



























![[정종철] 뚜따에 진심인 형+과학자코스프레+현미경을구입했어
CPU 뚜따 교육자료ㅋㅋ](https://raptor-hw.net/xe/files/thumbnails/739/203/241x165.crop.jpg "뚜따에 진심인 형+과학자코스프레+현미경을구입했어")
’ 오픈")










불도저 아키텍처 발표 이후 6년이 지난 2017년 3월, AMD는 마침내 새로운 시대의 서막을 알리는 「 젠 마이크로 아키텍처(Zen Microarchitecture) 」 를 발표했다. 이는 6년간 프로세서 시장을 사실상 독점한 인텔과 다시 한번 경쟁할 수 있는 기반이 마련된 것으로써 AMD의 강력한 "Sweet Spot"이 될 가능성이 있는 젠 아키텍처를 세부적으로 살펴보도록 한다.
※ 선행 구독
인텔 네할렘 아키텍처 분석
http://raptor-hw.net/xe/index.php?mid=rapter_analysis&page=2&document_srl=108899
인텔 샌디브릿지 아키텍처 분석
http://raptor-hw.net/xe/index.php?mid=rapter_analysis&page=2&document_srl=109029
AMD 불도저 아키텍처 분석
http://raptor-hw.net/xe/index.php?mid=rapter_analysis&page=2&document_srl=109017
GPU 시장 분석) GPGPU 페르미 아키텍처 분석
http://raptor-hw.net/xe/index.php?mid=rapter_analysis&page=2&document_srl=109109
반도체 아키텍처 분석) x86, HSA, HBM, TSV, 3D V-NAND
http://raptor-hw.net/xe/rapter_analysis/109695
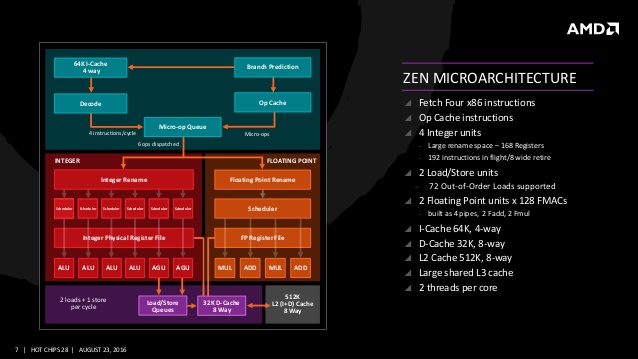
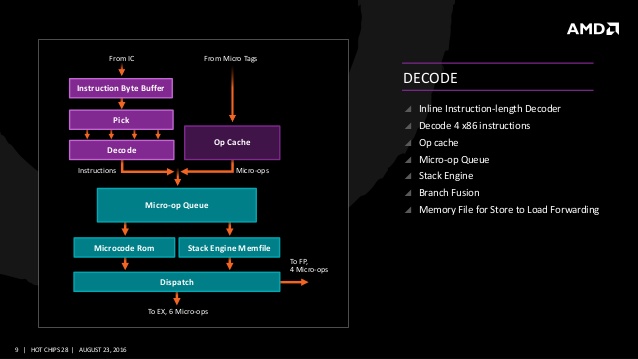
먼저 젠 아키텍처의 프론트 엔드 스테이지 전반은 많은 변화가 진행되고 있다. 눈에 띄는 점은 완전히 재설계 된 SIMD 파이프 라인과 부동 소수점 유닛 부문이다. SIMD(Single Instruction, Multiple Data) 유닛과 부동 소수점 유닛은 128bit SIMD의 MUL/FMAD와 128bit SIMD의 ADD 유닛이 2세트로 총 4유닛이다. 128bit MUL/ADD가 2유닛, FMAD 2유닛으로 사이클당 최대 4명령 발행이 가능하며 디스패치는 최대 4마이크로 오퍼레이션이다. 명령 디코더는 사이클당 4명령을 내부 마이크로 오퍼레이션/OP 캐시에 디코드하며 스케줄러에서 정수와 부동 소수점 연산계로 나누어 연산한다. 캐시는 64KB의 L1 명령 캐시와 32KB L1 데이터 캐시, 512KB L2 캐시와 코어간 공유하는 8MB L3 캐시, 명령 디코더의 하단에 새롭게 추가된 OP 캐시를 갖춘다. 캐시 대역은 L1 명령 캐시가 32byte(256bit)/사이클, L1 데이터 캐시에서 2개의 16byte(128bit) 로드와 하나의 16byte(128bit) 스토어를 병렬로 실행할 수 있으며 L2 대역은 L1 명령 캐시/L1 데이터 캐시가 각각 32byte(256bit)/사이클이며 L3 - L2 구간도 32byte(256bit)/사이클.
