





















![[정종철] 뚜따에 진심인 형+과학자코스프레+현미경을구입했어
CPU 뚜따 교육자료ㅋㅋ](https://raptor-hw.net/xe/files/thumbnails/739/203/241x165.crop.jpg "뚜따에 진심인 형+과학자코스프레+현미경을구입했어")


’ 오픈")













인텔이 새로운 아키텍쳐로 전환하게 된 이유는 그동안의 기술이 한계에 도달했기 때문이라는 의견이 지배적이다. 펜티엄4 CPU가 사용하던 넷버스트 아키텍쳐는 인텔이 선택한 고육지책이었다. 현재 우리가 사용하고 있는 모든 펜티엄4 및 펜티엄D, 펜티엄 익스트림 에디션 CPU는 넷버스트 아키텍쳐가 적용되어 있다.
넷버스트 아키텍쳐가 도입될 무렵, 그러니까 펜티엄4 CPU가 세상에 등장할 즈음 인텔은 P6 아키텍쳐 기반 프로세서들에 많은 한계점을 느끼고 있었다. P6 아키텍쳐는 펜티엄 프로부터 펜티엄 II, 펜티엄 III CPU까지 적용된 아키텍쳐이다. 즉, 펜티엄 프로, 펜티엄 II, 펜티엄 III CPU 들은 제조 공정이나 클럭, 캐쉬 등의 차이만 있을뿐 같은 아키텍쳐를 사용한 CPU들이었다.
당시 충격과도 같았던 일대 사건이 일어났는데, 언제나 후발주자에 머물러있던 AMD가 인텔보다 먼저 1GHz의 벽을 돌파한 것이었다. 언제나 신기술을 선도하던 인텔의 자존심에는 금이 갔지만, 기존의 P6 아키텍쳐가 가진 한계로 인해 인텔은 굉장한 어려움에 봉착하게 된다. 인텔 펜티엄 III 1.13GHz 리콜 사건은 이 어려움을 증명하는 단적인 예라 할 수 있다. 즉, P6 아키텍쳐 기반의 CPU로는 더이상 경쟁을 할 수 없음을 인텔 스스로도 깨닫고, 그 아픔을 바탕으로 높은 클럭으로의 야망을 꿈꾸게 된다.
CPU의 성능은 두가지에 의해 결정되는데, 첫번째는 CPU의 클럭을 높이는 것이며, 두번째는 클럭당 처리할 수 있는 처리량을 늘리는 것이다. 인텔 펜티엄4 CPU에 적용된 넷버스트 아키텍쳐는 첫번째 방법을 택했다. 즉, CPU의 클럭을 높여 CPU의 성능을 높이고, AMD에 빼앗겼던 선두 주자의 자리를 가져오려 했던 것이다.
인텔은 CPU 클럭을 높이기 위해 넷버스트 아키텍쳐가 적용된 펜티엄4 CPU에 어마어마한 파이프라인 처리 구조를 도입했다. 기존의 P6는 10 단계의 파이프라인으로 명령을 처리했지만, 새로운 펜티엄4 CPU는 20 단계의 파이프라인으로 명령을 처리했다. 파이프라인이 늘어날 수록 명령의 단계가 세분화되고 클럭이 높아지게 되는데, 펜티엄4 CPU는 단숨에 1.4GHz, 1.5GHz의 속도로 시장에 등장했다.
그러나 세분화된 파이프라인은 큰 결점을 가지고 있었는데, 기존 펜티엄 III(P6 아키텍쳐) CPU가 하나의 파이프라인에서 처리하던 명령을 펜티엄4에서는 두개 이상의 파이프라인을 통해 처리할 수 밖에 없었다는 것이었다. 따라서 새로운 아키텍쳐가 적용되어 시장에 출시됬던 펜티엄4 1.5GHz가 기존 펜티엄 III 1.3GHz보다 실제 성능에서는 느린, 웃지 못할 상황이 벌어졌다.
그로부터 5~6년이 지난 지금까지 인텔은 엄청난 무리수를 두었다. 인텔 CPU의 파이프라인은 31 단계까지 늘어났다. 속도의 향상을 위해 파이프라인을 점점 늘렸던 것은 인텔에 자충수가 되었다. 초기 180nm 공정에서 130nm, 90nm, 65nm로 제조 공정을 개선했음에도 불구하고 3.0GHz를 돌파했던 펜티엄4 프레스캇 코어는 무지막지한 열을 내뿜으며, 인텔의 골치거리로 돌변했다. 당시 일부 유저들은 심한 발열로 인해 프레스캇 코어의 펜티엄4가 리콜되어야 한다고 공공연히 이야기할 정도였다.
