






















’ 오픈")


![[정종철] 뚜따에 진심인 형+과학자코스프레+현미경을구입했어
CPU 뚜따 교육자료ㅋㅋ](https://raptor-hw.net/xe/files/thumbnails/739/203/241x165.crop.jpg "뚜따에 진심인 형+과학자코스프레+현미경을구입했어")












미국 아마존의 연례 행사 AWS re:Invent 2016이 미국 라스베이거스에서 진행됐다. 아마존은 글로벌 클라우드 시장을 선도하고 있는 업계 리더로서 보고서의 주요 내용을 정리하여 소개한다.

AWS re:Invent 2016 기조 강연에 AWS CTO(Chief Technology Officer) 워너 보겔스가 등단하여 "Transformations"라는 테마에 대해 발표했다. 최근 IT 업계의 발표에서는 디지털 트랜스포메이션이라는 테마가 자주 언급되고 있는데 워너 보겔스는 이에 대해 개발 - 데이터 - 컴퓨트라는 3가지 영역이 핵심이라 설명한다.
사물인터넷(IoT)이나 인공지능(AI) 등 최신 트렌드는 모두 데이터 분석과 연결되고 있다. 디지털 트랜스포메이션을 위해서는 수집한 데이터를 어떠한 방법으로 새로운 가치로 전환할 것인가, 또 이것을 어떻게 비즈니스로 확대하여 오퍼레이션의 효율화를 시행하고 비용 절감으로 연결할 것인가를 고려해야 한다.
이에 대해 보겔스가 제안한 것이 "모던 데이터 아키텍처(The Modern Data Architecture)"라는 개념이다. 데이터 수집, 축적, 보존, 분석까지 일관된 사이클로 실현하는 이 아키텍처를 실현하기 위해 AWS가 어떻게 서비스를 제공하고 있는지, 어떻게 제공할 것인지에 대한 설명을 진행했다.
우선 데이터의 수집 부분이다. AWS에는 Amazon S3라는 데이터의 큰 양동이가 있기 때문에 모은 데이터를 일단 거기에 둔다. 실시간 스트리밍 데이터를 취급하는 서비스로는 Kinesis와 DynamoDB Streams 등이 있고 기존 데이터베이스의 이행을 실현하기 위해 Database Migration Service도 준비되어 있다. 대용량 데이터를 물리적인 어플라이언스, 컨테이너에서 이식하는 Snowball도 하나의 데이터 수집 도구라고 할 수 있다.
온라인 스토리지 웹 서비스인 Amazon S3는 지금도 꾸준히 진화하고 있다. S3 행사를 계기로 Lambda를 호출하거나 CDN인 CloudFront를 이용하여 업로드의 산출량을 향상시키는 기능(Transfer Accerelation)등은 최근 몇 년간 추가된 것이다. 최근에는 객체의 태그 추가, 로그 관리 CloudTrail에서 이벤트 관리, CloudWatch에 대한 매트릭스의 지출 등도 관리 기능으로 강화되고 있다.
또 수집한 데이터를 안전하게 보존하고자 AWS는 S3 외 블록 스토리지 EBS, 파일 서비스 EFS, NoSQL DB의 DynamoDB, 콜드 스토리지 Glacier 등 용도에 따른 데이터 서비스를 준비하고 있다. RDS 시리즈는 RDB를 서비스로 제공하며 Oracle과 SQL Server 같은 상용 제품, PostgreSQL과 MySQL, MariaDB 등의 OSS, 그리고 Aurora 같은 자사 서비스 등을 폭넓게 갖추고 있다.
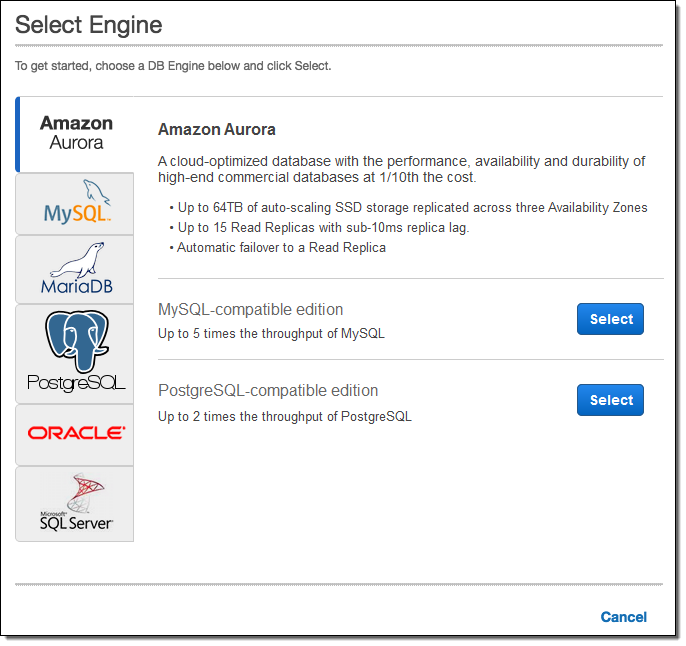
이 중 높은 성능과 가용성을 자랑하는 MySQL 호환 Amazon Aurora는 성장율도 높고 많은 엔터프라이즈에서 도입되고 있다. 또한 스키마의 변환과 제로 다운 타임으로 리플리케이션을 실현하는 Database Migration Service도 착실하게 실적을 쌓아 이미 1만 4000 데이터베이스를 마이그레이션하고 있다. 그리고 이번에 PostgreSQL For Aurora가 발표되면서 MySQL과 PostgreSQL 같은 OSS DB에서 Auraora로의 이행이 점차 촉진될 것으로 예상되고 있다.