마이크로 오퍼레이션(OP) : 명령 포맷이 복잡하고 가변 길이 형태인 x86 명령과 달리 명령 포맷이 단순한 고정 길이/고정 포맷형태로써 RISC와 같이 비교적 간단하게 실행
4개의 정수 연산 유닛은 일반적으로는 같은 기능을 갖지만 Multiply, Divide, CRC32 3가지 기능은 1유닛씩 각각 다른 정수 파이프에 할당되어 있다. 이것은 하나의 ALU만이 Multiply가 가능하고, 다른 하나의 ALU가 Divide, 또 다른 하나의 ALU가 CRC32를 처리할 수 있는 것이며 그 외의 일반적인 연산은 4개 ALU가 모두 동일하다. 또한 물리 레지스터 파일은 통합된 하나의 168엔트리 구조로 변경되고 있다. 불도저가 스레드당 96엔트리, 2개의 유닛이 총 192엔트리로 많아 보이지만 불도저는 정수 유닛이 물리적으로 분리되어 있기 때문에 차별성이 있다. 정수 스케줄러는 6개의 명령 포트로 각각 14단 큐에서 합계 84엔트리, 불도저는 각 스레드마다 40엔트리로 2개의 정수 코어, 합계 80엔트리로 젠 아키텍처의 스케줄링은 불도저보다 깊다.
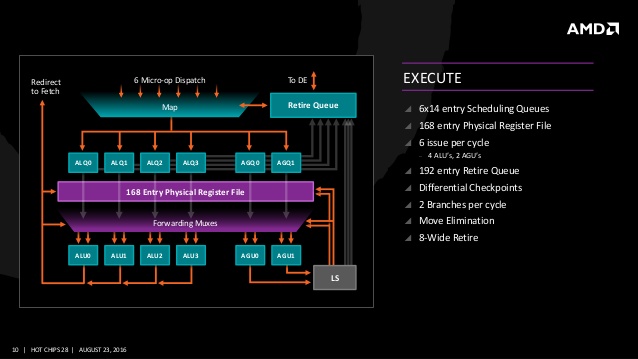
정수 파이프는 2개의 ALU 파이프가 각각 개별적인 브랜치 유닛과 접속하고 있다. 2개 분기는 같은 스레드에 속하는 분기 명령이나 다른 스레드에 속하는 분기 명령이라도 모두 실행이 가능한 2분기/사이클이다. 2병렬 브랜치 유닛은 2스레드일 경우 각각의 브랜치 명령을 동시에 실행할 수 있고, 1스레드 중 복수의 브랜치 명령도 1주기로 실행하여 더 많은 브랜치를 1사이클에 처리할 수 있기 때문에 연속 코드의 실행 효율이 향상되고 있다.
젠 아키텍처도 브랜치 퓨전(Branch Fusion)을 도입하고 있다. 이것은 비교형 명령과 점프 명령을 융합시키는 것으로써 2개의 명령은 디스패치 단계에서 하나의 마이크로 오퍼레이션으로 융합되고 융합된 브랜치 퓨전 마이크로 오퍼레이션은 하나의 마이크로 오퍼레이션으로 리타이어(Retire)까지 다룬다. 실행시에도 2개의 마이크로 오퍼레이션으로 분리되지 않는다.
