





















![[정종철] 뚜따에 진심인 형+과학자코스프레+현미경을구입했어
CPU 뚜따 교육자료ㅋㅋ](https://raptor-hw.net/xe/files/thumbnails/739/203/241x165.crop.jpg "뚜따에 진심인 형+과학자코스프레+현미경을구입했어")





’ 오픈")










2019년 12월 2일~6일(현지시간) 미국 라스베이거스에서 "AWS re:Invent 2019" 행사가 진행됐다. 이 행사에서 AWS가 어필한 주요 내용을 살펴본다.
머신러닝=기계학습(ML:Machine Learning)영역에서 새로운 서비스로서 Web 베이스의 기계학습용 IDE(통합 개발 환경)로 Amazon SageMaker Studio가 발표됐고, SageMaker Studio와 여기에 통합되어 있는 수 많은 새로운 기능과 새로운 서비스가 소개됐다.
SageMaker는 2017년 re:Invent에서 발표된 기계학습 플랫폼으로 데이터 전문가 뿐만 아니라 일반적인 개발자도 기계학습을 취급할 수 있도록 해야 한다는 콘셉으로 SageMaker의 제공을 시작했다고 설명했다. 이후 AWS Marketplace와의 통합이나 모델 컴파일러 Amazon SageMaker Neo 추가 등 기능 강화를 진행해왔다.
"수 많은 고객들로부터 SageMaker로 인해 기계학습이 매우 쉬워졌고, 모든 스텝이 쉬워졌다고 평가받고 있으나 그와 동시에 각 스텝 간에 있는 작업, 처리가 잘 되고 있는지 아닌지를 이해하는 것은 아직 힘들다는 목소리가 들렸다. 그래서 소프트웨어 개발과 마찬가지로 엔드 투 엔드 통합 개발환경(=IDE)이 필요하다고 생각했다"
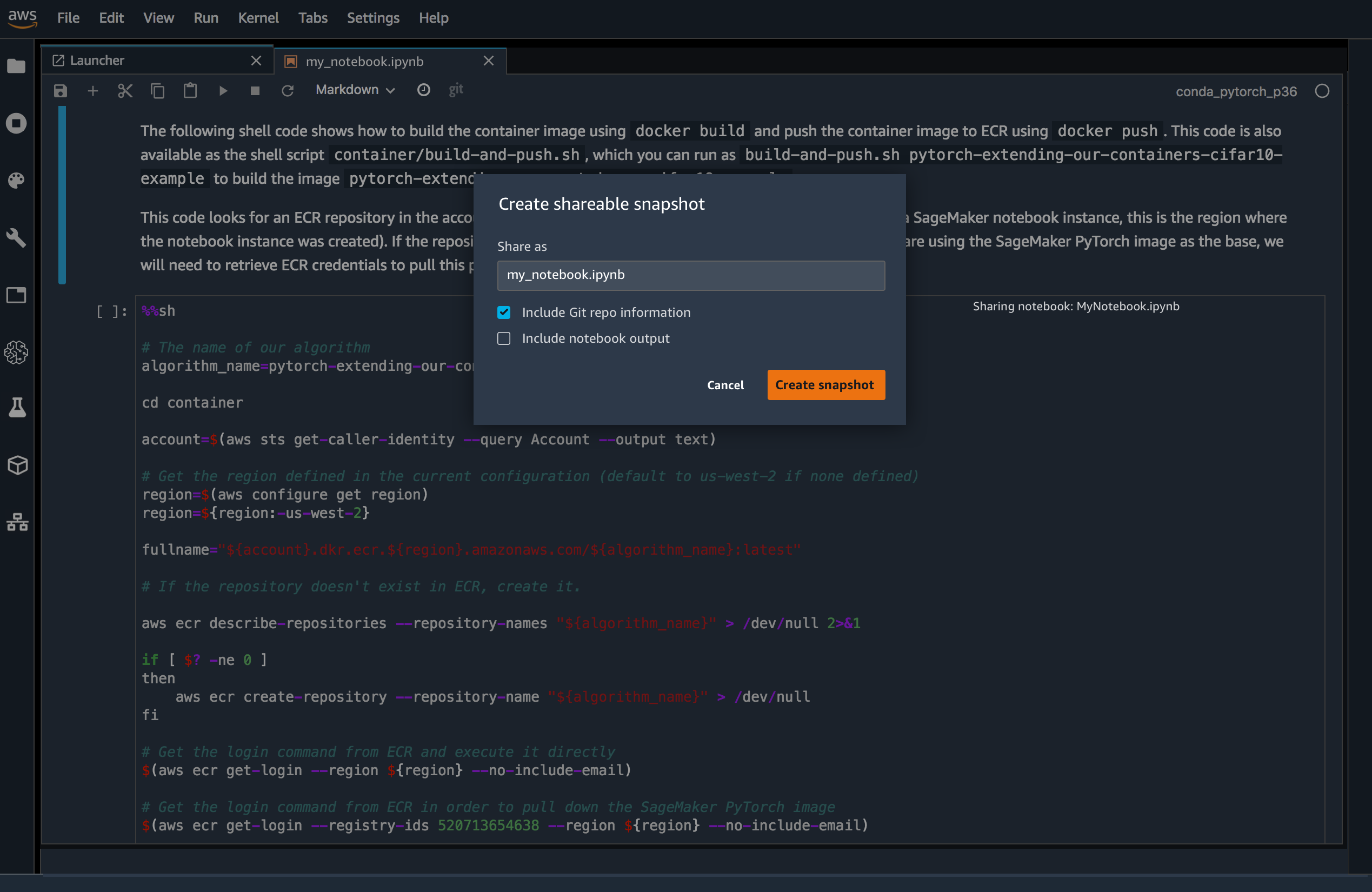
SageMaker Studio는 프로젝트 폴더를 작성하고 코드, Notebook, 데이터 세트, 세팅 등 기계학습 관련 자원을 한곳에서 통합 관리할 수 있다. 프로젝트 폴더 내 검색 뿐만 아니라 개발자간 공유하여 온라인 콜라보레이션도 가능하다. 빌드, 트레이닝, 튜닝, 디플로이도 같은 인터페이스에서 실행할 수 있으며 SageMaker Studio에 편입되어 있는 새로운 기능/새로운 서비스군도 발표되고 있다.