한편, AWS는 빅 데이터와 데이터 분석 서비스도 충실한 라인업을 자랑한다. Hadoop 환경을 제공하는 Amazon EMR(Elastic MapReduce) 외 검색 서비스인 Amazon Elasticsearch, 스트리밍 분석을 가능하게 하는 Amazon Kinesis, DWH 서비스 Amazon Redshift 등이 빅 데이터 기반을 지지한다. 또 지난해 4월에는 머신러닝을 제공하는 Amazon Machine Learning, 10월 re:Invent 에서는 BI 서비스인 Amazon QuickSight가 발표되고 있으며 데이터의 가시화까지 커버하고 있다. 이번에는 모바일 앱에 푸시 통지를 보내는 Amazon Pinpoint도 발표됐다.
다만 이들 빅 데이터 서비스는 대용량 데이터를 고속으로 분석하는데는 제격이지만 심플한 분석을 빨리 마무리하는 것은 적합하지 않다. 아마존에 의하면 S3에 있는 Web 로그, 이벤트 데이터 등을 직접 분석하고 싶다는 사용자 피드백이 있기 때문에 이것에 맞추어 Redshift와 EMR을 보완하는 서비스로서 태어난 것이 새롭게 발표된 Amazon Atehna라고 밝혔다.
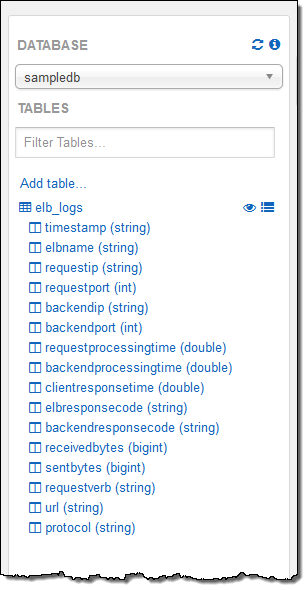
OSS의 Presto를 채용하는 Amazon Athena는 Amazon S3에 저장된 CSV, JSON, ORC, Parquet등의 데이터에 대해 표준 SQL로 쿼리를 걸 수 있다. 또 QuickSight가 모두 통합되고 있기에 분석 결과를 그래프화할 수 있다. 이것은 데이터를 이동하거나 로드하지 않아도 S3에서 쿼리 할 수 있기 때문에 인프라를 별도로 준비하지 않아도 되고 응답시간도 매우 짧다고 어필했지만 Amazon Athena가 Redshift나 EMR를 대체하는 존재는 아니라는 것을 강조했다.
