























’ 오픈")






![[All Around AI 1편] AI의 시작과 발전 과 by 인공지능](https://raptor-hw.net/xe/files/thumbnails/198/205/262x75.crop.jpg "[All Around AI 1편] AI의 시작과 발전 과")




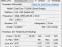


22nm 프로세스 세대에서 물리 코어수는 50% 증가
인텔은 14나노 프로세스 세대의 서버 CPU 패밀리 "Xeon Processor E5-2600 v4"를 발표했다. 코드 네임은 "Broadwell-EP"로 이중 소켓용 "Xeon E5-2계열이다. 인텔은 이 세대에 CPU 코어 수를 더욱 늘려 최대 구성은 22코어로, 메모리는 DDR4를 지원하고 메모리 전송 속도는 최대 2,400Mtps.

인텔은 65나노 Tulsa에 2코어, 45나노의 네할렘-EX에서 8코어, 32나노 웨스트미어-EX에 10코어, 22나노 하스웰-EX로 18코어로 프로세스 세대마다 다이상 CPU개수를 늘렸다. 코어 개수의 증가는 2→ 8→ 10→ 18로 변칙적이다. 이번에는 하스웰에서 브로드웰로 CPU 코어 아키텍처가 마이너 체인지되고 CPU 코어 개수는 18→ 24로 50% 증가했다. 다만 용장성 때문에 24코어 중 현재의 SKU에 사용된 것은 22코어로 되어 있다. 즉 최대 구성 제품에서도 22코어지만 물리적으로는 24코어가 다이를 구성하고 있다.
중복 코어가 설정된 것은 대형 다이가 되면 다이 위에 결함(defect)이 포함될 가능성이 높아지기 때문이다. 로직 회로는 defect에 약하기 때문에 부실을 통한 수율이 저하된다. 400mm2를 넘는 칩의 경우 결함이 있는 다이는 매우 많아진다. 결함이 포함된 다이를 모두 파기하게 되면 수율은 현저히 떨어진다.
그래서 GPU나 게임기용 APU 등에서는 결함으로 부실 코어의 발생을 예측하고, 논리 부분에 용장성을 갖게 하는 것이 일반적이다. 현재의 브로드웰-EP 구성에서는 24코어 중 2코어가 불량이어도 출하할 수 있다. SRAM 부분도 대체 셀에서 용장성을 가지고 있어 수율은 일정하게 끌어올릴 수 있다. 브로드웰-EP의 24코어는 그런 목적으로 보인다.
다이 사이즈를 작게 억제한 Broadwell-E 계열
이번에 인텔은 프로세스를 미세화했음에도 불구하고, 코어 수는 50% 증가했다. CPU 코어 자체의 인핸스는 작기 때문에 코어 면적은 축소해 다이 사이즈는 전 세대보다 작아지고 있다. 브로드웰-EP의 다이 크기는 최대 24코어의 크기로 웨이퍼에서 역산할 수 있다. 300mm 웨이퍼상에서 브로드웰-EP의 다이 면적은 450mm2 초과가 된다.

과거의 최대 구성 인텔 서버 CPU의 다이를 보면 22나노 공정의 하스웰-E 계열이 18코어에 662mm2, 아이비 타운이 15코어에 541mm2 로 서버 CPU로는 브로드웰-EP의 다이 사이즈는 Tulsa의 435mm2 이후 소형 다이다. 하스웰-EP/EX와 비교하면 68%의 다이 면적이다. 인텔의 14나노 공정의 트랜지스터 밀도는 높기 때문에 좀 더 다이가 축소되도 좋은 것 같지만 I/O 주변 때문에 그렇게 되지는 안된다. 현재의 프로세스 기술에서 I/O 부분은 축소 비율이 낮기 때문에 코어 부분의 사이즈가 축소되도 I/O는 그만큼 축소되지 않는다.

