



























’ 오픈")


![[All Around AI 1편] AI의 시작과 발전 과 by 인공지능](https://raptor-hw.net/xe/files/thumbnails/198/205/262x75.crop.jpg "[All Around AI 1편] AI의 시작과 발전 과")






케플러에서 전력 효율을 발전시킨 맥스웰
NVIDIA는 신세대 GPU 아키텍처 맥스웰을 투입했다. 요란하게 등장하지 않은 것은 저 성능의 메인 스트림 GPU 투입 때문이다. 예전과 같이 하이엔드 GPU와 퍼포먼스 GPU의 선 투입이 아니기 때문에 별로 눈에 띄지는 않고 있다. 그러나 아키텍쳐로서 맥스웰은 케플러에 이어 엔비디아 GPU 아키텍처의 새로운 단계로 NVIDIA에게 매우 중요하다.
맥스웰 아키텍처의 최초 GPU는 100달러 대의 지포스GTX 750 Ti/750. 퍼포먼스 GPU는 아니지만 맥스웰 아키텍처 자체는 지포스의 모든 범위 뿐 만 아니라 GPU 컴퓨팅을 위한 테슬라에서 모바일 SoC(System on a Chip)테그라의 GPU 코어까지 모두 커버하는 NVIDIA 제품 라인 전체의 공통 아키텍처가 될 전망이다. 또, 하이엔드 맥스웰은 Denver(덴버) CPU 코어를 내장한 APU형 구성으로도 보이고 있다.


맥스웰은 모바일 탑재를 개발 당초부터 고려해 설계된 최초의 GPU 아키텍처다. 케플러도 모바일 테그라에 탑재됐지만 케플러를 개발하기 시작한 시점에서는 테그라의 케플러 탑재는 생각하지 않았다고 한다. 테슬라에서 테그라까지 처음부터 고려해 개발된 것은 맥스웰이 처음이다.

맥스웰은 NVIDIA GPU 개발 노선의 변화를 상징한다. NVIDIA의 노선 변화 한마디로 퍼포먼스 포커스에서 퍼포먼스/와트(전력) 포커스로의 전환이다. NVIDIA는 페르미에서 케플러에서 극적으로 노선을 전환, 퍼포먼스/파워 옵티마이즈(전력 효율 최적화) 설계로 바꿨다. 파워 퍼포먼스, 에이리어(PPA)의 3가지 요소 중 최적화 포인트를 바꿨다.
우선 케플러에서는 GPU의 파이프 라인 단수를 페르미까지의 세대보다 절반으로 줄이고 동작 주파수를 억제하며 그 대신 코어(연산 유닛)수를 늘렸다. 또, 하드웨어 제어 워프/명령 스케줄링, 절반의 컴파일러로 변경했고 맥스웰은 이러한 케플러 사상을 더욱 밀어붙인 GPU 아키텍처다.


현재의 NVIDIA는 모바일에도 적용할 수 있는 전력 효율을 모든 플랫폼에 안겨야 한다. 그것은 무어의 법칙이 둔화된 시대에 따라 프로세스 기술의 발달에 의지하지 않는 아키텍처 적인 효율 향상이다.
인텔을 제외한 프로세서 메이커들은 현재 CMOS 스케일링 요소들의 스케일링 속도가 둔화된 상태에서 프로세서의 성능을 올리느라 고생하고 있다. 프로세스 기술의 진화에 의한 전력 감소 및 성능 향상이 어려워지고 있기 때문에 아키텍처로 전력당 성능을 높여 가야 한다. 맥스웰은 그 도전에 대한 NVIDIA의 해답이다.
무어의 법칙 둔화 때문에 28나노 공정으로 시작
맥스웰 아키텍처는 전 세대 케플러를 발전시킨 것이다. NVIDIA 아키텍처는 Fermi에서 Kepler로 크게 전환했고 GPU 형식 번호로 말하자면 GeForce GTX 500에서 GeForce GTX 600 세대의 아키텍처를 근본부터 수정했다. 그것에 비해 이번 맥스웰은 케플러 노선의 연장으로 이전과 같이 극적인 변화는 아니다. 그러나 맥스웰 아키텍처에는 매우 중요한 포인트가 몇 가지 보인다.
우선 맥스웰은 케플러와 같은 28나노 공정(또한 같은 프로세스 옵션)으로 제조하면서 전력 효율을 향상시키고 있다. 프로세스 기술 이외의 효율 향상을 실현하려는 맥스웰의 원래 계획은 20나노 였다고 볼 수 있는데 28나로로 출발하게 된 것으로 아키텍처 면에서 전력 감소가 더 강하게 요구되게 된다.