디스패치 유닛은 최대 6마이크로 오퍼레이션을 1사이클에 발행한다. 이것은 In-Order 에서 Out-of-Order 로 사이클당 최대 6마이크로 오퍼레이션으로 보내는 것이며 제어 할 수 있는 총 마이크로 오퍼레이션의 수는 192개다.(불도저 128개) Out-of-Order 가 발행한 6마이크로 오퍼레이션을 8마이크로 오퍼레이션을 수용하는 리타이어 큐가 최대한 빠르게 리타이어 시키는 구조.
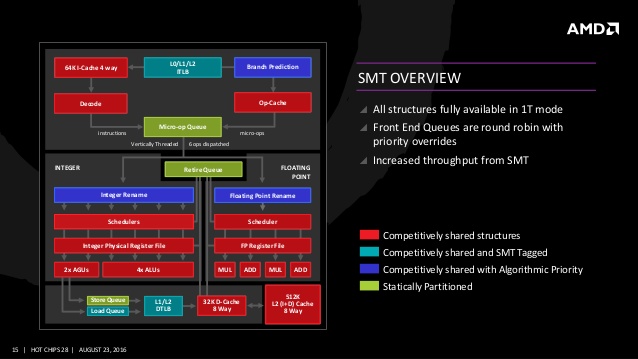
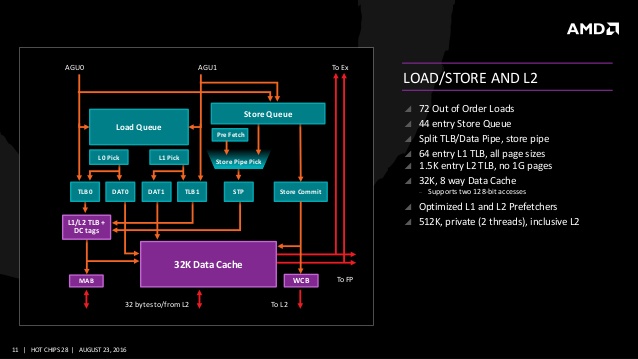
기존 불도저 아키텍처는 모듈 내에 정수 코어가 물리적으로 2개로 분리되어 병렬 스레드로 처리했다. 이 설계의 이점은 각 모듈(코어)가 정수 유닛 자원을 경쟁없이 원할하게 2개의 병렬로 실행하여 멀티스레드 성능 향상을 도모할 수 있으나 반대로 물리적인 강제 분리에 따라 싱글 스레드 성능이 낮아지기 때문에 불도저의 싱글 스레드 성능은 경쟁사 대비 처참했다. 그에 따라 AMD는 젠 아키텍처에 보다 전통적인 SMT(Simultaneous Multithreading) 기술을 도입하여 대부분의 자원을 스레드에서 공유하는 다중 스레드 설계로 전환했다. 젠 아키텍처의 정수 연산은 4파이프, 로드/스토어 주소 생성이 2파이프로써 불도저 대비 2배 상승한 스레드당 정수 연산 병렬성을 나타내고 있다.