극심해지는 발열과 함께 마치 수레의 양쪽 바퀴처럼 펜티엄4 넷버스트 아키텍쳐를 따라다녔던 것은 극심한 전력 소모량이었다. 앞서 말한 대로 전력의 소모를 줄이기 위해 공정을 개선했음에도 불구하고 동작 클럭을 높여가기 위해서는 점점 많은 전력을 들이대야 했다.
결국 최근에 들어서는 L2 캐쉬를 늘리고 두개의 코어를 붙이는 듀얼 코어 제품인 펜티엄D 시리즈를 내놓았지만, 넷버스트 아키텍쳐가 가지고 있던 단점들은 여전히 존재했다. 듀얼 코어와 L2 캐쉬의 도입에 있어서도 인텔은 L2 캐쉬를 분리했다 다시 공유했다하는 혼선을 거쳤다.
물론 넷버스트 아키텍쳐가 기존의 P6 아키텍쳐에 비해 가지는 장점들이 많이 있었지만, 결국 펜티엄4에 적용된 넷버스트 아키텍쳐는 '속도의, 속도에 의한, 속도를 위한' 아키텍쳐였다는 것에 반기를 들 사람들은 없을 것이다. 현재의 넷버스트 아키텍쳐 기반의 CPU들은 두개의 짐을 양손에 들고 걸어서 목적지에 도착하는 똑똑한 일꾼이라기 보다는, 한개의 짐만을 한손에 들고 열심히 뛰어서 두번 나르는 힘만 센 무식한 일꾼이라 해도 과언은 아닐 것이다.
이제 새로운 코어 아키텍쳐가 이전에 비해 어떤 특이점이 있으며, 어떤 신기술이 도입되었는지를 자세히 알아보자. 인텔이 코어 아키텍쳐를 내놓으며 선보인 5개의 신기술 중 Intel Wide Dynamic Execution은 클럭당 처리되는 명령의 처리량을 늘리는 방법에 관여된 것이며, Intel Advanced Digital Media Boost는 명령의 처리량을 감소시키는 방법에 관여된 것이다. 여기에 부가적으로 각 코어의 캐쉬를 공유하는 기술인 Intel Advanced Smart Cache, 메모리와의 데이터 이동의 방법을 개선해 성능의 향상을 꾀한 것이 Intel Smart Memory Access이며, CPU의 전력 소모를 줄인 기술이 Intel Intelligent Power Capability이다.
앞서 도입부에서 CPU의 성능을 결정짓는 두가지에 대해 잠시 언급했다. 첫번재는 우리가 흔히 2GHz, 3GHz로 말하는 CPU의 클럭 주파수이며, 두번째는 클럭당 처리되는 명령의 처리량(IPC;Instruction per Clock)이다. CPU의 클럭이 높아지거나 클럭당 처리되는 명령의 처리량이 늘어나면 CPU의 성능은 높아진다.
이전 넷버스트 아키텍쳐가 클럭 주파수를 높여왔다면, 새로운 코어 아키텍쳐는 클럭당 처리되는 명령의 처리량을 높였다. 클럭당 동시에 처리될 수 있는 명령어를 이전 3개에서 4개로 늘려 코어 아키텍쳐에서는 한클럭에 최대 4개의 명령어를 동시에 처리할 수 있다. 이것이 바로 인텔이 이야기한 코어 아키텍쳐의 신기술인 Intel Wide Dynamic Execution의 주요 내용이다.
아래 그림은 Intel Wide Dynamic Execution의 도식이다. 이전에 넷버스트 아키텍쳐에서 사용되었던 Advanced Dynamic Execution은 3개의 명령어를 동시에 처리할 수 있었으나 코어 아키텍쳐에서는 4개의 명령어를 동시에 처리할 수 있다. 인텔의 코어 아키텍쳐는 파이프라인의 단계가 줄인대신 아래와 같이 각 실행 유닛을 넓히므로써 처리되는 명령어의 처리량을 높였다.
실행 유닛을 넓히는 것 이외에도 실행 시간을 단축 시키기 위해 매크로퓨전(Macrofusion)이라는 기술을 도입했다. 매크로퓨전은 두개의 특정 조건을 갖춘 명령어를 하나의 명령어로 처리하는 기술이다. 즉, 기존의 아키텍쳐에서는 이런 특정 조건을 갖춘 명령어 두개가 일렬로 실행되어야 할 경우 각 명령어를 한번에 하나씩 처리했지만, 새로운 코어 아키텍쳐에서는 이런 조건이 일어날 경우 한번에 두개를 동시에 처리할 수 있어, 같은 시간에 더 많은 명령을 처리할 수 있다.