SageMaker Notebooks : Jupyter Notebook의 매니지먼트 서비스. AWS의 컴퓨터와 연동되어 있으며 SageMaker의 Notebook instance를 사용자 스스로 부팅하지 않고 몇 번의 클릭으로 새로운 Notebook을 작성할 수 있다. 더 필요한 처리 자원에 따라 작업의 중단 없이 인스턴스를 자동 스케일
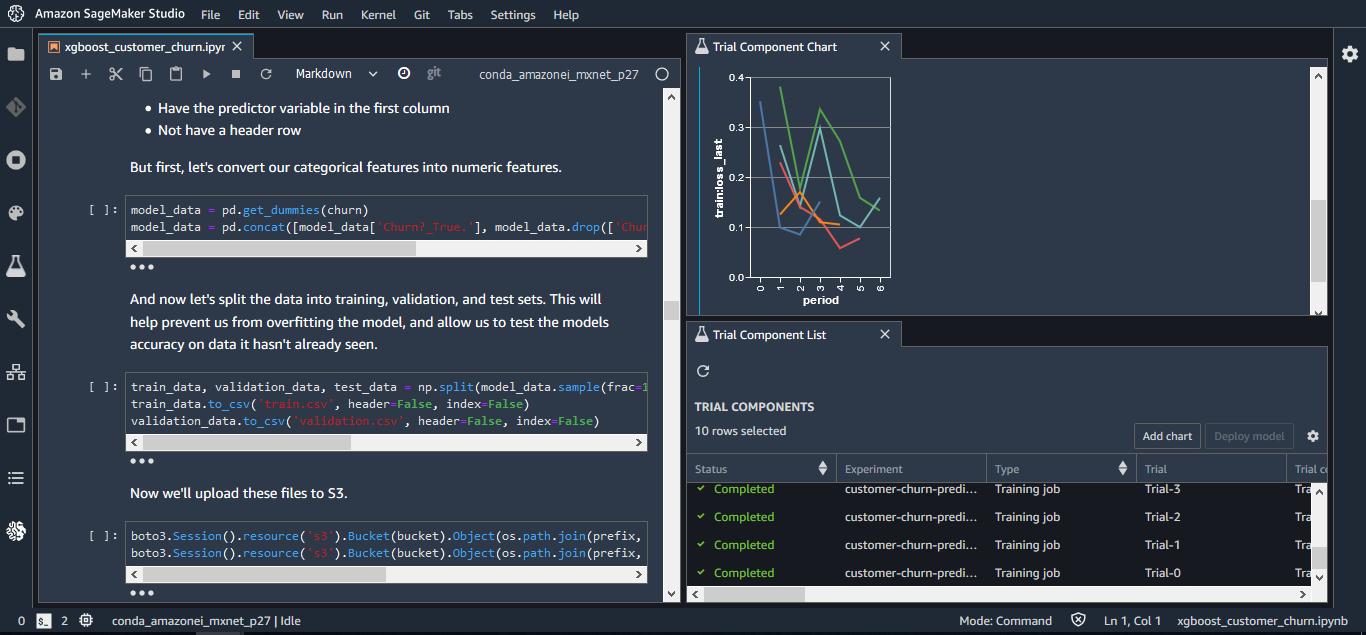
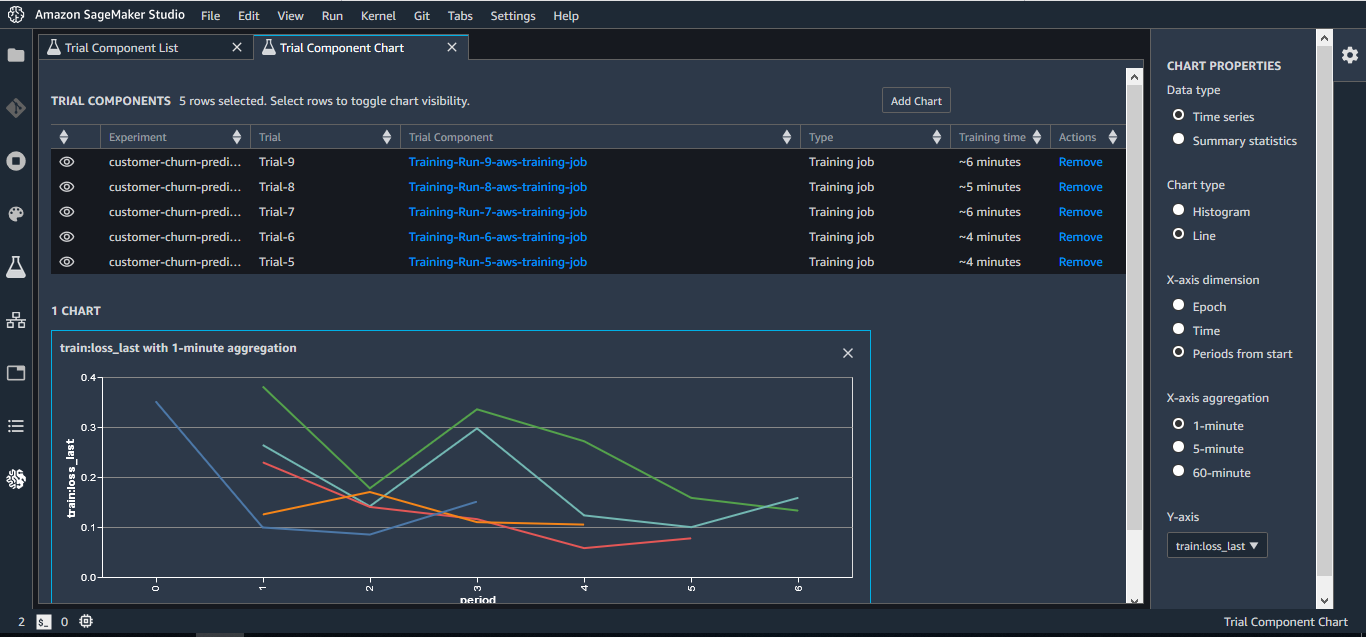
SageMaker Experiments : 트레이닝 데이터나 알고리즘, 파라미터, 플랫폼 구성 등을 변화시키면서 반복적으로 생성한 기계학습 모델의 전 버전에 대해 그 변수(설정)와 결과를 자동적으로 캡쳐하고, 어떤 것이 뛰어났는지를 비주얼하게 비교 검증 가능
SageMaker Debugger : 기계학습 모델의 트레이닝 코드를 위한 디버거 모델 내부의 Status를 출력함으로써 대량의 파라미터 중 어떤 것이 어느 정도 결과에 영향을 주고 있는지를 가시화, 모델의 최적화(예측정도 향상)를 지원한다. Tensor Flow, PyTorch, MXNet 등 주요 프레임워크용 SDK 제공
SageMaker Model Monitor : SageMaker Studio로 빌드하여, 실전 환경에 전개하고 있는 모델의 경년적, 외적인 환경 변화에 의한 예측 정확도 저하(콘셉 드리프트)를 감시한다. 정밀도 저하의 경보 뿐만 아니라 그 원인 특정에 도움이 되는 상세한 정보 제공

(예제)
Then, I upload it in Amazon Simple Storage Service (S3) without any preprocessing whatsoever.
sess.upload_data(path="automl-train.csv", key_prefix=prefix + "/input")
's3://sagemaker-us-west-2-123456789012/sagemaker/DEMO-automl-dm/input/automl-train.csv'Now, let’s configure the AutoML job:
- Set the location of the data set,
- Select the target attribute that I want the model to predict: in this case, it’s the ‘y’ column showing if a customer accepted the offer or not,
- Set the location of training artifacts.
input_data_config = [{
'DataSource': {
'S3DataSource': {
'S3DataType': 'S3Prefix',
'S3Uri': 's3://{}/{}/input'.format(bucket,prefix)
}
},
'TargetAttributeName': 'y'
}
]
output_data_config = {
'S3OutputPath': 's3://{}/{}/output'.format(bucket,prefix)
}That’s it! Of course, SageMaker Autopilot has a number of options that will come in handy as you learn more about your data and your models, e.g.:
- Set the type of problem you want to train on: linear regression, binary classification, or multi-class classification. If you’re not sure, SageMaker Autopilot will figure it out automatically by analyzing the values of the target attribute.
- Use a specific metric for model evaluation.
- Define completion criteria: maximum running time, etc.
One thing I don’t have to do is size the training cluster, as SageMaker Autopilot uses a heuristic based on data size and algorithm. Pretty cool!
