SSD에서 클라우드 : 스토리지 저장매체의 발전과 데이터 활용 특성
2014년도 IDC Report에 따르면 향후 생성될 디지털 정보는 매년 42.5%씩 늘어나고 2017년에는 125 Exabytes에
이른다고 하며 요새 Petabyte나 Exabyte 같은 단위가 그리 낯설게 들리지 않는 것을 보면 기업이 든 개인이든 폭발적으로 늘어나는
데이터를 어떻게 관리하느냐가 초미의 관심사임에는 틀림 없다. 이를 증 명하듯 비즈니스 SNS인 링크드인에서 조사한 바로는 2014년도 구인
기업에게 가장 각광받았던 기술에서 스토리지 관리 부분이 당당 3위를 차지하기도 하였다. 이렇게 생성되는 데이터가 늘어나는 만큼 스토리지 시 스템
기술도 발전을 이루어 왔고 그 중심에는 스토리지 시스템에서 실제 데이터가 저장되는 저장매체의 발 전이 매우 크게 기여 했음에 의심의 여지가
없다.
인류 최초의 기계적인 스토리지 저장 매체는 바로 1800년대 초반에 직물을 짜는 기계에서 사용한 천공카드 였다고 한다.
천공카드에 일정 패턴으로 천공을 뚫으면 베틀이 그 패턴 그대로 직물을 짤 수 있었다고 하며 여 기서 아이디어를 얻어 1800년대 후반 전기적으로
천공을 인식하여 몇 개의 카드에 저장된 숫자를 테이블로 만들어 내는 시스템이 만들어졌다는 것이다.
다음으로 나온 저장매체가 마그네틱
테이프이며 1951년도에 발표된 최초의 상업용 컴퓨터인 유니벡 (Univac)-1에 저장용 스토리지로 사용되었고 그 이후 현재까지 컴퓨팅 산업의
발전과 함께 저장 매체도 마 그네틱 테이프에서 마그네틱 디스크 그리고 최신의 Flash 반도체 기술에 기반을 둔 SSD(Solid State
Drive) 에 이르기까지 눈부신 발전을 함께 이룩해 왔다.
그럼 여기서 우리는 폭발적으로 늘어나는 데이터를 어떤 저장 매체에
저장하여야 하는가를 고민하지 않을 수 없다. 아직도 SSD는 Disc 대비 수십 배 비싼 솔루션이며 그 SSD 내부에서도 가격과 성능 차이가
수배에 이르기 때문이고 결국 좋은 성능은 그만큼 높은 비용을 지급하게 만들기 때문에 스토리지 시스템에 저장될 데이터의 활용 특성에 대해서
이해하는 것이 매우 중요하다 하겠다.
이 부분의 설명을 돕기 위하여 스마트폰을 예로 들도록 하겠다. 일전에 어떤 연예인이 자신의
스마트폰에 3,500명의 연락처가 저장되어 있다고 얘기하는 걸 들은 적이 있는데 그럼 그분은 이 3,500명의 연락처라는 데이터를 어떤 식으로
활용하고 있을까? 이분이 3,500명 모두에게 같은 주기로 똑같이 연락하지는 않을 거 라 생각된다. 이를테면 하루에 10명씩 매일 통화하면
1년에 한 번은 3500명 모두와 연락을 취할 수 있다. 하지 만 이런 식으로 데이터(여기서는 연락처)를 활용하는 경우는 거의 없을 것이다.
연구에 따르면 데이터의 활 용은 반드시 특정 데이터군에 대해 집중되며 이러한 부분을 데이터 활용 특성 (Data skew 또는 Data
access pattern)이라고 얘기한다
즉 100번 전화를 시도 한다고 할 때 Data skew가 88%이면 하면 90번은
3,500명 중 180명 이내의 사람들에 게 전화가 간다는 것이고 Data skew가 33%이면 100번의 전화통화중 80번은 3,500명 중
1,155명 중에 간다 는 것을 뜻한다. 이것은 같은 데이터라도 그 데이터를 사용하는 사람에 따라 달라지는데 이를 IT 솔루션으로 설명하면 어떤
애플리케이션이냐 따라 그 Data skew가 달라진다
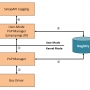
밑의 [그림1]은 이러한 애플리케이션 별 데이터 활용 특성을 그래프로 설명하고
있다. 그림 아래쪽의 기타 App은 클라우드 솔루션으로 사진을 공유하는 Internet Service Provider의 1년간의 사진 활용