매크로퓨전은 특정 조건의 명령이 들어올 경우 같은 시간에 더 많은 명령을 처리할 수 있는데, 이는 곳 실행 시간을 단축시키기 때문에 결국 같은 명령을 처리하는 데 드는 전력도 줄일 수 잇는 장점이 있다. 아래 그림을 보면 하늘색으로 표시된 부분이 매크로퓨전이 적용되는 명령의 예인데, 이전 세대 아키텍쳐에서는 같은 하늘색의 명령이 따로 처리됬지만, 코어 아키텍쳐에서는 같은 하늘색(일정 조건을 만족한)의 명령은 하나로 처리된다.
또 인텔은 코어 아키텍쳐의 Wide Dynamic Execution을 통해 펜티엄 M 프로세서에 최초로 도입되었던 마이크로 연산 퓨전(Micro-op fusion) 기능을 확장했다. 이는 코어 아키텍쳐에서 융합될 수 있는 마이크로 연산이 더 많아진다는 것을 의미하며, 매크로퓨전으로 인해 파생된 융합 가능한 많은 수의 마이크로 연산을 융합해 마이크로 연산의 개수를 감소시킨다. 이로 인해 인텔은 이 기능의 확장으로 마이크로 연산의 기능을 10% 이상 감소시킬 수 있다고 이야기하고 있다.
이외에 CPU의 성능을 올리는 또하나의 방법이 있다면, 처리해야할 명령의 처리량을 감소시켜 동일 시간에 더 많은 명령을 처리하는 것이다. 우리가 PC로 동영상을 볼때를 생각해보자. 동영상을 같은 그림이 좌표를 바꿔 움직이는 명령어의 집합이라 한다면, CPU는 언제나 같은 명령을 좌표만 바꿔 처리할 것이다. 이 경우, 각 명령을 따로 실행하지 않고 한꺼번에 처리하면 명령의 처리량이 감소한다. 이를 SIMD(단일 명령 복수 데이터 ; Single Instruction Multiple Data)라고 하며, 우리가 흔히 봐왔던 MMX, SSE, SSE2 등이 이 SIMD의 일종이다.
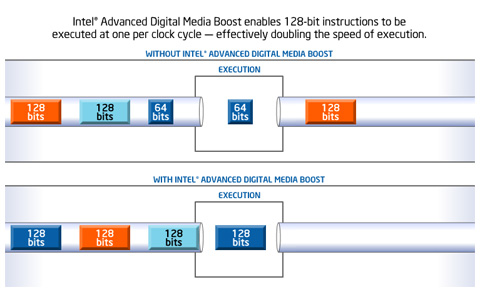
Intel Advanced Digital Media Boost는 SSE(Streaming SIMD Extention)의 처리 성능을 높이기 위해 128비트 SIMD 정수 연산과 부동소숫점 연산 명령을 한 클럭에 실행할 수 있게 한 기술이다. 이전 아키텍쳐의 경우 128비트의 명령을 64비트로 나누어 처리했지만, 코어 아키텍쳐에서는 128비트의 명령을 한번에 처리할 수 있다.
아래 도식을 보면 같은 128비트 SIMD 연산시 Intel Advanced Digital Media Boost가 적용되는 경우와 적용되지 않는 경우가 차이를 보인다. SIMD는 언제나 128비트만 처리되는 것이 아니라 64비트와 128비트가 혼재되어 처리된다. 이럴 경우 같은 클럭당 처리하는 용량은 같지만 Intel Advanced Digital Media Boost는 128비트의 연산을 하나의 클럭에 완벽히 처리해주기 때문에 처리되는 명령어 수를 증가시킨다.
128비트 SIMD 연산은 그래픽이나 비디오, 오디오 같이 같은 연산이 반복되는 작업시 그 효과가 나타난다. 앞으로 그래픽과 동영상이나 멀티미디어 파일의 크기가 점점 늘어나기 때문에 이를 효과적으로 처리할 수 있는 기술은 더욱 그 중요성이 더해진다.
Intel Wide Dynamic Execution과 Intel Advanced Digital Media Boost가 CPU 내부의 명령 처리를 개선해 CPU의 성능을 높이는 기술이었다면, Intel Advanced Smart Cache 기술과 Intel Smart Memory Access 기술은 CPU 내부의 직접적인 명령 처리 이외의 기술이라 할 수 있다.