With configuration out of the way, I can fire up the job with the CreateAutoMl API.
auto_ml_job_name = 'automl-dm-' + timestamp_suffix
print('AutoMLJobName: ' + auto_ml_job_name)
import boto3
sm = boto3.client('sagemaker')
sm.create_auto_ml_job(AutoMLJobName=auto_ml_job_name,
InputDataConfig=input_data_config,
OutputDataConfig=output_data_config,
RoleArn=role)
AutoMLJobName: automl-dm-28-10-17-49A job runs in four steps (you can use the DescribeAutoMlJob API to view them).
- Splitting the data set into train and validation sets,
- Analyzing data, in order to recommend pipelines that should be tried out on the data set,
- Feature engineering, where transformations are applied to the data set and to individual features,
- Pipeline selection and hyperparameter tuning, where the top performing pipeline is selected along with the optimal hyperparameters for the training algorithm.
Once the maximum number of candidates – or one of the stopping conditions – has been reached, the job is complete. I can get detailed information on all candidates using the ListCandidatesForAutoMlJob API , and also view them in the AWS console.
candidates = sm.list_candidates_for_auto_ml_job(AutoMLJobName=auto_ml_job_name, SortBy='FinalObjectiveMetricValue')['Candidates']
index = 1
for candidate in candidates:
print (str(index) + " " + candidate['CandidateName'] + " " + str(candidate['FinalAutoMLJobObjectiveMetric']['Value']))
index += 1
1 automl-dm-28-tuning-job-1-fabb8-001-f3b6dead 0.9186699986457825
2 automl-dm-28-tuning-job-1-fabb8-004-03a1ff8a 0.918304979801178
3 automl-dm-28-tuning-job-1-fabb8-003-c443509a 0.9181839823722839
4 automl-dm-28-tuning-job-1-ed07c-006-96f31fde 0.9158779978752136
5 automl-dm-28-tuning-job-1-ed07c-004-da2d99af 0.9130859971046448
6 automl-dm-28-tuning-job-1-ed07c-005-1e90fd67 0.9130859971046448
7 automl-dm-28-tuning-job-1-ed07c-008-4350b4fa 0.9119930267333984
8 automl-dm-28-tuning-job-1-ed07c-007-dae75982 0.9119930267333984
9 automl-dm-28-tuning-job-1-ed07c-009-c512379e 0.9119930267333984
10 automl-dm-28-tuning-job-1-ed07c-010-d905669f 0.8873512744903564
For now, I’m only interested in the best trial: 91.87% validation accuracy. Let’s deploy it to a SageMaker endpoint, just like we would deploy any model:
- Create a model,
- Create an endpoint configuration,
- Create the endpoint.
model_arn = sm.create_model(Containers=best_candidate['InferenceContainers'],
ModelName=model_name,
ExecutionRoleArn=role)
ep_config = sm.create_endpoint_config(EndpointConfigName = epc_name,
ProductionVariants=[{'InstanceType':'ml.m5.2xlarge',
'InitialInstanceCount':1,
'ModelName':model_name,
'VariantName':variant_name}])
create_endpoint_response = sm.create_endpoint(EndpointName=ep_name,
EndpointConfigName=epc_name)After a few minutes, the endpoint is live, and I can use it for prediction. SageMaker business as usual!
Now, I bet you’re curious about how the model was built, and what the other candidates are. Let me show you.
Full Visibility And Control with Amazon SageMaker Autopilot
SageMaker Autopilot stores training artifacts in S3, including two auto-generated notebooks!
job = sm.describe_auto_ml_job(AutoMLJobName=auto_ml_job_name)
job_data_notebook = job['AutoMLJobArtifacts']['DataExplorationNotebookLocation']
job_candidate_notebook = job['AutoMLJobArtifacts']['CandidateDefinitionNotebookLocation']
print(job_data_notebook)
print(job_candidate_notebook)
s3://<PREFIX_REMOVED>/notebooks/SageMakerAutopilotCandidateDefinitionNotebook.ipynb
s3://<PREFIX_REMOVED>/notebooks/SageMakerAutopilotDataExplorationNotebook.ipynb
AWS는 보다 간단하게 기계학습을 이용하고 싶은 유저용으로 자동화된 기계학습, Auto ML로 이야기를 이어갔다. 트레이닝을 위한 충분한 데이터는 있지만 기계학습에 임하는 노하우나 인원, 시간이 없는 기업도 많기에 그러한 기업에게 Auto ML은 유익한 솔루션이지만 거기에는 과제도 있다고 지적했다.
