





















![[정종철] 뚜따에 진심인 형+과학자코스프레+현미경을구입했어
CPU 뚜따 교육자료ㅋㅋ](https://raptor-hw.net/xe/files/thumbnails/739/203/241x165.crop.jpg "뚜따에 진심인 형+과학자코스프레+현미경을구입했어")




’ 오픈")











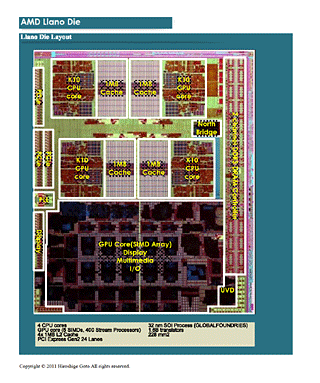
● 공개된 Llano(라노)의 내부 아키텍쳐
AMD는 소프트웨어 개발자를 위한 기술 컨퍼런스 「AMD Fusion Developer Summit(AFDS)」에서 새로운 APU(Accelerated Processing Unit) 「AMD A시리즈」(Llano)의 칩 아키텍쳐의 개요를 밝혔다. AFDS는 미국 워싱턴주 벨뷰에서 6월 13일~16일에 개최된 컨퍼런스로, Llano의 내부 버스 아키텍쳐와 CPU 코어 및 GPU 코어의 데이터 순환을 가능하게 하는 제로 카피의 개요등을 공개했다. Llano는 CPU 코어와 GPU 코어가 다이로 나눠져 있지 않고, 새로운 버스 아키텍쳐로 연결되고 있다.
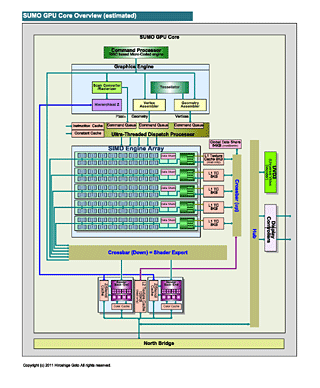
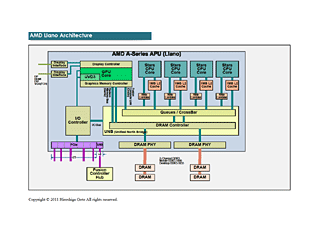
AFDS의 기술 세션과 AMD 관계자의 설명으로 나타난 Llano 전체의 모식도는 아래 사진과 같다. GPU 코어는 특수한 버스 아키텍쳐로 유니 파이드 노스브릿지(UNB)와 접속되고 있다.「Fusion Compute Link(Onion)」과「Radeon Memory Bus(Garlic)」의 2 계통 버스가 병렬로 연결되고, Garlic은 2개 분의 버스로 연결되어 있다.
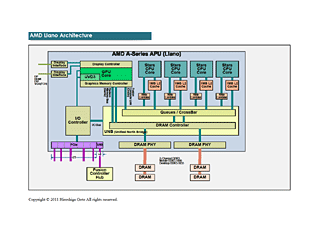
Llano는 GPU 코어가 CPU 코어와 하드웨어적으로는 동격 이상의 취급이 되고 있는 점을 확인할 수 있다. 기존의 SoC(System on a Chip)에서 CPU 코어 부분은 내부 CPU 버스에 접속되고 있지만, GPU 코어는 내부 I/O 버스에 연결되어 CPU 코어나 메모리 컨트롤러와는 거리가 있는 것이 일반적이였다.
그러나 AMD APU 아키텍쳐에서 GPU 코어는 I/O콘트롤러 버스 이외에, 메모리 컨트롤러에 직결되는 Radeon Memory Bus(Garlic) 버스를 갖추고 있다. 이 버스는 각각의 CPU 코어로부터 메모리 컨트롤러로의 링크보다 대역폭이 배가 되고 있다. 또 Llano는 CPU와의 coherency(일관성)을 갖는 Fusion Compute Link(Onion) 버스도 갖추고 있고, 메모리 엑세스 버스가 2 계통으로 되어 있다.