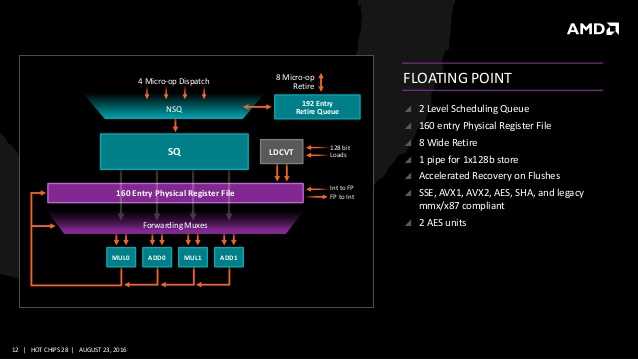
부동 소수점 연산 파이프는 MUL/ADD가 각각 2개지만 실제로는 MUL 파이프에 ADD 유닛이 포함되어 있고, FMAD 유닛으로 실행된다. 이론적으로는 FMAD에서 MUL/ADD 파이프를 동시에 움직일 수 있지만 실제로는 레지스터 파일의 리드 포트 제약 때문에 MUL/ADD는 동시에 진행할 수 없다. 4개의 SIMD 파이프 라인과 부동 소수점 유닛은 각각 2개의 레지스터 리드 포트를 갖추며 1사이클에 각 유닛에서 2개 소스의 오퍼랜드(Operand) 리드가 가능하다. MUL/FMAD는 3개의 소스 오퍼랜드가 필요하다. 레지스터 파일에서 읽을 경우 리드 포트가 부족하기 때문에 약간의 트릭을 사용하고 있다. MUL/FMAD는 ADD 파이프에서 레지스터 파일의 리드 포트를 하나 차용하고 있다. MUL/FMAD는 ADD 유닛은 사용하지 않기 때문에 ADD 유닛 자체가 비어 ADD는 스케줄러가 차단한다. 이것은 MUL/FMAD 유닛과 ADD 유닛 자체는 분리되어 있지만 레지스터 리드 포트 수가 한정되어 있기 때문에 두 가지를 동시에 실행 수 없는 것이며 FP 레지스터 파일 전체는 128bit 리드 포트가 각 유닛에 2개씩 총 8포트로 구성되고 있다.
부동 소수점 유닛의 마이크로 오퍼레이션 큐 사인은 NSQ(Non-Scheduling Queue)와 스케줄 큐(Scheduler Queue) 2단계로 진행된다. 스케줄러 큐는 각 실행 유닛에 대한 마이크로 오퍼레이션을 발행할 때까지 대기시킨 스케줄링한 큐를 말하며 Out-of-Order 의 일반적인 스케줄이다. 반면 전단부에 추가된 NSQ는 단순한 마이크로 오퍼레이션의 버퍼로 볼 수 있지만 NSQ에 FP 마이크로 오퍼레이션이 대기하고 있는 동안 정수 유닛 쪽에 발행된 다른 마이크로 오퍼레이션이 실행된다. 상대적으로 레이턴시가 긴 마이크로 오퍼레이션이 실행 되는 사이 FP 마이크로 오퍼레이션은 NSQ에서 스케줄 큐로 옮겨지며 이후 FP 마이크로 오퍼레이션이 연산 파이프에서 처리되는 시점에는 오퍼랜드의 데이터가 레지스터에 로딩되어 있다.
이러한 2단계 큐로 구성함으로써 스케줄링의 자원을 절약하고 있다. 큐잉의 전반은 자원 체크 등의 스케줄링을 하지 않아 로드 레이턴시를 은폐하기 때문에 마이크로 오퍼레이션을 완충할 수 있다. 이것에 의해 스케줄링의 자원을 억제하며 큐잉을 효율적으로 진행할 수 있기 때문에 정수/부동 소수점 연산 큐잉의 균형을 잡을 수 있다.
또한 젠 아키텍처는 AVX2의 256bit SIMD 명령을 지원한다. 256bit 명령은 2개의 피스로 분리하여 각각 독립적으로 실행한다. 128bit의 연산 유닛을 2개 결합시켜 실행하는 형태가 아니며 2개의 128bit 운영은 완전히 독립된 마이크로 오퍼레이션으로써 2개의 마이크로 오퍼레이션을 Out-of-Order 에서 실행할 수도 있다. 즉 256bit AVX 명령은 디스패치 스테이지에서 세분화 된 마이크로 오퍼레이션으로 분리되고 개별적인 128bit 마이크로 오퍼레이션으로 진행되며 레지스터도 각각 128bit 레지스터를 사용하는 것.