"자동화 된 구조로 모델을 빌드하면 구체적으로 어떻게 빌드되었는지 몰라 블랙박스화 되버린다. 그래서 모델을 더욱 진화시켜 예측 정도를 향상시킬 수 없다. 또 다른 과제도 있다. 기계학습 용도에 따라서는 고속으로 예측할 수 있는 모델이 필요한 경우가 있는데 그런 것에도 대응할 수 없었다"
Auto ML의 메리트를 누리면서 이러한 과제를 해소하는 것으로서 가시성이나 컨트롤을 잃지 않는 자동화된 트레이닝을 실현하는 툴로 Amazon SageMaker Autopilot이 발표됐다. 이것도 SageMaker Studio로 통합되어 있으며 이날부터 일반 제공을 개시했다. 사용자는 트레이닝 데이터가 되는 CSV 파일(테이블 데이터)를 준비할 뿐이며 다음 Autopilot이 데이터의 자동 변환, 최고의 알고리즘을 선택하고, 파라미터 및 알고리즘 등의 설정을 변화시키면서 최대 50 모델을 생성한다. SageMaker Studio 상에서는 이 다수의 모델을 정도순으로 리스트(랭킹)로 표시하고, 각 모델의 상세한 설정 등은 Notebook 형식으로 참조할 수 있다.
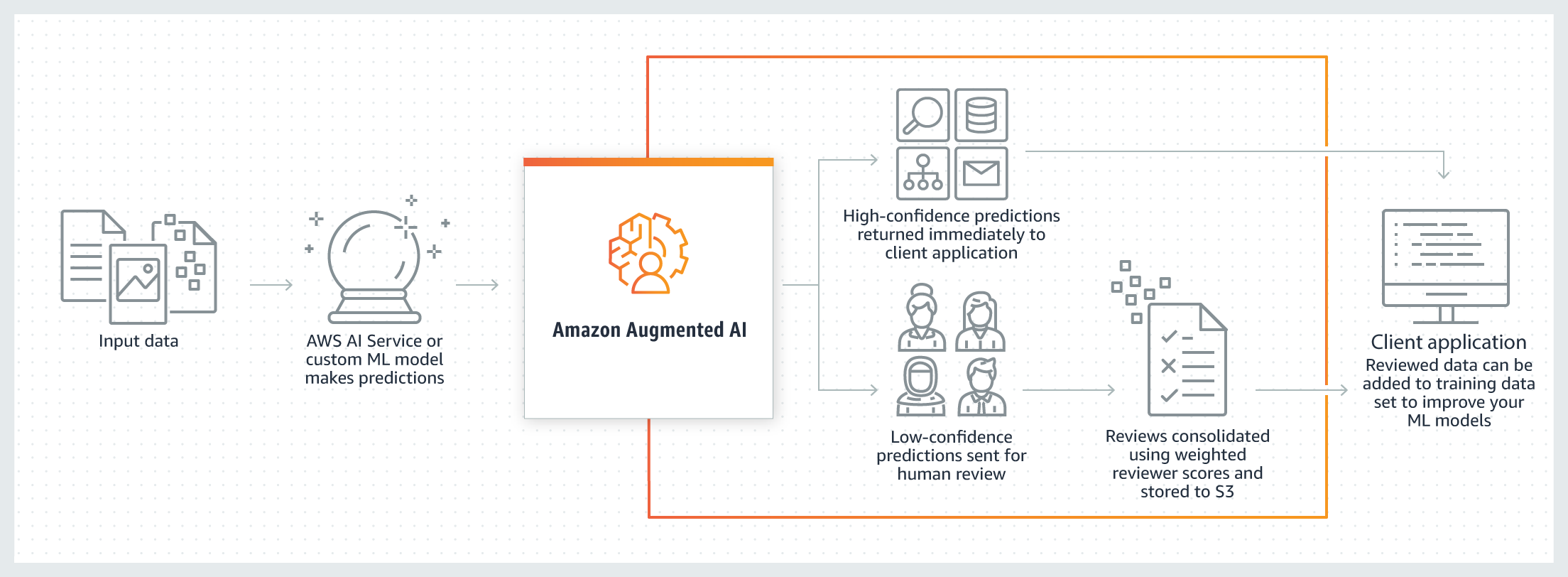
이것에 의해 어떠한 근거로 예측되고 있는지를 가시화하는 한편, 정밀도와 속도의 트레이드오프에도 유연하게 대응할 수 있다. 또 Autopilot에서 개발한 모델에 대해서도 전술한 SageMaker Studio나 Model Monitor 등의 기능군은 동일하게 이용할 수 있다. 기조 강연에서 언급하지 못했지만 기계학습 관련에서 또 하나 Amazon Augmented AI(Amazon A2I)이라는 새로운 서비스도 일반 제공이 개시됐다. 이것은 기계학습 어플리케이션에 의한 예측 신뢰성이 낮은 경우, 필요한 인간에 의한 리뷰의 워크플로우를 간단하게 구축할 수 있는 서비스다. 신뢰 스코어에 따라 자동으로 리뷰를 인간에게 할당 할 수 있고, 인간의 리뷰는 자사 종업원 뿐만 아니라 Amazon Mechanical Turk, AWS Marketplace의 서드파티 벤더에 대한 아웃소싱도 가능하다.
