 웹서핑이나 음악감상, 2D 게임, 저퀄리티의 비디오 재생등이 가능했지만 시장의 성장과 요구에 따라 PC에서나 가능했던 3D 게임이나 HD 비디오등이 보편화 되면서 더 높은 성능의 하드웨어를 필요로 하게 된다. 이에 엔비디아는 자체 CPU 기술은 없지만 자사가 보유하고 있는 지포스 GPU의 높은 성능을 모바일 시장에 보다 유연하게 투입하기 위해 구제적인 용도를 갖고 있는 여러개의 유닛을 하나의 칩으로 설계한 테그라를 구상한것.(테그라에 탑재된 프로세서는 영국 ARM의 라이센스) 초기 스마트폰 시장에서는 앞서 밝힌 대로 높은 하드웨어를 필요로하는 어플리케이션보다는 단순한 인터넷이 주용도였고, 라이트한 게임이나 어플리케이션이 대부분이었기 때문에 엔비디아의 테그라가 확실하게 우위성을 발휘할 만한 기회가 없었다. 그러나 시장의 성장과 요구에 의해 스마트폰은 언제 어디서나 PC와 같은 활용성을 가진 휴대형 PC와 같은 의미가 되면서 일반 PC와 같은 능력을 스마트폰에 구현해야 하는 시대가 도래한다. 더 높은 퍼포먼스, 더 높은 와트당 성능, 마치 일반 PC시장의 CPU와 GPU의 경쟁 구도와 같이 현재 모바일 하드웨어의 시장도 같은 순환 구조를 나타내고 있고, 모바일 시장의 리딩 이노베이터로써 인텔과 같은 입지라고 볼수 있는 영국 ARM은, 최초 싱글 코어 프로세서에서 최근에는 듀얼코어, 향후 쿼드코어 기술까지 발표한 상태로 모바일 하드웨어 성장을 견인하고 있다. 또, 스마트폰 시장과 양대산맥을 구축하기 시작한 신흥 카테고리 태블릿시장까지 모바일 열풍을 증폭시키면서 모바일 하드웨어 시장은 빠른 성장을 나타내고 있다. 이러한 상황에 따라 모바일 CPU의 성장과 더불어 더 높은 그래픽 처리능력이 요구되면서 지포스로 널리 알려진 엔비디아는 이러한 시장 변화가 경쟁력을 상승시키고 있다. 엔비디아가 최근 듀얼코어 ARM CPU를 탑재한 테그라2를 발표한 뒤 도시바, 델, 모토로라, LG전자, 삼성전자등의 주요 디바이스 업체들이 테그라2를 도입한 각각의 스마트폰이나 태블릿, 넷북을 연이어 발표하면서 테그라의 가치성이 입증되고 것. 또, 엔비디아는 향후 자사의 CUDA 기술을 모바일 디바이스에도 적용시켜 스마트폰이나 태블릿등, 모바일 디바이스에서의 멀티미디어/고급 어플리케이션의 성능이나 기능을 큰폭으로 향상시킬 계획을 갖고 있다. 이것은 모바일 CPU의 집약적인 처리를 GPU를 이용한 병렬처리를 가능하게 하면서 디바이스 자체의 성능을 향상시키는것과 동시에 더 많은 활용성을 구축하고, 더 나아가 테그라의 모바일 시장에서의 경쟁력 보다 강화하는 것. 젠슨 황은 향후 1~2년안에 CUDA를 적용한 모바일 기기를 실현할 수 있고, 이것이 실현되면 예를 들어 스마트폰의 카메라로 와인의 병을 식별하여 클라우드 베이스의 서비스에 액세스 하고, 그 와인에 관한 제조년이나 해당 시기의 지식, 혹은 온라인 샵의 가격 정보등를 확인하거나, 스마트폰의 카메라로 보이는 전세계의 모든 정보를 파악할 수 있는 시대가 도래할 것이라고 IDG와의 인터뷰에서 밝혔다. 향후 CUDA가 적용된 모바일 기기가 등장하고, 이를 활용할 수 있는 어플리케이션과 연계가 되면 테그라는 테그라가 탑재되지 않은 기기와 확실한 활용적 우위성을 확보할 수 있기 때문에 CUDA의 모바일 기기 적용도 주목되는 부분중 하나다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
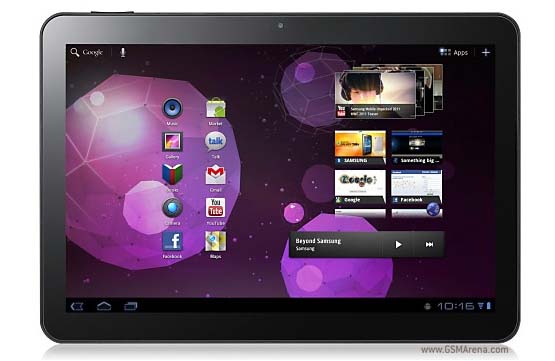
▲ 엔비디아 테그라2가 탑재된 삼성전자 갤럭시탭10.1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2011년 1월의 라스베가스에서 개최된 CES(Consumer Electronics Show), 2011년 2월 스페인에서 개최된 MWC(Mobile World Congress)에서 엔비디아의 테그라를 탑재한 모바일 디바이스가 연이어 발표되면서 테그라는 매우 익사이팅한 시기를 맞이하며 순항이 계속되고 있고, MWC에서 엔비다아는 현행의 테그라2 보다 5배 빠른 쿼드코어 프로세서의 칼-엘의 샘플 칩을 공개 시연, 2012년 이후의 웨인, 로건, 스타크 SOC까지 테그라의 로드맵을 발표하면서 모바일 시장에서 테그라의 확실한 비전을 제시했다. 이처럼 엔비디아는 페르미 발표 이후 GPGPU 시장 및 모바일 시장에서의 경쟁력 강화로 자사의 비전을 구축해 나가고 있고 현재까지는 순항이 계속되고 있다. AMD와 인텔의 퓨전 프로세서(APU)로의 플랫폼 전환, AMD의 GPU 시장에서의 강한 압박에 불투명했던 자사의 비전을 GPGPU 범용 컴퓨팅, 모바일 시장에서 활로를 개척하기 시작하면서 주춤했던 역량을 다시 강화하고 있는것. 종합적으로 이번 GPU 시장 분석 PART.5는 주로 엔비디아의 시점으로 내용을 다루면서 엔비디아가 PC 시장 외의 다양한 방면으로 활로를 개척하고 적극적으로 움직이고 있다는 점을 확인할 수 있었다. 앞으로 전개될 인텔과 AMD의 퓨전 프로세서(APU)의 시장 정착, 이에 대응하는 엔비디아의 Answer, AMD와 엔비디아의 GPU 경쟁 상황, 또 이와 관련된 부수적인 내용들은 GPU 시장분석 PART.6에서 다루도록 한다. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
- GPU 시장 분석 PART.6에 계속- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
RAPTER | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||










4월 26일 (금) 오전 1:51
|
|
|
|
||
|
||
|
||
|
|
||
|
||
|
|
||
|
2010.12.19 16:51
GPU 시장 분석 <Chaos / take off> by_페르미 아키텍처
조회 수 62755




















|
|
페르미가 전기먹는 괴물인줄만 알았는데,,, 읽고 보니 엄청난 물건으로 보입니다.