일반적으로 L2 캐쉬의 용량은 CPU의 성능에 직접적인 영향을 미친다. CPU는 계산기이고, 메모리와 하드디스크는 데이터를 저장하고 있는 저장창고이다. CPU가 계산명령을 받으면 데이터를 가져오기 위해 메모리나 하드디스크를 찾겠지만, 이보다 앞서 캐쉬 메모리에서 데이터를 찾는다. 먼저 L1 캐쉬에서 데이터를 찾고, 여기에 없으면 L2 캐쉬에서, 여기에도 없으면 메모리에서 찾게 되고, 이도 아니면 결국 가장 느린 하드디스크에서 데이터를 찾는다.
즉, L1 캐쉬와 L2 캐쉬는 메모리와 CPU 사이에 버퍼 역할을 하는 완충 장치라 할 수 있다. CPU의 속도에 비하면 현저히 느린 메모리나 하드디스크의 자료를 L1 캐쉬나 L2 캐쉬에 올려놓고 여기에서 먼저 처리하면 더욱 바른 연산이 가능한 원리이다.
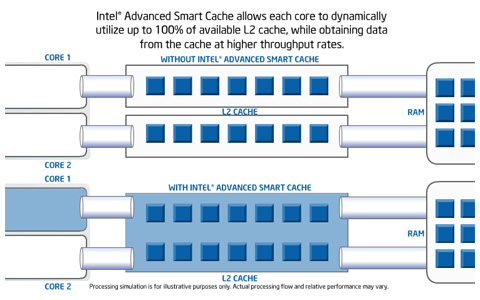
Intel Advanced Smart Cache 기술은 듀얼 코어 CPU의 L2 캐쉬의 구분을 허물어 L2 캐쉬를 공유할 수 있게 하는 기술이다. 기존 아키텍쳐의 경우 L2 캐쉬의 공유가 불가능했다. 한쪽의 L2 캐쉬에 많은 부하가 걸릴 경우에도 다른 한쪽의 L2 캐쉬는 전혀 도움이 되지 않는다. 한쪽의 CPU가 다른 한쪽의 L2 캐쉬에 접근하는 것이 원천적으로 차단되어 있기 때문이다.
그러나 인텔은 코어 아키텍쳐에서 이 L2 캐쉬간의 장벽을 허물었다. 즉, 듀얼 코어 CPU가 각 코어마다 2MB의 캐쉬를 가지고 있더라도, 하나의 코어가 총 4MB의 캐쉬를 마음대로 이용할 수 있기 때문에 L2 캐쉬에 더 많은 데이터를 로드할 수 있게 되고 이로 인해 캐쉬에서 데이터를 가져오는 비율이 증가해 전체적인 속도가 향상된다.
Intel Advanced Smart Cache와 관련해서는 다양한 이슈가 존재한다. L2 캐쉬를 공유해서 사용한다면, 듀얼 코어 CPU의 각 코어는 과연 얼마만큼의 데이터를 각각의 L2 캐쉬에 불러와야 하며 어떻게 콘트롤 되어야 하냐는 점이다. 아직 이에 대해 자세히 밝혀진바는 없지만, 향후 L2 캐쉬를 공유하면서 생기는 명령어의 복잡화도 충분히 생각해볼 수 있는 부분이다. 마치 다이렉트X 10이 지향하는 통합 쉐이더에서 각 쉐이더의 쓰임새를 관리하기 위해 많은 명령어 및 회로가 사용되는 것과 마찬가지이다.
향후 출시될 쿼드 코어(4개) 제품인 켄츠필드는 두개의 콘로 CPU가 모여 이루어진 CPU이다. 이 경우 켄츠필드의 경우 콘로 2개가 붙어있는 구조로 이루어지는데, 콘로 내에서는 L2 캐쉬가 공유되지만, 서로 다른 콘로끼리는 L2 캐쉬가 공유되지 않는다. 이에 대해 인텔의 개발자들은 켄츠필드 이후의 차기 쿼드 코어 제품에서도 콘로와 마찬가지로 4개의 L2 캐쉬가 모든 코어에 공유될 것임을 밝혔다.
Intel Smart Memory Access 기술은 메모리에서 데이터를 가져오는 시간을 최소화하여, 최대한 데이터를 빨리 가져올 수 있게 하고, 이와함께 데이터를 필요로하는 가장 가까운 위치에 저장하는 기술이다. 이 기술에는 메모리 명확화라고 명명된 중요한 기능이 있는데, 기존의 모든 저장 명령들이 실행되기 이전에 작동하려고 하는 명령어에 대비헤 데이터를 이론적으로 로딩할 수 있도록 내장형 지능을 실행 코어에 제공한다.