기계학습 모델을 스스로 개발하는 것이 아니라 보다 간편하게 기계학습의 능력을 활용하고 싶은 유저용으로 미리 학습이 끝난 모델이 내장된 ML 서비스군도 제공되고 있다. AWS는 이를 'AI(인공지능) 서비스' 라고 부른다. 그 동안 화상/영상해석(Rekognition)과 음성 텍스트화(Transcribe), 음성합성(Polly), 번역(Translate), 인사이트 추출(Comprehend), 채팅봇(Lex) 등을 전개해 왔으며 지난해 re: Invent에서도 퍼스널라이즈(Personalize)나 예측(Forecast), OCR(Textract)을 발표한 바 있다.
이러한 AI 서비스군은 거대한 스케일로 전개되고 있는 컨슈머 비즈니스(Amazon.com)에서의 교사 데이터 수집과 실천으로 단련되어 온 것으로, 이번에도 Amazon의 현장에서 태어났다고 말할 수 있는 복수의 서비스군이 추가되고 있다. 우선, 어플리케이션 개발에서 코드 리뷰나 퍼포먼스 개선을 지원하는 ML 서비스로 Amazon CodeGuru를 발표하고 있다.(프리뷰 릴리스) 기계학습 모델에 근거하여 어플리케이션 코드에 포함되는 문제점이나 취약성을 지적하는 CodeGuru Reviewer, 어플리케이션 퍼포먼스를 지속 감시/분석하는 CodeGuru Profiler로 구성된다.
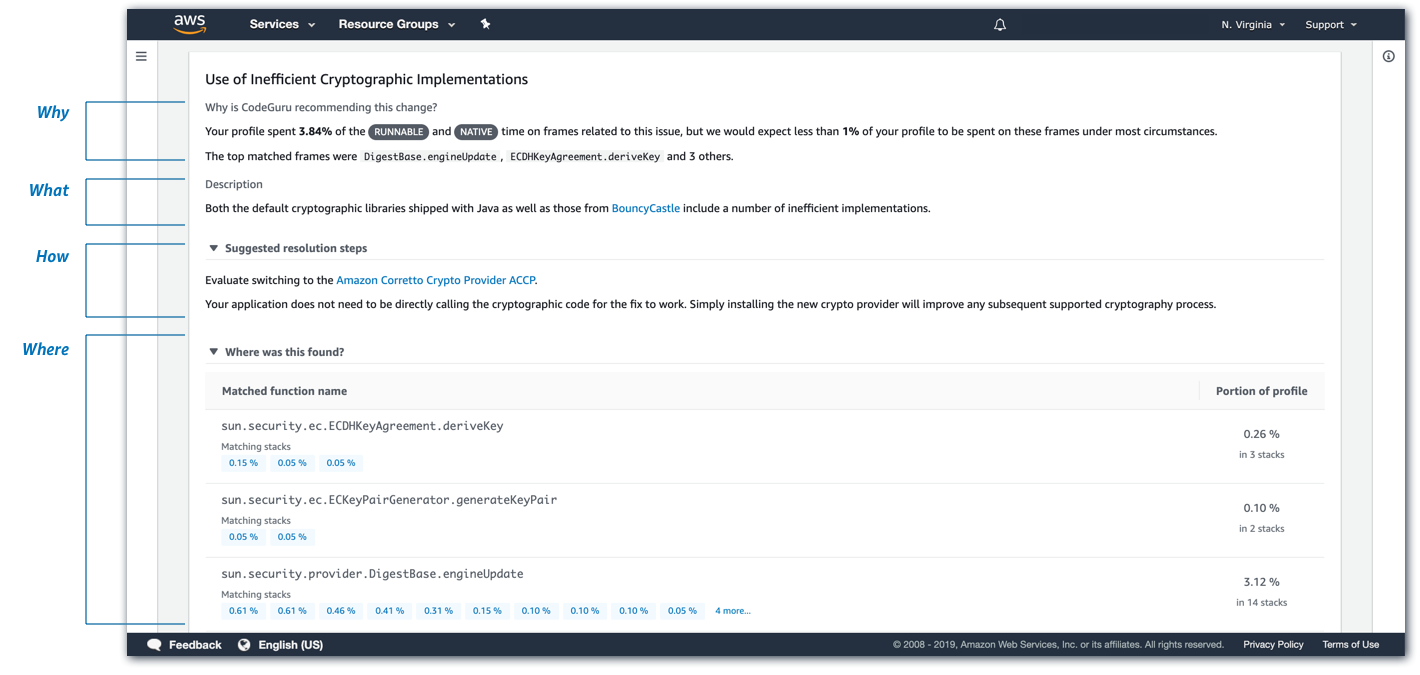
CodeGuru의 기계학습 모델은 Amazon 사내의 프로젝트 및 GitHub 상의 오픈소스 프로젝트로부터 얻은 대량의 코드 베이스로 트레이닝되고 있기 때문에 말하자면 "베스트 프랙티스"를 모델화한 것이다. AWS에 따르면 CodeGuru는 실제로 Amazon 사내에서 8만 5000개의 앱에 적용되고 있으며 Amazon 프라임 데이의 CPU 사용률을 325% 향상시키고 39%의 비용 절감에 연결한 실적도 있다고 밝혔다.