이 구조는 GPU 코어에 광대역의 메모리 엑세스를 유지하면서 CPU 코어와 GPU 코어 사이의 부분적인 데이터 교환을 가능하게 하기 위한 것이다. GPU 중심의 버스 구성이라고 말해도 괜찮을 정도의 고급스러움이다. 물론, 그 목적은 5 SIMD(400sp)의 연산 능력이 높은 GPU 코어 「Sumo」의 데이터를 피드백 하는 것에 있다.
또, 이 구조는 Llano 뿐만이 아니라 하위 APU 「AMD E시리즈 APU(Zacate/Ontario:자카테/온타리오)」에서도 공통되고 있는 것 같다. 프로그래밍의 일관성을 유지하기 위해서 같은 세대의 APU 간에 아키텍쳐를 통일하고 있다고 보여진다. 이 때문에 Llano의 내부 구성은 Zacate/Ontario의 내부 구성으로부터 추측하는 것이 가능하다. Zacate/Ontario의 내부 구성은 금년 2월의 ISSCC(IEEE International Solid-State Circuits Conference)와 4월에 일본에서 개최된 COOL Chips에서 밝혀졌었다. 아래가 COOL Chips에서 밝혀진 Zacate/Ontario 아키텍쳐의 모식도.
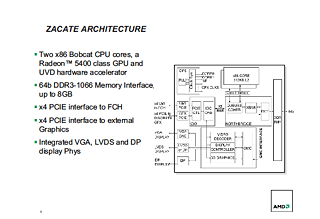
보다 자세하게 보면, GPU 코어와 UVD3 유닛 등 GPU에 부속되는 유닛은 그래픽 메모리 콘트롤러에 접속되고 있다. 여기서부터 버스가 연결되어 Radeon Memory Bus(Garlic)는 유니 파이드 노스브릿지 유닛안의 DRAM 콘트롤러와 직결하고 있다. 이 구조는 Zacate/Ontario와 같지만 Llano는 한가지 차이가 있다.
Llano의 Garlic 버스는 2중으로 되어 있어 각각 2 채널 DRAM의 다른 한쪽의 채널과 결합되고 있다. GPU 코어는 2 채널을 풀로 사용할 수 있기 때문에 Garlic 버스를 사용한 액세스는 광대역이다. 비디오 메모리 영역의 액세스 실효 대역은 최대 읽기 속도가 17GB/sec, 쓰기 속도가 12GB/sec가 된다.
Garlic 버스의 GPU 코어로부터의 최대 대역은 29.8GB/sec로 메모리 대역과 일치하고 있다. 그러나 통상적으로 실효 대역은 피크 대역의70% 이하로 떨어지는 것이 일반적이므로 Garlic의 대역은 피크대역에 가깝다. 덧붙여, Llano의 CPU 코어 단일 메모리 읽기&쓰기가 8GB/sec, 멀티 코어 액세스시에는 13GB/sec로, GPU 코어가 메모리 대역에서는 우세로 나타나고 있다.
Garlic 버스의 액세스는 CPU 캐쉬 snoop과 일치하지 않는다. 일관성을 취하는 CPU 버스와 접속하고 있지 않는 것은 이 때문이다. 액세스 하는 메모리 영역은 주로 공유 메모리내의 비디오메모리 영역이다. Garlic은 말하자면 별개적인 GPU 메모리 버스에 가까운 이미지의 버스 아키텍쳐다. Garlic 버스에 Radeon이라는 이름을 적용한 이유도 이와 같은 것이다.
한편 다른 한쪽의 Fusion Compute Link(Onion) 버스는 GPU 코어를 어느 정도 CPU 코어적으로 취급하기 위한 버스다. Onion을 경유한 메모리 엑세스는 GPU 코어가 지금까지 할 수 없었던 CPU 캐쉬의 Snoop이 가능하게 된다. 액세스 하는 메모리 영역은 공유 메모리내의 CPU측 시스템 메모리 영역이다. CPU와의 직결된 버스로, CPU와 GPU의 사이의 데이터 순환을 위해서 설치되었다.
Fusion Compute Link(Onion) 버스는 그 기능으로 볼때 CPU 버스에 접속되고 있다고 추측된다. AMD 멀티 코어 CPU의 내부 버스는 코어간의 시스템 리퀘스트를 조정하는 큐가 있어 이것이 외부 링크와의 크로스바 스위치와 접속하고 있다. Onion는 직접방식인지 어떤지는 불명하지만, 이 일관된 큐에 접속되고 있을 것이다.