특성이며 이 는 사용자가 1년 동안 찍은 사진을 다시 볼 때 80%는 지난 3개월에 집중된다는 것을 의미한다. 이러한 특성 을 이 사업자가
이해하고 적절하게 사용할 수 있다면 엄청난 스토리지 비용을 절감할 수 있다. 예를 들어 자주 보는 지난 3개월간의 사진은 가장 성능이 좋은 -
이를테면 - SSD에 저장해서 빠른 응답 속도를 제공하고, 나 머지 9개월 사진은 더 느린 응답 시간에 계약조건을 단 후 원격 Cloud
storage에 저장하는 것이다. 데이터 활 용 특성을 무시하고 모든 데이터를 SSD에 담는 것보다 수십 배의 비용 절감이 가능할 것으로
예상된다.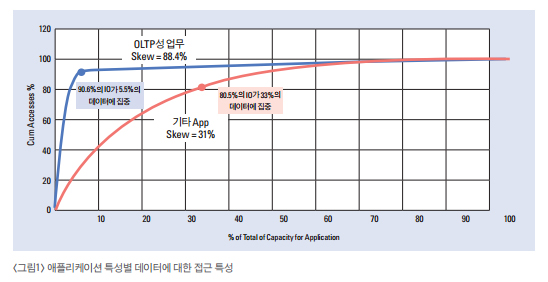
그런데
이러한 데이터 사용 특성은 개인보다는 저장 데이터가 무척 큰 기업 규모의 Structured Data에서 훨 씬 더 직관적이고 명확하게
적용된다. 어떤 기업이 지난 10년간의 고객의 주문 정보를 저장하고 있고 주문에 서 매출인식까지의 한 주기를 6개월이라 한다면 해당 6개월 치의
데이터는 자주 읽고 변경하며 활용하겠지만, 나머지 9년 6개월의 이미 마감이 된 주문 정보 데이터는 활용이 매우 낮을 수밖에 없는 것입니다.
[그림 1]에 서 OLTP성 업무의 Data skew 그래프가 이러한 데이터 활용 특성에 대해서 잘 설명하고 있다.
특히 OLTP성
Structured Data는 결국 Database에서 생성되는 것이고 Data의 생성과 저장은 향후 그 Data 의 효율적인 활용에 지대한
영향을 끼치게 되어 오라클에서는 12c부터 Heat map이라는 기능으로 기업이 가 지고 있는 DB Data의 Dataskew에 따라 block
단위로 Hot/Warm/Cold/Deep Archive로 구분하여 그 활 용 특성을 알도록 도와준다.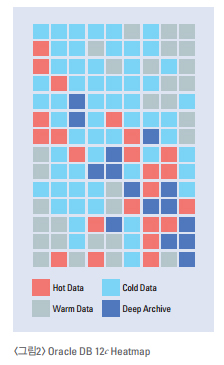
만약
이러한 대량의 데이터를 세부 데이터 활용 패턴을 무시하고 한 종류의 저장 매체 - 이를테면 고성능의 SSD에 모두 저장하는 것은 효율적인 자원
활용을 매우 어렵게 만든다. 이를테면 가장 높은 성능을 위하여 데 이터 사용 패턴을 무시하고 모든 데이터를 SSD에 담는다고 했을 때 우선 성능
때문에 SSD를 선택했으나 비 용 때문에 중저가 SSD를 선택해야 하는 모순에 빠지게 된다 - 앞에서 얘기했듯이 같은 SSD라 하더라도 그
종류에 따라 가 격과 성능이 천차만별이기 때문이다. 그리고 성능 때문에 SSD 를 선택했으나 저장 용량을 줄이기 위하여 중복제거 같은 오 히려
스토리지 시스템의 IOPS 성능을 저하시키는 기능도 함 께 사용되어야 하는 아쉬움이 있는 것이다.
결국 특히 대량의 데이터를 가지고
있는 기업 입장에서 가장 이상적인 방법은 빠른 응답을 해야 하는 소량의 데이터를 최 고 성능의 반도체 기반의 저장 매체에 저장하고 활용이 떨어
지는 대량의 데이터는 저비용의 HDD나 테이프 시스템 및 Cloud에 분산하며 각 매체 간의 유연한 데이터 이동을 가능하 게 할 관리 시스템을
채택했을 경우 가장 뛰어난 투자 대비 성 능 개선 효과를 볼 수 있을 것이며 특히 이를 위하여는 애플리 케이션과 온프레미스 스토리지 시스템에서
Clould에 이르기 까지 서로 능동적으로 이러한 Data 활용 특성에 대한 정보를 공유하고 그에 맞는 스토리지 tier를 선택할 수 있도록
공동 개발되는 것이 가장 중요한 것이다. 왜냐하면, 설 사 DB에서 Heatmap으로 Data 특성에 대해 구분되었더라도 밑단의 스토리지
시스템이 이 패턴을 이해하지 못한다면 이러한 기능은 무용지물이기 때문이다.
따라서 기업 고객의 경우 이러한 Data의 생성과 저장
그리고 백업 및 Archiving에 이르기까지 Data의 한 생 애 주기에 대한 깊은 이해로 소프트웨어와 하드웨어를 Co-engineering
할 수 있는 솔루션 공급업체를 선택 하는 것이 매우 중요하다고 할 수 있겠다.