인텔은 이번 세대에서 서버 CPU의 다이 크기를 기존 대비 70% 안팎으로 축소했다. 그 배경에는 다이를 줄일 수밖에 없는 경제적 사정이 있다고 생각된다. 현재는 프로세스 세대마다 프로세스 후 웨이퍼의 비용이 상승하고 있다. 또 비용 상승률이 오르고 다이 면적당 비용은 세대마다 점점 오르고 있다. 이는 프로세스의 복잡성이 커지고 웨이퍼의 산출량이 떨어지고 있기 때문이다. 급격히 증가하는 프로세스 개발 비용도 비용 증가를 뒷받침한다. 프로세스를 미세화하면 이 정도의 다이 면적 칩 비용은 상승한다.
인텔은 트랜지스터와 배선 밀도를 올리는 것으로 이 문제를 해결하려 하고 있다. 즉, 보다 조밀한 칩으로 다이를 축소하고 다이 면적당 비용 상승을 상쇄하려고 한다. 그래서 인텔은 프로세스의 미세화를 추진하면서 비용을 일정하게 유지하게 위해서는 개별 제품의 다이를 축소해야 한다. 이것이 브로드웰-EP에 발생되는 것이라고 추측된다.

모듈러 설계의 Broadwell-EP
24코어(SKU는 22코어)의 브로드웰-EP의 구성은 아래와 같다. 기본은 하스웰-EP와 마찬가지로 2겹의 링 버스가 2계통 있다. 각 링마다 CPU 코어와 LL 캐시 슬라이스가 링 스톱에 연결되어 있다. 2개의 링간에는 버퍼 스위치에 의해 상호 연결되어 있다. 버퍼 스위치는 상하 2곳에 설치됐고 외부 I/O와 메모리 인터페이스도 링 스톱에 연결되어 있다.

이 구조는 하스웰-EP/EX와 기본적으로는 동일하다. 아래는 하스웰-EX의 구성도다. CPU 코어 수는 다르지만 2겹의 링에 코어와 I/O가 배치된 점은 공통되고 있다. 구조에서 QPI 인터페이스가 3계통 있는 것은 EX 계통이기 때문이다. 실제로는 Broadwell-EP도 다이상에는 3번째 QPI 링크가 있고 EP 계열 제품으로는 무효화되고 있다고 추측된다.

인텔은 CPU 설계에서 물리 설계를 유용하게 할 수 있는 모듈러 설계를 채용하고 있다. 논리적인 베이스의 설계 방법과 달리 각 모듈의 물리 설계를 조합함으로써 복수의 CPU 제품 설계를 가능하게 한다. 브로드웰-EP/EX 계열에서도 이 설계 기법이 활용된다. 최대 규모의 구성에서 모듈을 무효화하여 소규모 구성의 칩 설계가 가능하다. 아래는 하스웰 세대에서 파생된 다이다.

이 구조로 브로드웰-EP도 기본 설계의 다른 3종류의 다이를 파생시킬 수 있다. 최대 HCC(High Count Cores) 24코어의 다이는 각 링 페어에 6코어 ×2로 12코어가 접속되고 있다. 12코어의 2링크에서 합계 24코어다. MCC(Medium Core Count) 15코어의 다이는 각 링 페어의 코어 수가 5코어 ×2로 10코어로 감소되고 있다. LCC(Low Core Count)의 10코어 다이는 1링 페어에 5코어 ×2의 10코어의 구성을 이룬다.

좀 재미있는 점은 브로드웰-EP도 하스웰-EP도 2개의 링 페어의 코어 배치가 대칭되어 있지 않은 점이다. 왼쪽의 링 페어는 CPU 코어가 외향에서 LL 캐시가 오른쪽. 오른쪽 링 페어는 CPU 코어가 오른쪽에 배치되고 있다. 또 브로드웰-EP의 구성은 근원 배치만 보면 아이비타운과 같지만 링 버스에 다른 링이 심플화되고 있다.

CPU 아키텍처에서 이번 LL 캐시 제어가 확장되어 가상 머신에 따른 제어가 가능한 "Intel Resource Director Technology"에서 캐시의 할당이 있다. 이는 캐시 QoS 모니터링과 캐시 태그에서 우선 순위 비트를 확장하고, Hypervisor가 우선 순위 제어를 행할 수 있도록 했다.