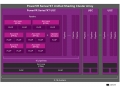
맥스웰의 기본 아키텍처는 케플러과 비슷하지만 NVIDIA GPU의 프로세서 코어 단위인 SM(Streaming Multiprocessor)의 구조를 크게 바꾸고 있다. 케플러의 SM은 SMX(Streaming Multiprocessor eXtreme)로 매우 큰 입도의 SM을 채용했지만 맥스웰의 SMM(Streaming Multiprocessor Maxwell)에서는 작은 블록을 4개로 집합시켜 1개의 SM으로 새로운 방식을 채용했다.
MaxwellaSM의 핵심은 (1) SM 내부의 실행 유닛 가동률을 높여 보다 적은 연산 유닛으로 고효율 성능을 얻을 수 있도록 한 것 (2) SM 자체의 구조를 계층화 및 심플화 함으로써 설계상의 효율성을 높인 것 (3)SM 자체를 컴팩트 하고 1개의 GPU에 더 많은 SM을 탑재할 수 있도록 한 것이다.

효율 향상의 열쇠는 명령 발행과 실행 유닛의 관계를 바꾼 점에 있다. 실행 유닛 수에 대한 명령 발행 수의 비율을 늘려 실행 유닛의 가동률을 높였다. 케플러의 피크 성능 위주에서 맥스웰은 실효 성능 중시로 돌아서 연산 유닛에 대한 명령 처리의 비율을 높였다. 즉, Kepler는 명령 발행을 최적화하여 높은 실행 유닛의 가동률을 발휘하지만 맥스웰은 최적화하지 않고도 웬만한 실행 유닛 가동률을 달성할 수 있다.
또 명령 유닛과 실행 유닛, 데이터 패스의 관계를 보다 간단하게 하고 SM 설계의 복잡성을 경감했다. 이 부분은 GPU 설계에서 중요한 포인트로 Kepler에서 지나치게 복잡하게 된 SM 설계는 다이당 효율성을 잃었다. 또, 맥스웰은 메모리 계층을 대폭 손질하며 보다 심플하고 효율이 높은 캐시나 데이터 패스로 구성되고 있다.


또 SM 구성을 블록 → SM 2계층으로 컴팩트한 SM 설계와 제어의 단순성, 대형 SM의 자원 유효 이용 및 다수의 스레드 간 데이터 공유의 이점을 양립시켰다.
DRAM의 제약 때문에 메모리와 연산 비율은 연산 편중으로 기울어
칩 전체로 보면 맥스웰은 연산 성능에 대한 메모리 대역 비율(Bytes/FLOPS)을 한층 더 연산 편중했다. 현재도 형편없는 Bytes/FLOPS 비율을 더 악화시키는 부정적인 요소이나 여기에는 DRAM의 전송 속도 둔화라는 외부적 요인(DRAM기술)이 있다. 메모리의 고 대역화가 둔화되고 있는 현 상황에서는 스택 DRAM이 등장하기까지 1세대는 연산 편중으로 갈 수밖에 없다.

맥스웰에서 이 문제를 커버하기 위해 캐시를 대폭 올려 어플리케이션에 따라서는 외부 메모리 액세스 빈도를 낮출 수 있도록 했다. 종래의 GPU는 그래픽 워크 로드에서 캐시의 히트율이 낮은 것을 전제로 하여 소량의 캐시밖에 탑재하지 않았다. 그러나 맥스웰 아키텍처에서는 CPU 수준의 MB 단위의 캐시를 탑재하게 되었다.
다만, 대용량 캐시는 메모리 바운드(메모리 대역이 제약 되는)의 변한 스트림 유형의 워크 로드에는 어려워 근본 해결이 아니다. 참고로 SRAM 면적을 키우는 것은 연산 코어가 늘어나는 고 클럭 액티브시의 전력 밀도를 낮추는 효과도 있다.
맥스웰 아키텍쳐는 연산/조직 비율도 연산에 편중됐다. 이것도 똑같은 이유로 메모리 대역에 제약이 있기 때문에 연산 코어와 같은 비율로 텍스처 유닛을 늘려도 의미가 없기 때문이다.

이렇게 맥스웰 아키텍처 전체를 보면 Kepler에 비해 심플화와 고 효율화를 실현해 무어의 법칙이 둔화된 상황에서의 퍼포먼스/전력 효율의 향상을 도모하는 한편, 아직 해결되지 않은 메모리 대역의 제약은 일단 캐시의 중량으로 대처했다고 볼 수 있다. 다만 메모리 대역 제약과 Bytes/FLOPS 비율의 악화는 맥스웰 다음의 Volta(볼타) 아키텍처 세대에서 스택 DRAM으로 경감할 수 있는 목표가 나타나 있다. 어디까지나 일시적인 제약이다.