Llano의 CPU 코어군은 기존과 같이 L2캐쉬를 경유한 캐쉬블 메모리 엑세스 외에, 라이트 콤바인(WC) 쓰기조합 버퍼 경유를 할 수 있다. WC 버퍼는 64byte로 각 코어에 갖춰져 있다. WC 버퍼 자체는 이전부터 AMD 코어가 갖추고 있던 기능이지만 APU에서 GPU 코어와의 데이터 순환에 밀접하게 결합되고 있기 때문에 추가하여 그렸다.
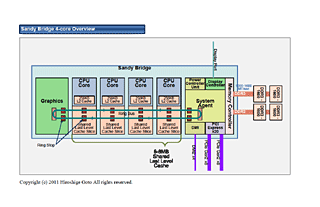
덧붙여, 라이벌인 Intel의 Sandy Bridge는 아래의 그림과 같이 단일 링버스에 CPU 코어와 캐쉬, 그리고 GPU 코어가 각각 동렬에 접속되는 구성으로 되어 있다.
그렇다면 이러한 GPU 버스와 CPU 버스를 사용한 메모리 엑세스는 어떻게 되는 것일까. 이것에 대해서는 AFDS에서 개요가 설명되었다.아래의 그림은 AFDS의 설명을 베이스로 작성한 Llano의 메모리 영역의 차트다.
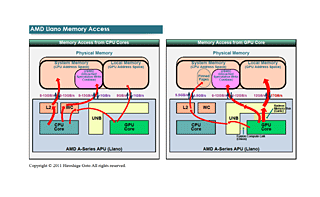
Llano는 CPU 코어와 GPU 코어가 같은 물리 메모리를 공유하고 있지만 여전히 CPU와 GPU의 메모리 어드레스 공간은 완전하게 나뉘고 있다. 양쪽 메모리 영역에 액세스 할 수 없지만, 한정된 형태로 프로그램상에서 명시하는 것으로 서로의 메모리 공간에 액세스 할 수 있다.
우선, CPU측의 시스템 메모리에는 GPU 코어측으로부터 액세스 할수 있는 「USWC(Uncached Speculative Write Combine)」영역을 설정할 수 있다. USWC는 CPU로 캐쉬되지 않는 메모리로 CPU 측으로부터도 통상적으로 액세스를 할 수 없지만 WC 버퍼를 경유한 액세스가 가능하다.
또, 캐쉬된 시스템메모리에는 GPU 코어측으로부터 Fusion Compute Link(Onion) 버스 경유로 액세스하기 위한 페이지를 설정할 수 있다.다만, GPU가 액세스 하는 페이지는 CPU의 통상적인 페이지 오퍼레이션이 행해지지 않게 고정할 필요가 있다. 또, GPU를 액세스 할 수 있기 위한 메모리 공간도 한정된다.
GPU 코어 측에는 GPU의 메모리 시스템으로 주소 되고 있는 로컬 비디오 메모리 영역이 있다. CPU측에서 WC를 경유하는 것으로, 이 GPU의 로컬 메모리에 액세스 할 수도 있다.
제약이 많기는 하지만 서로 액세스가 생기는 CPU 코어와 GPU 코어. 그러나, 같은 물리 메모리에 액세스 하는 것에도 불구하고, 그 메모리퍼포먼스는 메모리 영역에 의해서 큰 차이가 있다. 아래의 그림은 왼쪽이 CPU 코어로부터 메모리 영역 액세스의 3가지 경로와 대역을 나타낸 그림. 우측이 같은 그림의 GPU 부분이다. 표시된 퍼포먼스는 AMD의 발표 수치지만, 이것은 시스템이나 드라이버로 변화될 가능성이 있다. 그러나 큰 범위에서는 변하지 않을 것이다.
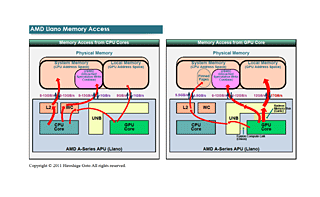
우선, CPU가 통상적으로 시스템 메모리에 액세스 하는 경우 캐쉬 계층을 경유한다. 싱글 CPU 코어의 액세스 대역은 읽기&쓰기 모두 8GB/sec로, 멀티 코어의 액세스는 13GB/sec. 최대 대역의 반 정도지만 그런데도 어느정도의 대역이 확보되고 있다.