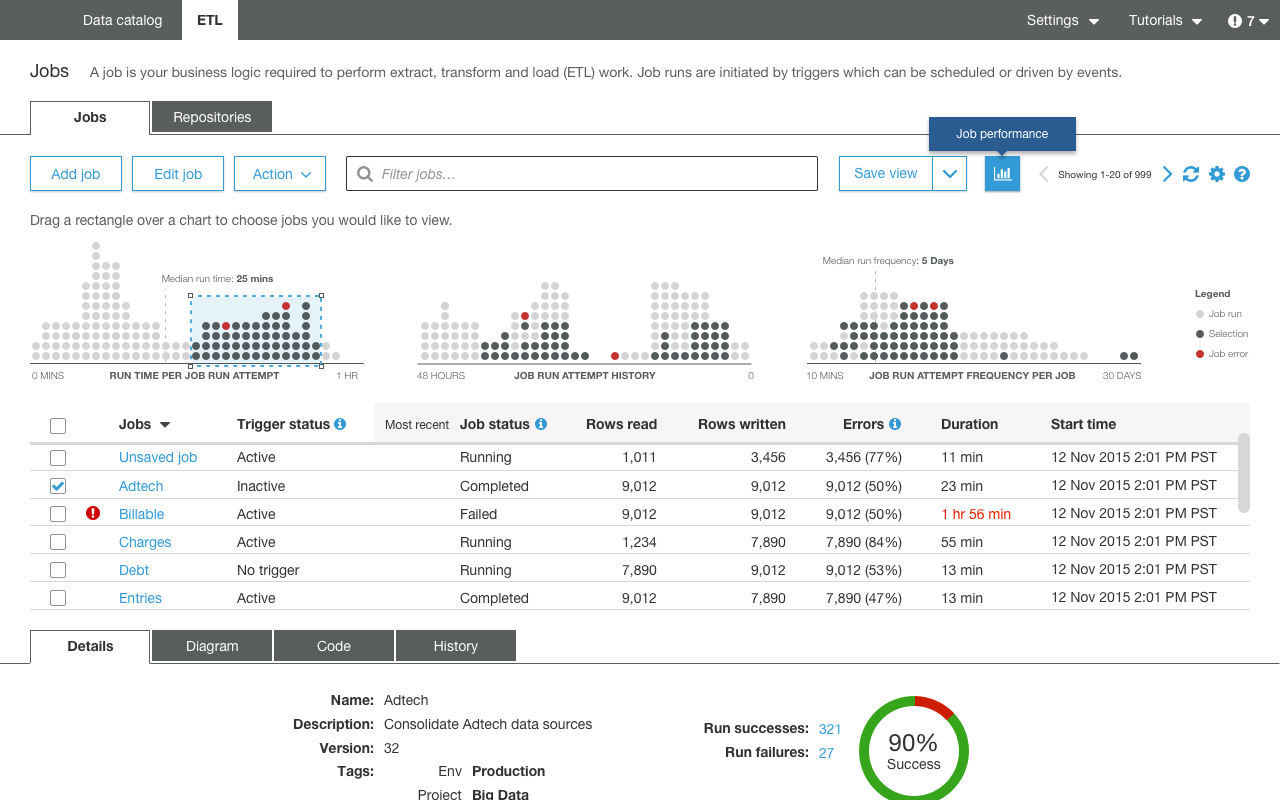
보겔스는 이와 같이 풍부한 서비스를 갖추고 있다고 밝히면서 앞서 말한 The Modern Data Architecture라는 관점에서는 아직 부족한 피스가 있다고 밝혔다. 그리고 그것을 위한 AWS Glue를 소개했다. AWS Glue는 데이터 카탈로그와 ETL을 제공하는 서비스로 S3와 RDS, Redshift, JDBC 대응 DB 등 다양한 소스에서 데이터를 추출하여 데이터 목록을 작성하고 사용자에 대한 데이터에 접속을 관리할 수 있다. 그리고 ETL(Extract, Transform, Load) 기능에 의해 분석하기 쉬운 포맷으로 데이터를 변환한다. 당연히 소스 데이터의 갱신에 대해 일련의 처리를 스케줄링하는 것도 가능하다. 보겔스는 AWS Glue 투입에 의해 모든 것이 커버되고 포괄적인 데이터 아키텍처를 AWS 상에서 실현할 수 있다고 어필한다.
그리고 데이터 처리에 대해 마지막으로 밝힌 것이 멀티 스케일에서 일괄 관리를 시행할 수 있는 AWS Batch. 이는 HPC와 거래 분석, 부정 감시, DNA 시퀀스·미디어 렌더링 등 Large Scale Processing 이라 불리는 영역에서 사용되는 패치 처리를 대상으로 한 것으로 멀티 스케일이 큰 장점이다.
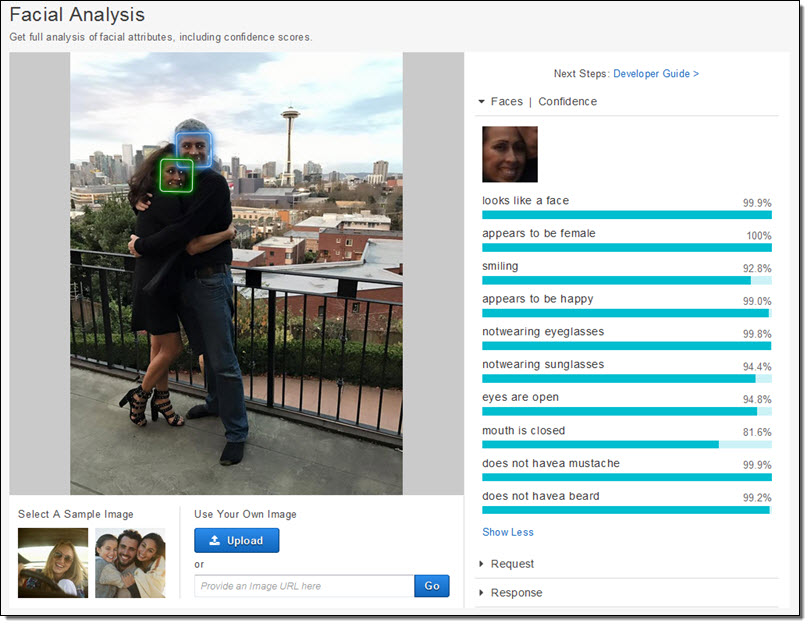
또한 이러한 데이터 분석의 연장선으로 있는 것이 이른바 인공지능(AI) 분야다. 빅 데이터를 분석하고 데이터를 가치로 바꾸기 위해서는 AI의 존재가 필수로서 이에 대해 AWS는 GPGPU를 이용할 수 있는 P2 인스턴스나 딥 러닝용 AMI(Amazon Machine Image), Amazon Machine Learning을 제공함과 동시에 머신 러닝용 프레임워크를 제공하는 MXNet에 대한 투자를 집행하고 있다.