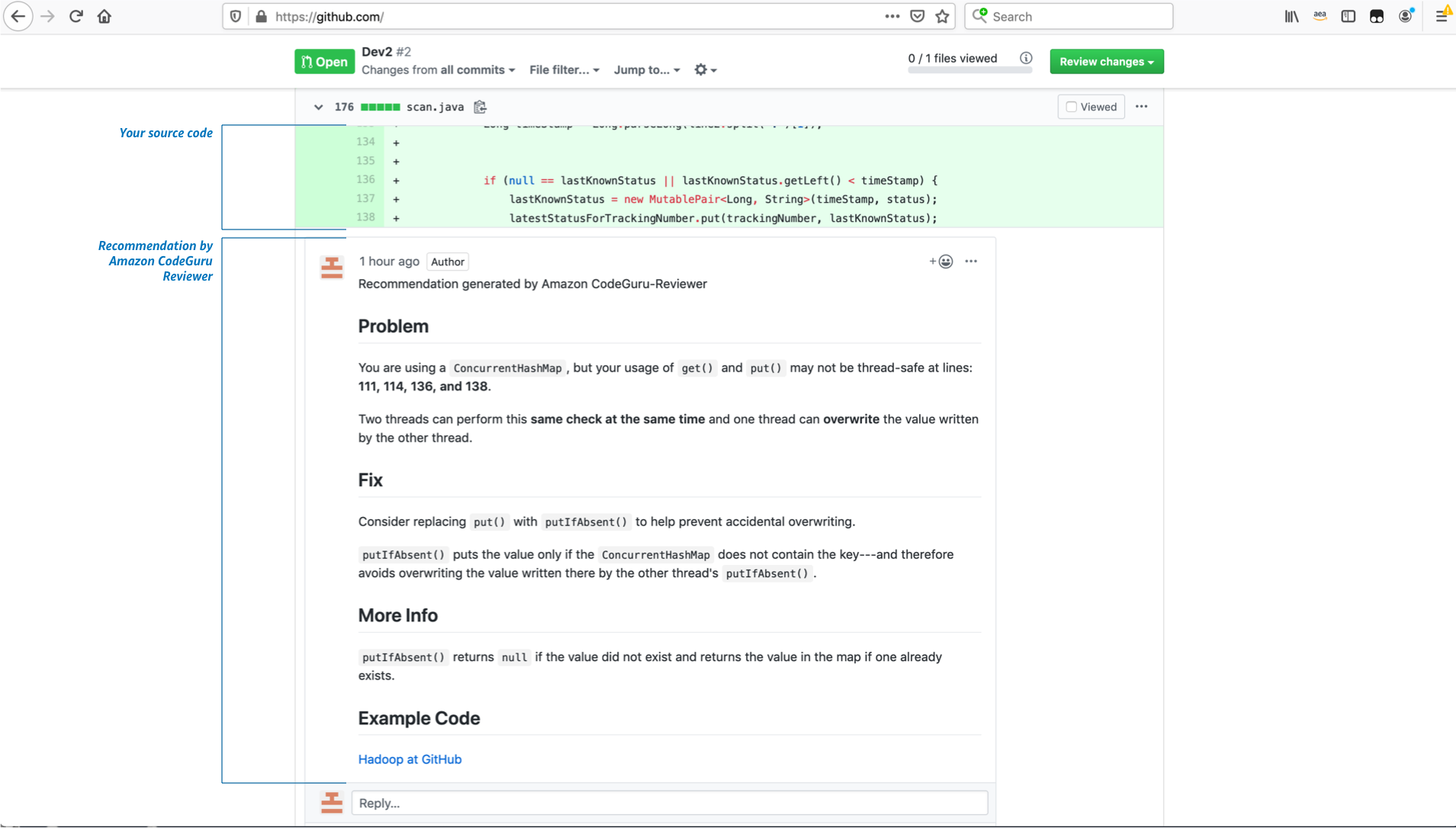
CodeGuru Reviewer는 개발자가 이용하는 코드 레파지토리 GitHub 및 AWS CodeCommit과 연계 동작하는 구조다. 개발자가 리퀘스트에 CodeGuru를 추가하면 CodeGuru는 자동으로 코드 리뷰를 실시하고 문제가 있는 곳에 권장사항을 코멘트한다. 또 CodeGuru Profiler는 에이전트를 통해 실전 환경의 애플리케이션 퍼포먼스를 지속적으로 감시하고, 감시 결과에 근거해 코드내의 처리에 가장 많은 자원을 필요로 하는 행의 특정이나 개선 방법의 권장 등을 실시한다.