USWC에 WC 버퍼 경유로 액세스 하는 경우 쓰기는 통상적인 캐쉬블 시스템 메모리에 대한 것과 같은 813GB/sec. 그러나 읽기는 떨어져 1GB/sec 이하가 되어 버린다. 같은 WC 버퍼 경유로 GPU측의 로컬 비디오 메모리 영역에 액세스 하는 경우는 쓰기가 8GB/sec으로 읽기가 1GB/sec 이하로 이것도 읽기가 매우 늦다.
GPU를 측면에서 보면 GPU가 자신의 비디오 메모리 영역에 액세스 하는 경우에는 이미 쓴 것처럼, 읽기가 17GB/sec, 쓰기가 12GB/sec이 최대 대역이 된다. 이것은 Radeon Memory Bus(Garlic) 버스를 사용한 액세스다.
같은 Radeon Memory Bus(Garlic) 버스 경유에서도 CPU측의 USWC(Uncached Speculative Write Combine)에 액세스 하는 경우는 읽기&쓰기도 6~12GB/sec로 약간 저속으로 된다. 그리고 Fusion Compute Link(Onion) 버스를 사용한 캐쉬블 메모리에 액세스 하는 경우는 읽기가 4.5GB/sec, 쓰기가 5.5GB/sec로 꾀 느려진다.
AMD는 향후의 헤테로지니어스 컴퓨팅을 위한 프로그래밍 체제인 「FSA(Fusion System Architecture)」를 AFDS에서 발표했다. FSA에서는 궁극적으로 CPU 코어와 GPU 코어가 같은 가상 메모리 공간을 일관하면서 공유하는 것으로, 양 코어간의 자유로운 데이터 교환을 실현한다.
그러나 이것을 실현하는 것은 AMD가 금년말에 릴리즈를 예정하고 있는 차세대 GPU 코어 「Graphics Core Next」가 APU에 통합되었을 때가 된다. 이 새로운 코어에는 기존의 AMD GPU와는 메모리 계층, 메모리 어드레싱도 일신 된다. GPU 내부의 캐쉬도 읽기&쓰기가 되어 CPU와 캐쉬 일관성이 유지되게 된다.
 |
| 次世代GPUコアのコヒーレンシ PDF版はこちら |
현재는 그 중반의 위치로 Llano 에서는 현재의 버스&메모리 컨트롤러의 아키텍쳐로 부분적인 공유를 실현하려고 한 것처럼 보인다. Llano로의 메모리 공유는 제약이 있어 프로그램으로 명시해야 하는 데다가 퍼포먼스의 큰 차이도 고려하지 않으면 안 된다. 사용하기 쉽다고는 말할 수 없는 것이 사실이다. Llano의 어프로치는 어디까지나 FSA로 가는 중간 역할에 지나지 않는 것 같다.
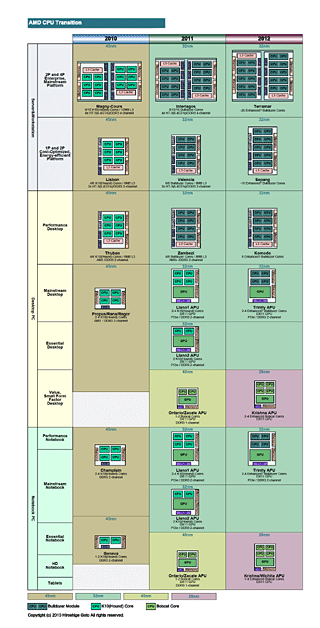 |
| AMD CPUアーキテクチャの移行 PDF版はこちら |
마지막으로 Llano의 코어는 단정밀도만으로 배정밀도를 지원하지 않는 것이 AFDS에서 밝혀졌다. 바탕이 되어 있는 Radeon HD 5870(Cypress) 계열은 이전의 Radeon HD 4800(RV770) 세대로부터 아키텍쳐 적으로는 배정밀도를 지원하고 있었다. 왜 Llano로 배정도를 지원하지 않았던 것인지 이유는 모르지만, 이것으로 HPC(High Performance Computing) 시장의 Llano의 길은 거의 닫혔다고 봐도 좋을 것 같다.
(2011年 6月 22日)