계층 구조가 심플화 된 SM 아키텍처
케플러는 1개의 SM(Streaming Multiprocessor) 에 192개의 연산 유닛(CUDA)이 탑재되어 있었다. 이에 비해 맥스웰 아키텍처는 SM 내의 CUDA 핵심 수는 128 단위 또한 SM은 4개의 클러스터로 분할되어 각각 32유닛씩 CUDA코어를 탑재한다. 또한 각 클러스터에 1개의 명령 스케줄러와 2개의 명령 처리 유닛, 그리고 1개의 Special Function Unit(SFU), 1개의 로드/스토어 유닛, 64KB(32비트 레지스터×16,384)를 갖춘다.


맥스웰의 SM은 이 심플한 클러스터가 2개로 결합되어 조직 유닛과 텍스처&L1캐시를 공유한다. 그리고 SM 전체에서 64KB의 공유 메모리와 테셀레이션 등의 지오 메트리 파이프 라인을 공유한다. Kepler에서는 CUDA 연산 유닛은 실제로 16-way의 벡터유닛으로 모아져 있었다. 그것에 비해 맥스웰은 32-way 벡터유닛의 구성을 이룬다.
NVIDIA는 실행 유닛에 대한 명령 발행 비율을 바꾼 것으로써 실행 유닛의 가동률을 높였다고 설명한다. 그 결과 128개의 CUDA를 갖춘 맥스웰의 SM은 192개의 CUDA를 갖춘 Kepler의 SM에 가까운 성능을 발휘할 수 있다. 또 1개의 SM 다이 지역도 축소하여 NVIDIA는 메인 스트림 GPU에 탑재할 수 있는 CUDA 유닛 수를 늘릴 수 있었다.
칩 전체로 보면 현재의 메인 스트림판 맥스웰 GPU는 아래와 같이 되어 있다. 지포스GTX 750 Ti는 맥스웰의 SM을 5유닛으로 탑재하고 CUDA 유닛은 칩 전체에서 총 640개가 된다. 동작 클럭은 베이스가 1,020MHz, 부스터 1,085MHz. 연산 성능은 1.3TFLOPS에 이른다. 메모리는 GDDR5 5,400Mtps로 128-bit인터페이스, TDP는 60W.


다이 사이즈는 늘었지만 퍼포먼스/전력은 대폭 향상
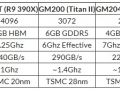
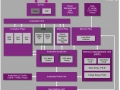
맥스웰 기반의 GM107의 다이 사이즈는 약 148kmm로, GM107의 다이 사이즈와 각 유닛 수가 기존 28nm Kepler나 AMD의 28nm GPU과 비교하면 아래 그림과 같이 된다. NVIDIA의 GM107의 구성은 AMD의 메인 스트림 GPU 구성과 일치한다.


Kepler세대의 메인 스트림 GPU GK107의 118kmm보다 많이 커졌지만 맥스웰 아키텍처의 GM107에는 2MB의 SRAM이 포함되어 있다. GK107과 비교시 CUDA 유닛수는 384에서 640으로 크게 늘었다. 피크시 연산 성능은 1.6배로 TDP(Thermal Design Power:열 설계 전력)는 7% 가량 낮아졌다. 전력에 대한 피크 성능은 1.7배로 증가하여 연산 유닛의 실제 가동률이 상승함으로써 실효 성능 효율이 2배로 올랐다.


한편, 피크 메모리 대역 증가는 8% 정도에 그친다. 이는 GDDR5 메인 스트림의 전송 속도가 올라가지 않기 때문이다. 그래서 NVIDIA는 텍스처 유닛 수를 GK107의 32유닛에서 GM107은 40유닛과 25%남짓박에 늘리지 않았다. 그 결과 SM 내에서의 연산 유닛에 대한 텍스처 유닛 비율은 저하되고 있다. SM 수는 GK107의 2유닛에서 GM107은 5유닛으로 2.5배로 늘었지만 SM 당의 텍스처 유닛 수는 2분의 1이 되고 칩 전체 조직 단위 수는 25%의 증가했다.
맥스웰 아키텍처를 더 자세히 보면, 이 아키텍처의 방향성이 더 명료하게 나타난다. 특히 실행 유닛에 대한 명령 발행은 맥스웰에서 크게 바뀌었다. 다음에는 맥스웰의 효율화 원천이 되고 있는 SM 아키텍처와 메모리 계층에 초점을 맞춰 보다 상세하게 다루고 싶다.
보도 - http://pc.watch.impress.co.jp/docs/column/kaigai/20140228_637462.html