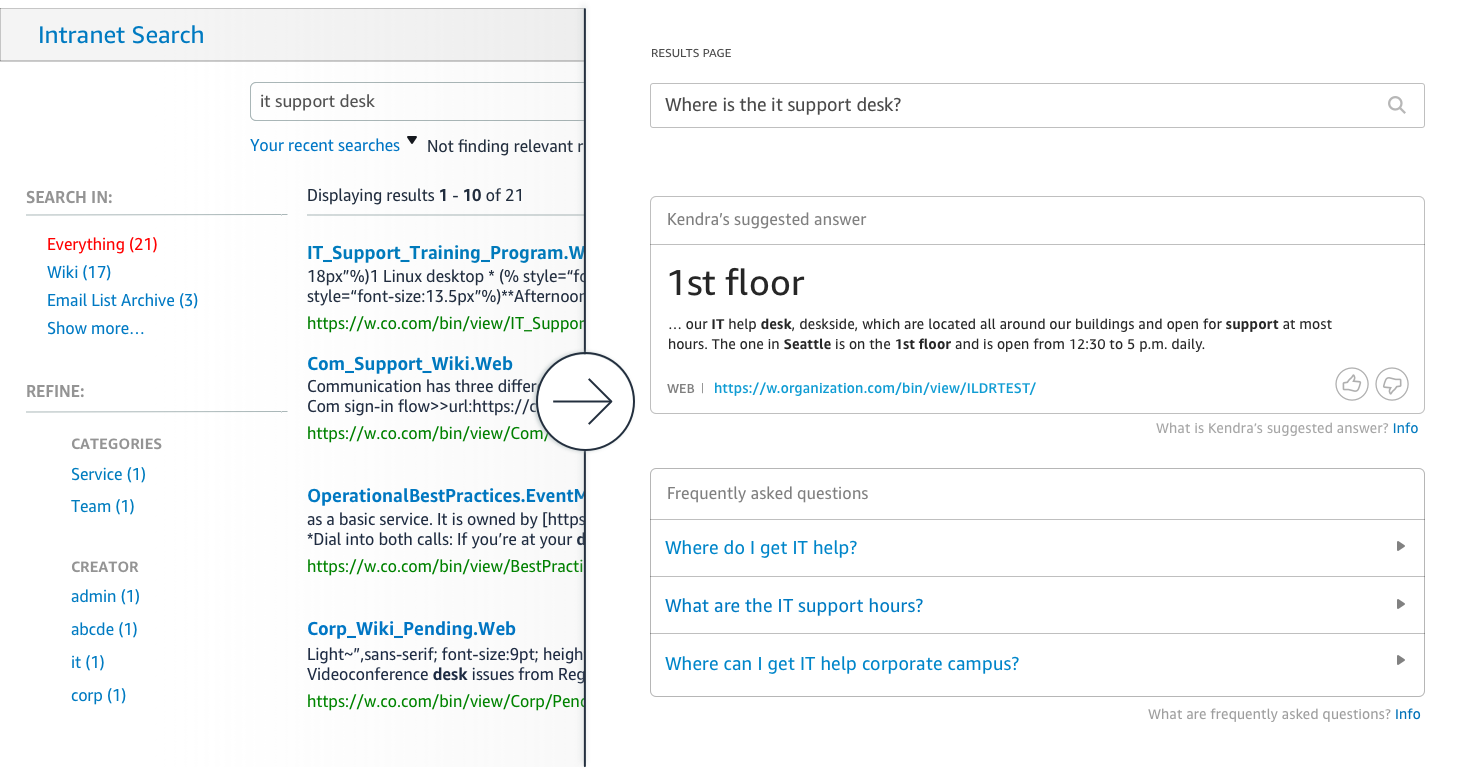
또, 기계학습 기술을 넣은 엔터프라이즈 검색 서비스 Amazon Kendra도 발표되고 있다.(프리뷰 릴리스) VPN에는 어떻게 접속해야 합니까? 라는 자연 언어 질문을 접수하고 데이터 소스 문서에서 정보를 추출하여 그 의도에 따른 답변을 실시한다. 기업 내에 있는 다양한 데이터 소스에 대응하고 있는 것도 특징으로, 제공되는 커넥터는 현 시점에서는 Web 사이트, Box, Dropbox, SharePoint, Salesforce, 릴레이셔널 데이터베이스, S3 파일 시스템 등에서 텍스트나 PDF, Word, PowerPoint 파일에서 정보를 추출할 수 있다. 또, 독자 커넥터를 개발하면 그 외의 데이터 소스로부터도 문서를 업로드 할 수 있다.
Kendra의 기계학습 모델은 검색을 실행한 유저의 피드백에 기초한 재트레이닝이나 튜닝도 행해진다. 검색 결과 순위는 질문에 대한 문서의 관련성 뿐만 아니라 작성일이나 유저의 액세스 수 등도 가미했는지 형태로 정해진다고 밝혔다.
소매업 등을 향한 새로운 서비스로는 어카운트의 부정 등록이나 상품의 부정 구입등의 온라인 사기를 판정하는 서비스로 Amazon Fraud Detector도 발표됐다.(프리뷰 릴리스) Fraud Detector는 "과거 20년간의 컨슈머 비즈니스(Amazon.com)의 데이터에서 확립한 알고리즘"에 근거하여 부정을 검지한다고 밝혔다.