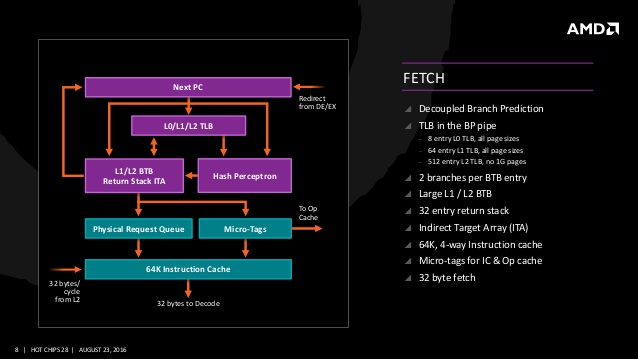
프론트 엔드 스테이지에는 최대 특징 중 하나로 디코딩한 내부 명령인 Micro-OP(마이크로 오퍼레이션)을 캐시하는 OP 캐시가 추가되고 있다. x86 프로세서의 강력함은 x86 명령에 있지만 복잡하고 장기간에 걸쳐 확장이 진행된 x86 명령 디코딩 자체가 프로세서를 짓누르는 전력 소모의 근원이자 퍼포먼스에 직결되는 부문이기 때문에 x86 CPU의 성능을 결정짓는 핵심적인 요소가 되고 있다. 과거 인텔은 이러한 문제를 해결하기 위해 샌디브릿지 아키텍처에 uOP 캐시(uOP Cache)를 도입했다. 인텔의 uOP 캐시는 트레이스(추적)을 생성하지 않고, L1 명령 캐시와 같이 주소 기준으로 확인하는 16byte 명령 페치 라인을 2개 연결하여 32byte의 마이크로 오퍼레이션을 uOP 캐시 라인에 격납하는 형태다. 인텔의 uOP와 같이 AMD 젠의 OP 캐시는 비슷한 맥락으로 보이지만 트레이스 캐시적인 구조는 아닌 것으로 보이며 L1 명령 캐시와 OP 캐시는 분리된 캐시로써 OP 캐시는 전용 캐시 태그를 갖추며 마이크로 태그(Micro-tags)로 L1 명령 캐시 및 OP 캐시 중 히트한 방향을 확인한다.
일반적인 x86 프로세서의 마이크로 오퍼레이션은 명령 디코딩시 CISC(Complex Instruction Set Computer)의 복합 명령을 내부적으로 RISC(Reduced Instruction Set Computer)형태와 같은 단순 분리된 마이크로 오퍼레이션 명령으로 변환하여 실행한다. 그러나 현행의 x86 프로세서는 CISC의 복합 명령을 어느 정도 유지한 채 In-Order 구간에서 전체적으로 핸들링하여 실제로 처리가 진행되는 Out-of-Order 구간에서 단순한 마이크로 오퍼레이션으로 변환되고 있다. 젠 아키텍처의 명령 디코딩은 복합 마이크로 오퍼레이션 Macro-OP, 단순 분리된 마이크로 오퍼레이션의 2단계 구성이다. 이러한 2단계 구성은 x86, x64 명령을 1:1 고밀도 마이크로 오퍼레이션으로 변환하는 형태이며 젠 아키텍처의 명령 디코더는 디스패치까지 전체적으로 확장되는 형태로 보인다. 주로 명령 디코더가 디코딩을 진행 하지만 어느 정도의 디코딩은 마이크로 오퍼레이션 큐의 후단에도 발생한다. 여기서 OP 캐시가 적용됐기 때문에 마이크로 오퍼레이션 큐에 저장된 OP는 상당히 고밀도이며 그것이 처리되는 단계에서는 보다 전통적인 마이크로 오퍼레이션으로 전개된다.
