























’ 오픈")






![[All Around AI 1편] AI의 시작과 발전 과 by 인공지능](https://raptor-hw.net/xe/files/thumbnails/198/205/262x75.crop.jpg "[All Around AI 1편] AI의 시작과 발전 과")






HBM DRAM이 마침내 양산 페이즈로 진입
차세대 고성능 DRAM "HBM DRAM"이 마침내 양산 초읽기에 들어갔다. 1TB/sec의 초 광대역 메모리를 목표로 한 적층 DRAM 규격 HBM(High Bandwidth Memory) DRAM으로 JEDEC(반도체 표준화 단체)에서 표준화 작업이 끝났고 현재는 SK hynix가 샘플을 출하하기 시작했다. 2014년 후반부터 양산이 시작되고, 2015년에는 최초의 탑재 제품이 등장할 것이라 밝혀졌다.

HBM은 실리콘 관통 전극(TSV:Through Silicon Via) 기술로 다이 스택킹(적층)형의 DRAM 기술이다. 인터페이스 폭은 1,024-bit(x1024), 메모리 대역은 첫세대에서 1스택 128GB/sec, 2세대 256GB/sec. 4개의 HBM 스택을 사용한 시스템이라면 512GB/sec ~ 1TB/sec의 메모리 대역을 실현한다.


DRAM 업계에서는 HBM DRAM을 광대역 GDDR5의 후속으로 하려 하고 있다. HBM DRAM은 그래픽 카드, HPC(High Performance Computing) 전용의 GPU와 스루풋 프로세서의 메모리, 서버 CPU 캐시, 네트워크 프로세서 전용 메모리 등의 용도가 상정되고 있다.

HBM은 GDDR5 보다 광대역 뿐만 아닌 저전력(약 3배의 퍼포먼스/전력)의 강점을 갖는다. PHY 전력 소비가 GDDR5에 비해 압도적으로 적어 4개의 스택 HBM DRAM을 1Gtps으로 추진해도 전력은 30W이하인 반면 GDDR5에서 이 대역을 실현하려면 전력은 80W 이상이 된다.

그러나 현재 발표된 HBM 탑재는 고 비용이라는 문제도 있다. DRAM을 TSV에서 스택할 뿐 만 아니라 버튼 로직 다이 사양으로 되어 있기 때문이다. 또 풀 대역을 얻기 위해서는 DRAM 칩을 4층으로 적층 해야 하며 메모리 정도가 크다.
그 때문에 현재의 GDDR5의 모든 포지션을 바꿀 수 있을지 의문이 있다. 그리고 GDDR5 계열 메모리 기술은 메모리 모듈에 대응한 신 규격 GDDR5M으로 파생되고 있어 전체적인 흐름은 메모리 기술이 다양화 시대로 향하고 있는 것처럼 보인다.

AMD와 NVIDIA 양쪽 모두 HBM으로
HBM은 현재 JEDEC으로부터 JESD235 규격이 발표되고 있으며 SK hynix가 2014년 2월 반도체 컨퍼런스 ISSCC(IEEE International Solid-State Circuits Conference)에서 실제 실리콘 성과를 발표하고 있다. SK hynix의 HBM은 JEDEC 규격에 준거한 것이지만 JEDEC의 규격 자체는 비교적 유연하게 수립되어 SK hynix가 발표한 사양 외의 탑재도 가능하다.

SK hynix는 4월 중국 선전에서 열린 인텔의 기술 컨퍼런스 Intel Developer Forum(IDF)shenzhen 2014 에서 HBM의 제품 계획을 발표했다. 현재의 예정으로는 2014년 중반까지 최초 2G-bit 첨단 제품 생산을 시작하고 2016년에는 더 용량이 증가된 고속의 2세대의 8G-bit 칩을 생산하는 계획이다. SK hynix는 3월 GPU Technology Conference(GTC)에서도 2G-bit HBM의 웨이퍼를 전시했다.