이러한 AWS의 머신 러닝 이용 실적은 다양한 업계에 스며들어 이미지 검색, 부정 이용 방지, 자동 운전, 스포츠 사전 예측 등의 용도로 실적을 올리고 있으며 Amazon 자체도 상품 검색, 출하와 물류 효율화, 기존 제품의 머신 러닝 기능 추가 등을 추진하면서 동시에 Alexa의 음성 인식 기술을 기반으로 한 Amazon Echo 같은 제품을 다루고 있다.
하지만 클라우드에서 AI의 서비스화는 경쟁중인 Google과 Microsoft Azure, IBM이 앞서고 있는 분야이기도 하다. 이에 대해 이번에 "Amazon AI"로 불리는 머신 러닝 서비스의 제품 군을 발표하면서 단번에 반전을 도모하겠다고 밝혔다.
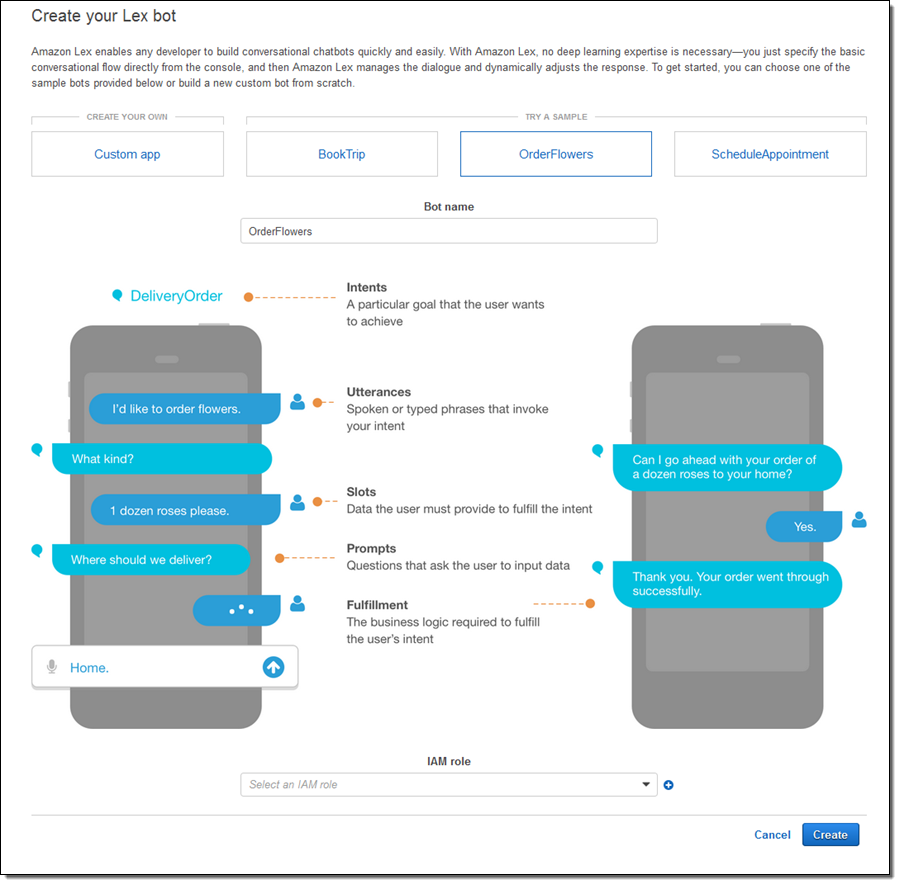
이번에 발표된 Amazon AI는 Amazon Rekognition - Amazon Polly - Amazon LEX 3가지가 준비된다. 이 중 Amazon LEX는 Amazon Echo에 탑재되고 있는 Alexa 기술을 이용한 것으로 인간의 대화에서 자동적으로 의도를 간파하고 적절한 응답을 돌려주며 Lambda를 서비스로 구동할 수 있기 때문에 각종 엔터프라이즈 서비스와 연계할 수 있다.