젠 아키텍처는 인텔의 uOP 캐시와 흡사한 OP 캐시를 도입했지만 명령 디코딩의 플로우는 인텔과 다르다. 이전 불도저 아키텍처의 명령 디코딩은 하나의 OP로 변환되는 패스트 패스 싱글(Fast Path Single), 2개의 OP로 변환되는 패스트 패스 더블(Fast Path Double), 그 이상의 OP로 변환되는 마이크로 코드(Microcode) 3가지 디코딩 타입이 적용됐으나 젠 아키텍처는 명령 디코더에서 명령 바운드리을 검색하여 x86, x64 명령을 분리하고, 마이크로 오퍼레이션으로 변환한 뒤 마이크로 오퍼레이션 큐로 전송한다. 이때의 마이크로 오퍼레이션은 매우 고밀도로써 AMD가 패스트 패스 더블이라고 부르는 명령도 하나의 고밀도 마이크로 오퍼레이션이 되고 있기 때문에 처리 스테이지까지 그대로인 형태다.
이것은 기존 불도저 아키텍처의 패스트 패스 더블 형태를 젠 아키텍처는 x86 명령을 분리하지 않고, 하나의 내부 명령으로 매핑하는 고밀도 마이크로 오퍼레이션으로 처리한다는 것을 의미한다. 불도저 아키텍처는 매우 복잡한 x86 명령은 마이크로 코드 ROM에서 마이크로 오퍼레이션으로 전개하며 2개까지의 마이크로 오퍼레이션으로 변환되는 명령은 일반적인 병렬 디코더, 3개 이상의 마이크로 오퍼레이션으로 변환되는 명령은 마이크로 코드 순으로 이어지며 디코딩 단계에서 마이크로 코드 엔진에서 3개 이상의 마이크로 오퍼레이션으로 변환된다.
여기서 젠 아키텍처는 복잡한 구간을 마이크로 코드 ROM 주소를 저장한 뒤 고밀도 마이크로 오퍼레이션으로 변환하고, 마이크로 오퍼레이션 큐에 기록한다. 마이크로 코드 ROM의 마이크로 오퍼레이션은 큐에는 저장되지 않지만 마이크로 코드 ROM의 주소를 매핑하여 고밀도 마이크로 오퍼레이션을 마지막 단계까지 전개하지 않고, ROM이 필요한 마이크로 오퍼레이션은 디스패치의 타이밍에 맞게 설정된 Kicking Sequence에서 마이크로 코드 ROM으로 보낸다.
AMD는 불도저 아키텍처에서 비교형 명령과 점프 명령을 융합시킨 브랜치 퓨전을 도입했다. 이는 연계성이 있는 2개의 명령을 조합하여 하나의 마이크로 오퍼레이션으로 하나의 실행 파이프에서 실행한다. 명령 수를 줄인다는 의미에서는 최초 명령 디코더 단계부터 퓨전을 하는 것이 효율적으로 보이지만 젠 아키텍처는 처리 단계에서 퓨전을 진행하고 있다. 디코더에서 연계성이 있는 2개의 마이크로 오퍼레이션이 처리 단계에서 하나의 마이크로 오퍼레이션으로 퓨전되는 것으로 처리 단계에서 디스패치는 6개의 마이크로 오퍼레이션을 상한으로 퓨전하여 하나로 만든다.
따라서 젠 아키텍처의 명령 디코딩 스테이지는 x86 명령을 CISC적인 특성을 어느 정도 유치한 채 고밀도 마이크로 오퍼레이션으로 분리하고 정리한다. 이후 마이크로 오퍼레이션을 저장한 OP 캐시를 OP 큐가 취급하고 Out-of-Order 단계에서 한번에 마이크로 오퍼레이션으로 전개하며 이것은 처리 후단에서 진행하는 것으로 보인다. 복합 명령을 1:1로 하나의 고밀도 마이크로 오퍼레이션으로 변환하는 형태로써 일정량으로 정해져있는 작은 OP 캐시에 최대한의 마이크로 오퍼레이션을 저장할 수 있는 최적화를 도모하고 있는 것으로써 젠 아키텍처의 전체적인 명령 디코딩 플로우는 새롭게 도입된 OP 캐시에 초점을 맞춰 설계했다고 볼 수 있다.