HBM장착 제품은 NVIDIA가 HBM을 장착할 것으로 보인다. 3D DRAM을 올린 차세대 GPU Pascal(파스칼)의 계획을 GTC에서 발표하고 있다. 또, AMD도 HBM의 GPU 탑재에 적극적으로 움직이고 있고 원래 HBM의 규격을 책정하고 있는 JEDEC의 DRAM 규격 책정 JC-42.3 Subcommittee의 의장은 AMD의 Joe Macri(Corporate VP&Product CTO of AMD Global Business Unit). 또, AMD는 2013년 12월 CPU 회의 Micro46(International Symposium on Microarchitecture 46)에서도 HBM을 포함한 다이 스택킹에 관한 키노트 스피치를 했다. 그리고 Micro46에서 키노트 스피치를 한 AMD의 Bryan Black(Senior AMD Fellow)은 원래 인텔에서 화제가 된 CPU를 분할하여 TSV를 접속하는 논문("Design and Fabrication of 3D Microprocessors"등)를 발표한 인물이다. TSV 기술 응용 중요 인물이 인텔에서 AMD로 이적하고 있다.


HBM의 개념이 된 TSV 기술
GPU나 GPU코어를 통합한 CPU/SoC(System on a Chip) 또는 네트워크 프로세서는 연산 성능을 프로세스 세대마다 배가시킨다. 그래서 현재 프로세서는 메모리 대역이 장벽이 되어 퍼포먼스를 발휘할 수 없는 상태에 빠져 있다. 이전의 솔루션은 메모리 인터페이스를 고전송, 인터페이스 폭을 확대하는 것으로써 메모리 대역을 올려 왔다. 그러나 소비 전력이 시스템 설계의 큰 문제가 되어 메모리와 메모리 인터페이스가 소비하는 전력을 늘리는 것이 어려워졌다.
그 때문에 지금은 "넓고 늦은" 메모리나 "좁고 빠른" 2가지 메모리 방향으로 진화 방향이 한정되고 있다. DRAM 업계는 현재 좁고 빠른 방향이 아닌 넓고 늦은 메모리가 이익이 있다고 보고 진화했으며 HBM은 그 대표격이다. HBM은 TSV 기술을 사용하여 현재의 DRAM이 안고 있는 제반 문제 해결을 노린다.



통상의 실리콘 칩은 다이의 한쪽 면에만 접속용 단자를 마련할 수 있다. 그래서 기존의 다이 스택킹에서는 겹친 다이의 단자 간을 가늘게 와이어로 연결한 와이어 본딩 배선이 사용되어 왔다. 이것에 비해 TSV는 다이의 실리콘 기판을 관통한 구멍으로 다이의 후면에도 단자를 배치한다. 그래서 TSV를 사용하면 다이들을 직접 접속할 수 있다.


기존 보드 상의 배선이나 와이어 본딩에 의한 배선은 칩 간 배선 수가 한정되어 있었다. 그러나 TSV는 적층한 다이 사이를 수천 단자로 접속 할 수 있다. 기존의 DRAM 칩의 몇 배에서 수십 배의 인터페이스를 실현할 수 있어 비교적 낮은 전송 속도에서도 초 광대역 메모리를 실현한다.
JEDEC에서는 TSV를 차세대 DRAM 기술의 핵심으로 규정하고, TSV를 전제로 한 DRAM 기술로서 모바일 Wide I/O, Wide I/O2와 하이 퍼포먼스를 위한 HBM 2가지 규격을 책정해 왔다. 또, DDR4도 모듈상에서는 TSV 적층을 하며 Micron Technology가 주도하는 TSV 기반의 스택 DRAM "Hybrid Memory Cube(HMC)"도 있다. DRAM은 TSV로 향해서 크게 움직이고 있다. TSV 자체는 DRAM 인터페이스만 아니라 다방면에 걸친 응용이 예상되지만 현재 양산 가능한 TSV로 적용하기 용이한 것은 I/O 분야로 CPU 내부 배선에 TSV를 사용하는 응용은 아직 거리가 있다.

1스택으로 128~256GB/sec의 메모리 대역
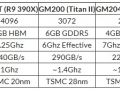
HBM DRAM에서 메모리 인터페이스는 1,024-bit(x1024) 이를 1~2Gtps의 전송 속도로 구동한다. 그래서 x1024에서 메모리 대역은 128GB/sec(1,024Gtps)~256GB/sec(2,048Gtps). 또 어떤 JEDEC 관계자는 HBM 세대에서 최대 3Gtps까지 달성할 것으로 예측했고, 그 경우 x1024에서 메모리 대역은 최대 384GB/sec(3,072Gtps).
HBM DRAM은 DRAM을 TSV에서 스택(적층)하지만 CPU나 GPU는 여러개의 HBM 스택을 배치할 수 있다. 예를 들면 4스택을 GPU/CPU에 접속하는 경우 GPU의 메모리 대역은 1Gtps 때 512GB/sec, 2Gtps시에 1TB/sec. 그 경우 GPU 전체 메모리 인터페이스의 데이터 버스 폭은 4,096-bit나 된다. 현재의 GDDR5 메모리 대역은 현실적인 차원에서 300GB/sec대이므로 4스택의 HBM DRAM은 계산적으로 2Gtps때 GDDR5의 3배 메모리 대역을 실현한다.