또 전력 제어에서 브로드웰-EP는 CPU 코어 단위 전압 제어를 하고 있다. 부하에 맞추어 CPU코어마다 전압과 주파수를 최적으로 설정할 수 있다.
바뀐 데이터 센터의 프로세싱 자원
대형 서버 CPU는 인텔이 지배적이고, 특히 x86/x64에서는 압도적인 상황이다. 그러나 인텔 서버 CPU가 싸우는 상대는 타사의 서버 CPU가 아니다. 현재 데이터 센터는 구조적인 변혁기를 맞이하고 있으며 서버 CPU의 역할 변화가 일어나고 있다. 데이터 센터에서 처리하는 데이터가 바뀌고 있기 때문이다.
서버 CPU에 크고 성능이 높은 CPU 코어가 요구되고 있던 것은 서버 워크로드가 스레드 부하의 무거운 것을 처리했기 때문이다. 그런데 빅데이터나 딥 러닝으로 시대가 변화하면서 서버의 처리는 쓰레드당 부하는 가볍지만 데이터 양이 엄청난 것으로 바뀌기 시작했다. 특히 대량 데이터 처리의 전력당 효율을 생각하면 대형 CPU 코어는 분명히 나빠진다.
기존 서버 CPU는 성능은 높지만 성능당 전력 소비가 크기 때문에 메모리 및 I/O가 병목이 되는 워크로드의 경우에는 전력 효율이 낮다. 반면 작은 처리 코어를 병렬화하면 각각의 CPU코어가 메모리나 I/O 액세스를 기다리는 동안에 다른 CPU 코어가 처리할 수 있어 메모리 대역을 효율적으로 사용할 수 있다.
이러한 흐름으로부터 스몰 CPU 코어 서버 CPU가 효율성의 주목을 받았다. 또 GPU 같은 효율이 높은 SIMT(Single Instruction, Multiple Thread) 타입의 병렬 프로세서는 특히 딥 러닝으로 달아올랐다. 또 고정 회로를 실현할 수 있는 FPGA(Field-Programmable Gate Array)도 Microsoft의 데이터 센터 채용 이후 초점이 되고 있다.

이런 상황에서 데이터 센터에는 서서히 GPU와 FPGA가 끼어들기 시작하고 있다. 서버용 대형 CPU로 규정했던 기존과 뚜렷하게 흐름이 다르다.
인텔은 이러한 상황에도 대응하여 GPU에는 제온파이 계열(나이츠 패밀리) 본명의 "Knights Landing"이 대기하고 있다. FPGA의 흐름에는 인텔이 인수한 알테라의 FPGA 제품군이 있다. 인텔은 제온과 FPGA을 Multi-Chip Package(MCP)에 탑재한 제품을 계획하고 있어 장래의 데이터 센터에는 FPGA가 유용하다고 밝히고 있다.
즉, 인텔 자신의 데이터 센터 전용 프로세서 제품들이 확대되고 있다. 그 중에서 서버 CPU는 데이터 센터의 주역 요소 중 하나의 위치가 바뀌고 있다. 지금까지와는 다른 경쟁 상대로 다른 제품 카테고리에서 경쟁이 요구되고 있다.
물론 스레드 성능이 높은 대형 CPU 코어와 코히렌시의 트래픽을 경감하는 대량 캐시의 서버 CPU는 앞으로도 중요한 위치를 차지한다. 그러나 데이터 센터는 다양화 시대를 맞았고, 서버 CPU로 억제하면 된다는 상황이 아니다. 인텔의 강점은 이러한 변화에 맞춘 대응을 모두 하고 있는 점이며 인텔의 약점은 그것 때문에 인텔의 전략적 초점이 어디인지 보기 어렵다는 점이다.
출처 - http://pc.watch.impress.co.jp/docs/column/kaigai/20160401_751273.html