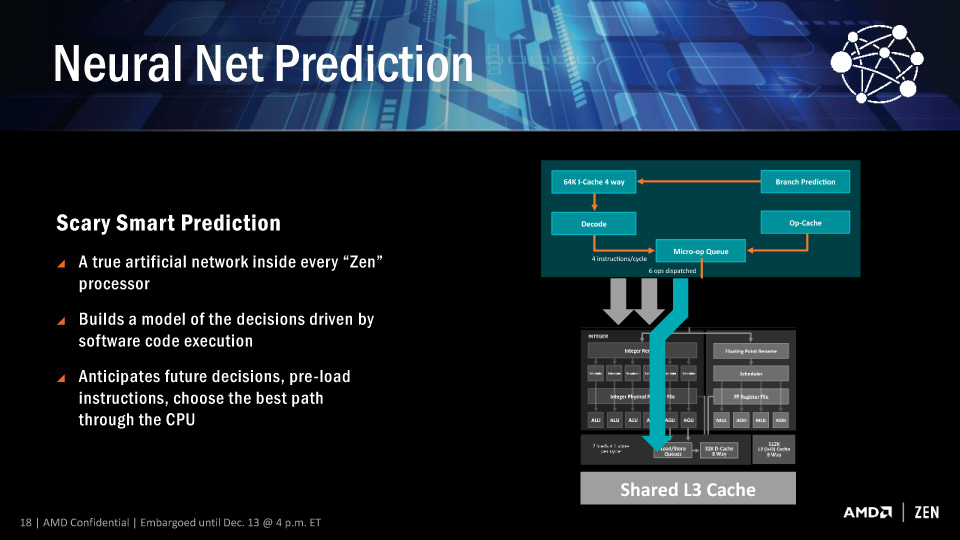
젠 아키텍처는 새로운 뉴럴 네트워크 분기 예측 기술이 탑재되고 있다. 이 기술은 소니 플레이스테이션과 같은 콘솔 시장을 타겟으로 하는 AMD의 기존 재규어(Jaguar)에도 탑재되고 있는 기술이지만 AMD는 이에 대한 세부적인 알고리즘을 공개하지 않았다. 분기 예측은 말 그대로 분기를 예측하는 것으로써 정확도가 높을수록 파이프 라인은 손실을 줄이고 효율적인 처리가 가능하기 때문에 전력 효율 감소로 이어지는 중요할 기술이다. 젠 아키텍처의 Branch Target Buffer(BTB)는 L1명령 캐시와 통합된 연관성이 있으며 1엔트리에 2브랜치를 1사이클에 예측, 브랜치 히스토리 테이블(Branch History Table)의 사이즈를 2배로 증가시켰다는 점만 확인할 수 있다.
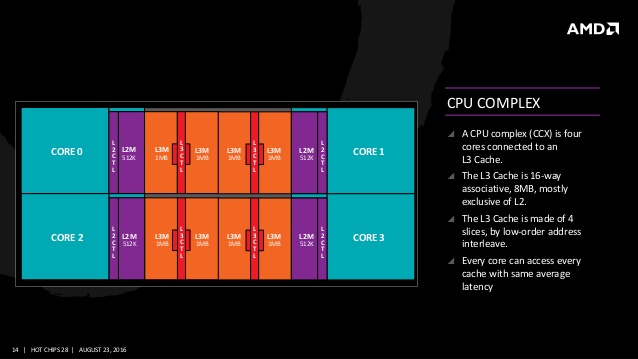
전체적인 코어 디자인은 새로운 CCX(Core Complex)로 설계되고 있다. CCX는 4개의 물리 코어가 하나의 구성(1CCX)을 이루는 형태로 각각의 코어는 8MB L3 캐시를 공유한다. 캐시 계층은 L3 캐시가 L2에 대한 익스클러시브 방식으로 L2 캐시 데이터는 L3 캐시에 존재하지 않고, 캐시 스누프에서 L3가 미스한 경우 각 CPU 코어의 L2 캐시도 스누프한다. 또한 스누프 트래픽을 경감하기 위한 L2 캐시 태그의 사본을 L3에 저장한다.