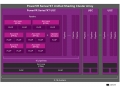
HBM DRAM은 1,024-bit의 DRAM 인터페이스를 8채널로 분할해 쓴다. 각 채널은 각각 128-bit(x128)의 인터페이스 폭으로 채널은 완전히 독립해 동작하고 채널별로 다른 DRAM 뱅크 그룹에 접근한다. DRAM 메모리 뱅크는 채널마다 완전히 분할되고, HBM DRAM의 DRAM 셀 선반입은 2 Prefetch(2비트씩 읽기)이므로, 128-bit 인터페이스에서 메모리 액세스 입도는 256-bit(32-byte)다.

현재의 SK hynix의 HBM DRAM의 경우 1024-bit의 DRAM 인터페이스는 아래와 같이 각 다이로 분할되고 있다. SK hynix는 2개의 채널이 1개의 다이에 접속한다. 각 2채널에서 4장의 다이를 적층 하는 것으로 8채널 풀 접근이 가능하게 된다. 즉, 1다이면 2채널에서 메모리 대역은 1Gtps시에 32GB/sec다. 다이를 적층 하면 할수록 메모리 대역이 올라 거꾸로 말하면 적층 하지 않으면 메모리 대역을 얻을 수 없다.

현재 예정된 HBM DRAM은 모두 SK hynix와 같은 2채널/다이 사양이다. 다만 JEDEC의 HBM DRAM 스펙에서 사실 다이당의 채널 수는 한정되지 않고 있다. DRAM 벤더의 선택 사항으로서 1개의 다이로 많은 채널을 할당하여 예를 들면 4채널 및 8채널 다이를 만들 수 있다. 혹은 그 반대로 1채널/다이, 1채널을 복수의 다이로 분산하는 것도 허용되고 있다. 탑재 상의 자유도가 높은 것이 HBM DRAM 규격의 특징으로 규격화는 독립 동작하는 채널 단위로 정해져 있다.
간단히 말하자면 HBM DRAM의 경우는 스택의 밖으로 동작 규격이 있는 한 스택 내부는 DRAM 벤더가 어느 정도 자유를 갖고 있다. SK hynix는 DRAM 스택 아래 기반 논리 다이를 두고 있지만 이것도 스펙상 옵션이며 논리 다이를 사용하지 않는 방법도 가능하다. HMC와 달리 DRAM이나 논리 다이 모두 외부 인터페이스는 동일하다.



단일 칩 메모리 대역에서 최고의 HBM DRAM
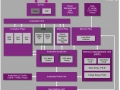
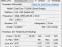
HBM DRAM의 인터페이스를 다른 JEDEC 계열 DRAM과 비교하면 그 특징이 더욱 명료하다. PC&서버의 메인 메모리용 DRAM의 인터페이스는 4/8/16-bit(x4/x8/x16)의 범위에서 GDDR5는 16또는 32-bit(동일 칩으로 전환 가능)이다. 모바일 스택 DRAM의 Wide I/O2가 되면 채널 구성은 HBM DRAM과 같은 최대 8채널(4채널의 사양도 있다)에서 각 채널이 64-bit(x64)로 합계 512-bit(x512)다. HBM DRAM의 인터페이스 폭은 가장 넓게 1,024-bit.


이들 JEDEC DRAM의 인터페이스 폭과 최대 전송 속도, 최대 메모리 대역 관계를 보면 아래 사진과 같이 된다. 이 사진을 보면 HBM DRAM의 스택당 대역이 뛰어나고 다이당 대역으로 봐도 HBM DRAM에 육박하는 것은 Wide I/O2 뿐이다.


보도 - http://pc.watch.impress.co.jp/docs/column/kaigai/20140428_646233.html