메모리 명확화와 함께 향상된 프리펫쳐도 이용된다. 프리펫쳐는 말 그대로 필요성이 제기되기 이전에 메모리에 담긴 데이터를 미리 읽어들이는 것이다. 이는 캐쉬와 메모리 사이에서 발생하는 로드 수를 증가시켜 메모리 대기 시간을 감소 시킨다.
듀얼 코어 CPU의 경우 개별 실행 코어가 필요로 하는 곳에 데이터를 전달하기 위해 코어 아키텍쳐에서는 L1 캐쉬와 L2 캐쉬 각각 한개당 두개의 프리펫쳐를 사용한다. 이 프리펫쳐들은 패턴을 감지해 정해진 시간에 실행될 수 있도록 준비시키며, L2 캐쉬의 프리펫쳐는 추후 코어가 필요로 할 수 있는 데이터의 요구에 대비하기 위해 코어의 활동을 분석한다.
분명 인텔은 코어 아키텍쳐를 통해 P6 아키텍쳐 시절의 기술의 한계와 넷버스트 시절에 두었던 무리수를 모두 만회하려 하고 있다. 특히, 인텔 코어 아키텍쳐가 적용된 CPU들은 듀얼 이상의 멀티 코어로의 전환에 매우 유리할 것이다.
인텔은 코어 아키텍쳐를 통해 앞으로 출시될 멀티코어 프로세서에 대해 매우 긍정적인 생각을 가지고 있는 것으로 보인다. 인텔의 마이크로 프로세서 연구원인 밥 크랩스는 인텔의 다중 코어 발전 방향에 대해 언급하였다. 밥은 현재 적지 않은 사용자들이 다중 코어 프로세서가 전력 소모가 많을 것으로 생각하고 있지만, 이 문제가 생각과는 다를 수도 있다고 말했다.
"이론상 듀얼 코어의 전압과 동작 속도가 85%까지 떨어지면 전체 소비 전력은 싱글 코어의 전력 소모량과 거의 같아진다. 그러나 듀얼 코어의 명령 처리량은 싱글 코어에 비해 약 1.8배가 되, 전체 소비 전력당 성능, 즉 와트당 성능이 높다. 물론 멀티 코어 프로세서가 단일 코어 프로세서에 비해 가격이 높지만, 공정의 발달이나 경제의 원리로 인해 이는 극복될 것이다. "라는 것이 밥 크랩스의 주된 생각이다.
인텔은 앞으로 듀얼 이상의 코어, 쿼드나 혹은 8개 이상의 코어가 합쳐진 CPU를 내놓게 될 것이며, 이들 CPU들은 위와 같은 원리로 와트 당 성능이 점점 높아지게 될 것이다. 인텔은 이런 CPU들을 아주 가까운 미래의 CPU로 생각하고 있는지도 모르겠다.
켄츠필드나 클로버타운은 기존의 콘로나 우드크레스트가 단순히 하나의 패키지 안에 들어있기 때문에 L2 캐쉬가 공유되지 않지만, 그 이후에 나올 쿼드 혹은 8개 이상의 코어 제품들은 L2 캐쉬를 공유하게 되면서 좀 더 멀티 코어에 최적화된 모습이 될 것이다.
이렇게 멀티 코어 CPU들이 발젼해가면 가까운 미래의 CPU들은 혼성 멀티 코어 구조(Heterogeneous Multi-Core Architecture)로 발전해 갈 것이다. 이는 단순히 동일한 코어 여러개를 하나의 다이에 넣는 구조가 아닌, 서로 다른 역할을 하는 여러 코어가 하나의 다이에 들어가 각기 제 맡은 역할을 하는 구조가 된다. 이렇게 되면 하나의 CPU안에 물리 연산을 위한 코어, 멀티미디어 재생을 위한 코어, 수치 연산을 위한 코어, 압축 해제를 위한 코어 등등이 제각기 자리 잡고 맡은 일을 처리하게 된다.
필자는 1995년 필자가 쓰던 마하64 그래픽 카드의 메모리를 1MB에서 2MB로 업그레이드하고 잠못잤던 때를 떠올렸다. 당시 "그래픽 코어도 CPU처럼 메인보드에 꼽아서 사용할 수 있으면 얼마나 좋을까, 사운드 프로세서도 CPU처럼 꼽아서 쓰다가 업그레이드 하면 될텐데..."하는 생각을 하곤 했다.
미래의 CPU는 과연 인텔이 바라는 그런 모습이 될까? 100%는 아니겠지만 현재로서 그런 미래의 CPU를 좌지우지 할 수 있는 가장 큰 주체는 인텔이며, 아마도 오늘 살펴본 코어 아키텍쳐는 그 미래의 CPU를 탄생시키기 위한 인큐베이터가 될 수도 있을 것이다.