CCX는 회로 설계도 강화되고 있다. 디지털 LDO(Low Drop-Out)에 의한 전압 제어는 VRM에서 CPU 코어의 가장 높은 VID로 입력된 코어 전압인 RVDD를 각 코어별로 VDD에 흡수하여 부하에 맞춰 최적의 전압과 주파수로 조정하며 1300개 이상의 크리티컬 패스 모니터와 파워 서플라이 모니터, 서멀 다이오드, 루프 디텍더 등을 배치하여 전압의 변동이나 다이 온도 상승, 크리티컬 패스의 딜레이 등을 세부적으로 확인하여 최적의 동작 주파수를 검증하고, AVFS(Adaptive Frequency and Voltage Scaling)는 보다 디테일 한 25MHz 단위로 주파수를 조정, 구동 전압도 각 코어 단위로 개별적으로 제어하며 전압 제어를 위해 배선층에 다수의 MIMCap를 심고 있다. 이 기술들은 젠 아키텍처의 XFR(Xtended Frequency Range) 기술로 이어져 프로세서의 쿨링 상황에 따라 보장된 터보 클럭 이상의 클럭으로 동작하는 기능도 제공한다.

젠 아키텍처는 이러한 CCX가 2개로 구성된 2CCX 설계로 각각의 CCX는 새로운 인터커넥트 기술인 인피니티 패브릭(Infinity Fabric)으로 연결된다. 인피니티 패브릭은 데이터 전송을 위한 Infinity Scalable Data Fabric(SDF)와 제어 신호를 전달하는 Infinity Scalable Control Fabric(SCF)의 2계통으로써 의미대로 SDF가 데이터 제어, SCF가 앞서 설명한 다양한 CCX 내부 센서 외 클럭, 전원, 초기화, 보안 등의 다양한 제어 신호를 총괄한다. AMD는 인피니피 패브릭을 젠 아키텍처 뿐 만 아니라 향후 개발되는 프로세서, GPU, 서버, 모바일 등의 제품군에 공통으로 사용한다고 밝혔다. 이것은 새로운 제품 개발에 각각 별도의 인터커넥트 기술을 개발하지 않고, 일관된 IP를 사용함으로써 제품 개발에 소요되는 시간과 노력, 비용 등을 절감하기 위함이다.
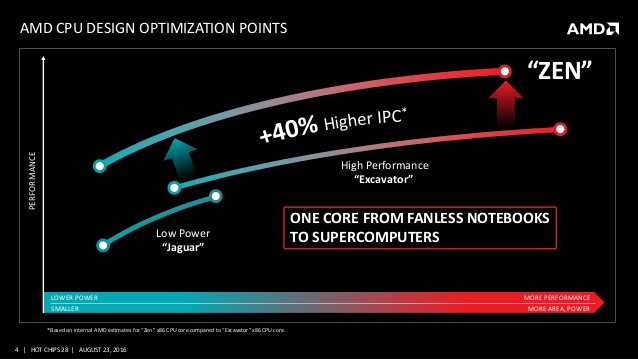
지금까지 살펴 본 AMD의 젠 마이크로 아키텍처는 불도저 아키텍처와 달리 근본부터 재설계한 완전히 새로운 아키텍처임을 다시 한번 확인할 수 있었다. 전체적인 아키텍처 디자인은 AMD 만의 차별성도 있으나 인텔 아키텍처를 닮아가고 있는 인상을 주고 있으며 그에 따른 퍼포먼스는 이전 프로세서 대비 40% 향상된 IPC로 인텔의 턱밑까지 추격하는데 성공하여 소비자들에게 다양한 시스템을 구성할 수 있는 선택의 폭을 넓혀주고 있다.
AMD 젠 아키텍처 성능 - http://raptor-hw.net/xe/benchmark